Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo dei suggerimenti di unione in Spark SQL
Con Spark 3.0, puoi specificare il tipo di algoritmo di join che desideri Spark da usare in fase di esecuzione. La strategia di unione suggerisce, BROADCASTMERGE, e SHUFFLE_HASHSHUFFLE_REPLICATE_NL, istruisce Spark per utilizzare la strategia suggerita su ogni relazione specificata quando la si unisce a un'altra relazione. Questa sezione illustra in dettaglio i suggerimenti sulla strategia di unione.
TRASMISSIONE
In un Broadcast Hash join, uno dei set di dati è significativamente più piccolo dell'altro. Poiché il set di dati più piccolo può stare in memoria, viene trasmesso a tutti gli executor del cluster. Dopo la trasmissione dei dati, viene eseguito un hash join standard. Un Broadcast Hash Join avviene in due fasi:
-
Trasmissione: il set di dati più piccolo viene trasmesso a tutti gli esecutori all'interno del cluster.
-
Hash join: il set di dati più piccolo viene sottoposto a hashing su tutti gli executor e quindi unito al set di dati più grande.
Non è presente alcuna operazione. sort merge Quando si uniscono tabelle di fatti di grandi dimensioni con tabelle di dimensioni più piccole utilizzate per eseguire un join con schema a stella, Broadcast Hash è l'algoritmo di join più veloce. L'esempio seguente dimostra come funziona un join Broadcast Hash. Il lato di unione con il suggerimento viene trasmesso, indipendentemente dal limite di dimensione specificato nella proprietà. spark.sql.autoBroadcastJoinThreshold Se entrambi i lati del join hanno suggerimenti di trasmissione, viene trasmesso quello con la dimensione più piccola (in base alle statistiche). Il valore predefinito per la spark.sql.autoBroadcastJoinThreshold proprietà è 10 MB. Ciò configura la dimensione massima, in byte, per una tabella che viene trasmessa a tutti i nodi di lavoro durante l'esecuzione di un join.
Gli esempi seguenti forniscono la query, il EXPLAIN piano fisico e il tempo impiegato per l'esecuzione della query. La query richiede meno tempo di elaborazione se si utilizza il BROADCASTJOIN hint per forzare un join di trasmissione, come mostrato nel secondo EXPLAIN piano di esempio.
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
Lo Shuffle Sort Merge join è preferito quando entrambi i set di dati sono di grandi dimensioni e non possono entrare nella memoria. Come indica il nome, questo join prevede le seguenti tre fasi:
-
Fase di shuffle: entrambi i set di dati nella join query vengono mescolati.
-
Fase di ordinamento: i record vengono ordinati tramite la chiave di unione su entrambi i lati.
-
Fase di unione: entrambi i lati della condizione di unione vengono iterati, in base alla chiave di unione.
L'immagine seguente mostra una visualizzazione del Directed Acyclic Graph (DAG) di un join Shuffle Sort Merge. Entrambe le tabelle vengono lette nelle prime due fasi. Nella fase successiva (fase 17), vengono mescolate, ordinate e poi unite insieme alla fine.
Nota: alcune fasi di questa immagine appaiono come saltate perché erano state completate nelle fasi precedenti. Tali dati sono stati memorizzati nella cache o conservati per essere utilizzati in queste fasi. |
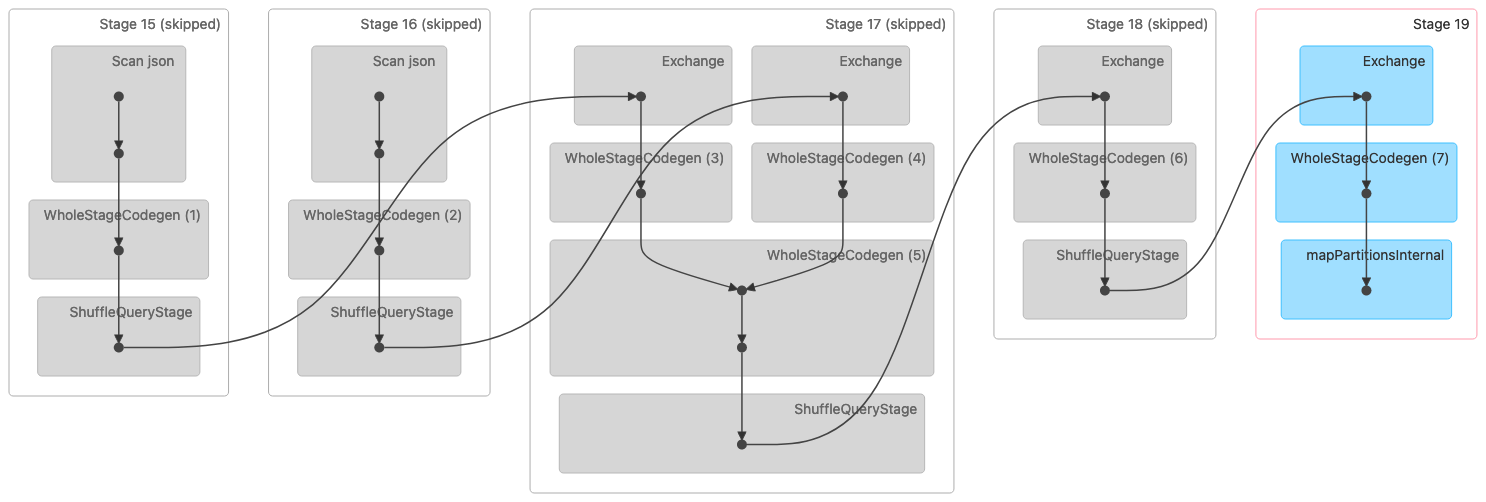
Di seguito è riportato un piano fisico che indica un join Sort Merge.
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
Lo Shuffle Hash join, come indica il nome, funziona mescolando entrambi i set di dati. Le stesse chiavi da entrambi i lati finiscono nella stessa partizione o attività. Dopo aver mescolato i dati, il più piccolo dei due set di dati viene inserito in bucket, quindi viene eseguito un hash join all'interno della partizione. Un join Shuffle Hash è diverso da un join Broadcast Hash perché l'intero set di dati non viene trasmesso. Un join Shuffle Hash è suddiviso in due fasi:
-
Fase Shuffle: entrambi i set di dati vengono mescolati.
-
Fase di hash join: la parte più piccola dei dati viene sottoposta a hash, inserita in bucket e quindi unita all'hash con la parte più grande in tutte le partizioni.
L'ordinamento non è necessario con i join Shuffle Hash all'interno delle partizioni. L'immagine seguente mostra le fasi del join Shuffle Hash. I dati vengono letti inizialmente, quindi vengono mescolati e quindi viene creato e utilizzato un hash per il join.

Per impostazione predefinita, l'ottimizzatore sceglie Shuffle Hash join quando non è possibile utilizzare il join Broadcast Hash. In base alla soglia di join Broadcast Hash (spark.sql.autoBroadcastJoinThreshold) e al numero di partizioni shuffle (spark.sql.shuffle.partitions) scelte, utilizza lo Shuffle Hash join quando la singola partizione dell'SQL logico è sufficientemente piccola da creare una tabella hash locale.
SHUFFLE_REPLICATE_NL
Il join Shuffle-and-Replicate Nested Loop, noto anche come Cartesian Product join, funziona in modo molto simile a un join Broadcast Hash, tranne per il fatto che il set di dati non viene trasmesso.
In questo algoritmo di join, shuffle non si riferisce a un vero shuffle perché i record con le stesse chiavi non vengono inviati alla stessa partizione. Invece, l'intera partizione di entrambi i set di dati viene copiata sulla rete. Quando le partizioni dei set di dati sono disponibili, viene eseguito un Nested Loop join. Se sono presenti un X numero di record nel primo set di dati e un Y numero di record nel secondo set di dati in ogni partizione, ogni record del secondo set di dati viene unito a tutti i record del primo set di dati. Questo continua a ripetersi in ogni partizione. X × Y
