Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Recupero di dati esterni per un PDP in OPA
Per OPA, se tutti i dati necessari per una decisione di autorizzazione possono essere forniti come input o come parte di un JSON Web Token (JWT) passato come componente della query, non è richiesta alcuna configurazione aggiuntiva. (È relativamente semplice passare JWTs dati contestuali SaaS a OPA come parte dell'input delle query.) OPA può accettare input JSON arbitrari in quello che viene chiamato approccio di input in caso di sovraccarico. Se un PDP richiede dati oltre a quelli che possono essere inclusi come input o un JWT, OPA offre diverse opzioni per recuperare questi dati. Queste includono il raggruppamento, l'invio di dati (replica) e il recupero dinamico dei dati.
Raggruppamento OPA
La funzionalità di raggruppamento OPA supporta il seguente processo per il recupero dei dati esterni:
-
Il Policy Enforcement Point (PEP) richiede una decisione di autorizzazione.
-
OPA scarica nuovi pacchetti di policy, inclusi dati esterni.
-
Il servizio di raggruppamento replica i dati dalle fonti di dati.
Quando si utilizza la funzionalità di raggruppamento, OPA scarica periodicamente policy e pacchetti di dati da un servizio di bundle centralizzato. (OPA non fornisce l'implementazione e la configurazione di un servizio bundle.) Tutte le politiche e i dati esterni estratti dal servizio bundle vengono archiviati in memoria. Questa opzione non funziona se la dimensione dei dati esterni è troppo grande per essere archiviata in memoria o se i dati vengono modificati troppo frequentemente.
Per ulteriori informazioni sulla funzionalità di raggruppamento, consulta la documentazione OPA
Replica OPA (invio di dati)
L'approccio di replica OPA supporta il seguente processo per il recupero dei dati esterni:
-
Il PEP richiede una decisione di autorizzazione.
-
Il replicatore di dati invia i dati all'OPA.
-
Il replicatore di dati replica i dati dalle fonti di dati.
In questa alternativa all'approccio basato sul raggruppamento, i dati vengono trasferiti all'OPA anziché essere raccolti periodicamente dall'OPA. (OPA non fornisce l'implementazione e la configurazione di un replicatore). L'approccio push presenta gli stessi limiti di dimensione dei dati dell'approccio raggruppato, poiché OPA archivia tutti i dati in memoria. Il vantaggio principale dell'opzione push è che è possibile aggiornare i dati in OPA con delta anziché sostituire tutti i dati esterni ogni volta. Ciò rende l'opzione push più appropriata per i set di dati che cambiano frequentemente.
Per ulteriori informazioni sull'opzione di replica, consultate la documentazione OPA
Recupero dinamico dei dati OPA
Se i dati esterni da recuperare sono troppo grandi per essere memorizzati nella memoria dell'OPA, i dati possono essere estratti dinamicamente da una fonte esterna durante la valutazione di una decisione di autorizzazione. Quando si utilizza questo approccio, i dati sono sempre aggiornati. Questo approccio presenta due inconvenienti: latenza di rete e accessibilità. Attualmente, OPA può recuperare i dati in fase di esecuzione solo tramite una richiesta HTTP. Se le chiamate che vanno a un'origine dati esterna non possono restituire dati come risposta HTTP, richiedono un'API personalizzata o qualche altro meccanismo per fornire questi dati a OPA. Poiché OPA può recuperare i dati solo tramite richieste HTTP e la velocità di recupero dei dati è fondamentale, ti consigliamo di utilizzare un servizio come Servizio AWS Amazon DynamoDB per conservare dati esterni quando possibile.
Per ulteriori informazioni sull'approccio pull, consulta la documentazione OPA.
Utilizzo di un servizio di autorizzazione per l'implementazione con OPA
Quando si recuperano dati esterni utilizzando il raggruppamento, la replica o un approccio di pull dinamico, si consiglia che il servizio di autorizzazione faciliti questa interazione. Questo perché il servizio di autorizzazione può recuperare dati esterni e trasformarli in JSON per consentire a OPA di prendere decisioni di autorizzazione. Il diagramma seguente mostra come un servizio di autorizzazione può funzionare con questi tre approcci esterni per il recupero dei dati.
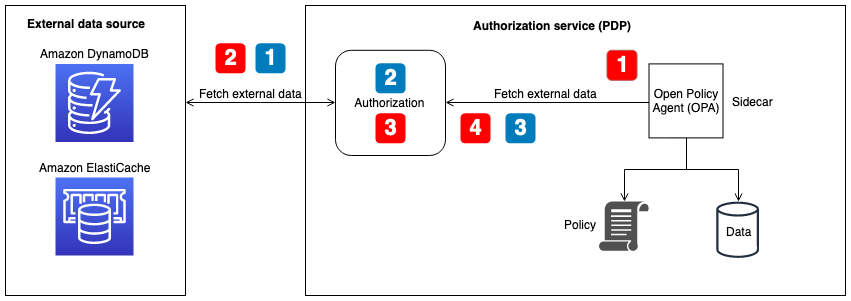
Recupero di dati esterni per il flusso OPA: recupero unificato o dinamico dei dati al momento della decisione (illustrato con callout numerati in rosso nel diagramma):
-
L'OPA chiama l'endpoint dell'API locale per il servizio di autorizzazione, che è configurato come endpoint in bundle o come endpoint per il recupero dinamico dei dati durante le decisioni di autorizzazione.
-
Il servizio di autorizzazione interroga o chiama l'origine dati esterna per recuperare dati esterni. (Per un endpoint integrato, questi dati devono contenere anche le politiche e le regole OPA. Gli aggiornamenti in bundle sostituiscono tutto, sia i dati che le policy, nella cache di OPA.)
-
Il servizio di autorizzazione esegue qualsiasi trasformazione necessaria sui dati restituiti per trasformarli nell'input JSON previsto.
-
I dati vengono restituiti all'OPA. Viene memorizzato nella cache per la configurazione del pacchetto e utilizzato immediatamente per decisioni di autorizzazione dinamiche.
Recupero di dati esterni per OPA flow — replicator (illustrato con callout numerati in blu nel diagramma):
-
Il replicatore (parte del servizio di autorizzazione) richiama l'origine dati esterna e recupera tutti i dati da aggiornare in OPA. Ciò può includere politiche, regole e dati esterni. Questa chiamata può avere una cadenza prestabilita oppure può avvenire in risposta agli aggiornamenti dei dati nella fonte esterna.
-
Il servizio di autorizzazione esegue tutte le trasformazioni necessarie sui dati restituiti per trasformarli nell'input JSON previsto.
-
Il servizio di autorizzazione chiama OPA e memorizza i dati nella cache. Il servizio di autorizzazione può aggiornare selettivamente dati, politiche e regole.
