Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Opzioni di ripristino
Le seguenti sezioni forniscono due opzioni di ripristino del database per SQL Server su Amazon Elastic Compute Cloud (Amazon EC2), quando i backup sono locali.
Uso di Amazon S3
Questo approccio di ripristino del database SQL Server utilizza i comandi Amazon Simple Storage Service (Amazon S3) per AWS CLI() o AWS Command Line Interface l'API Amazon S3 per caricare i file di backup direttamente in un bucket S3.
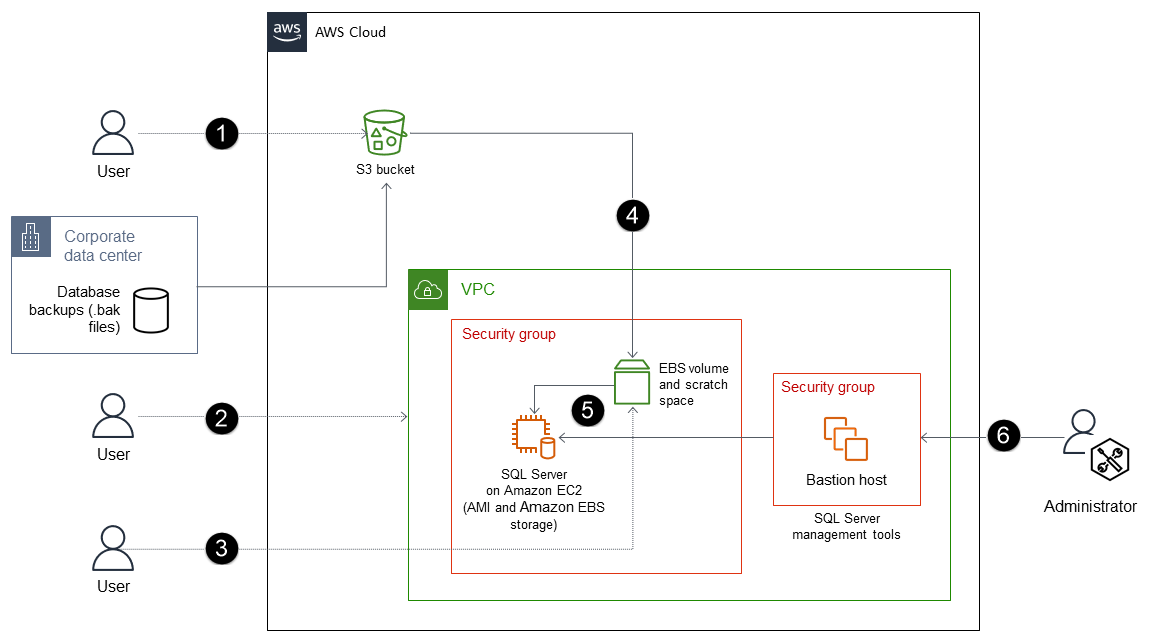
Il processo prevede i seguenti passaggi:
-
Crea un bucket S3 (o usa un bucket esistente) per archiviare i file di backup e trasferisci i file di backup (.bak) dal database locale al bucket S3 utilizzando la CLI o l'API Amazon S3. AWS
-
Distribuisci SQL Server su un' EC2 istanza ottimizzata per EBS, utilizzando un'Amazon Machine Image (AMI) di SQL Server. Questo AMI deve contenere volumi EBS configurati con una partizione del sistema operativo, una partizione DATA, una partizione LOG, uno storage tempdb (NVMe) e uno spazio scratch.
-
(Facoltativo) Collegate un volume EBS non root all'istanza. EC2
-
Copia i file di backup nel volume EBS non root.
-
Ripristina i file di backup dal volume EBS a SQL Server sull'istanza. EC2
-
Usa gli strumenti di gestione di SQL Server per gestire il tuo database.
Utilizzo AWS DataSync e Amazon FSx
Questo approccio di ripristino del database di SQL Server utilizza AWS DataSync il trasferimento dei file di backup su Amazon FSx for Windows File Server.
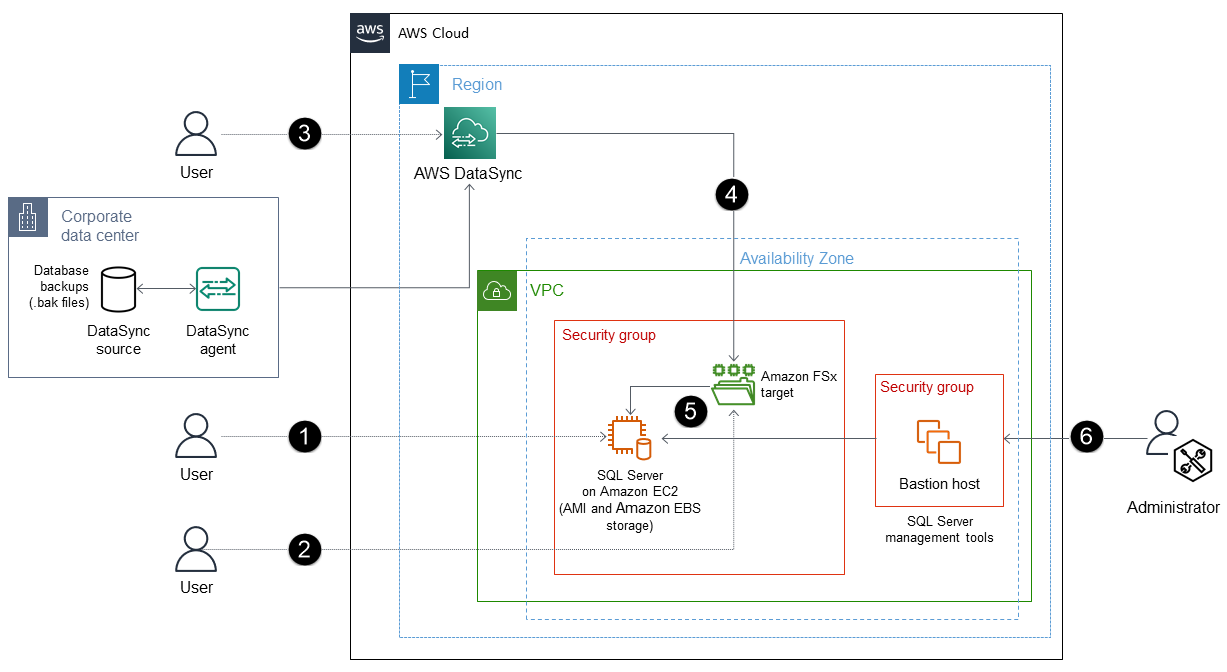
Il processo prevede i seguenti passaggi:
-
Distribuisci SQL Server su un' EC2 istanza ottimizzata per EBS con allegato NVMe, utilizzando un'AMI che contiene volumi EBS configurati con OS, DATA, LOG e tempdb. (Ad esempio, puoi utilizzare la classe di istanza ottimizzata per la memoria.)
r5d.large -
Utilizzare FSx per Windows File Server per creare un file server. Può essere utilizzato come posizione di archiviazione temporanea per scaricare i file di backup di SQL Server (.bak) dall'ambiente locale.
-
Crea un DataSync endpoint e un agente per il FSx file server Amazon.
-
DataSync automatizza la sincronizzazione dei dati tra lo storage locale e il FSx file server Amazon senza richiedere Amazon S3.
-
Ripristina i file di backup dal FSx file server Amazon a SQL Server sull' EC2istanza.
-
Usa gli strumenti di gestione di SQL Server per gestire il tuo database.
Nota
Amazon EC2 offre Microsoft SQL Server su Microsoft Windows Server AMIs
Utilizzo di Amazon S3 File Gateway
Puoi utilizzare Amazon S3 File Gateway
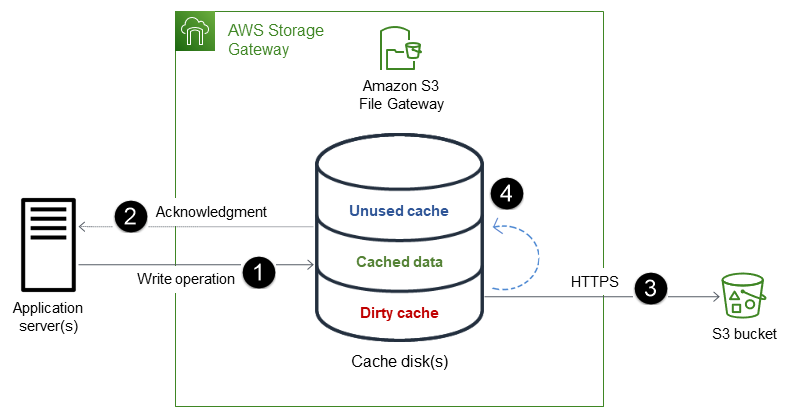
Il processo prevede i seguenti passaggi:
-
I dati vengono scritti sul disco di cache locale del gateway di file.
-
Dopo che i dati sono stati salvati in modo sicuro nella cache locale, il file gateway conferma il completamento dell'operazione di scrittura nell'applicazione client.
-
Il file gateway trasferisce i dati al bucket S3 in modo asincrono. Ottimizza il trasferimento dei dati e utilizza HTTPS per crittografare i dati in transito.
-
Una volta caricati nel bucket S3, i dati rimangono nella cache locale del file gateway fino a quando non vengono eliminati.
