Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esempio di implementazione di una moderna strategia di dati sanitari
AWS fornisce architetture di riferimento che le organizzazioni sanitarie possono utilizzare per comprendere e creare piattaforme di dati che supportano un approccio agile ai dati. La seguente architettura di riferimento illustra un'architettura data mesh
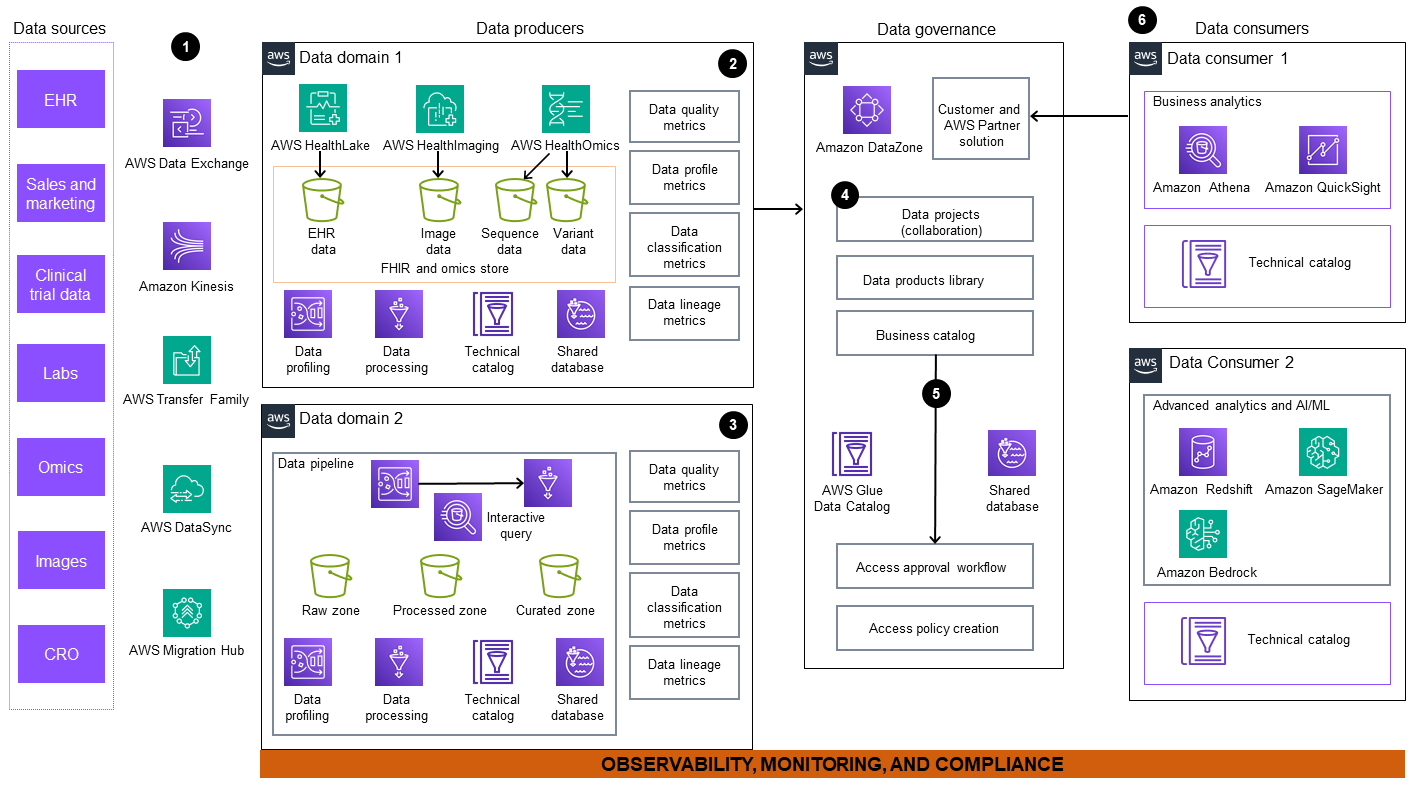
Il diagramma di architettura include i seguenti componenti:
-
I dati vengono importati da fonti di dati esterne e interne. Queste fonti includono, ma non sono limitate a, sistemi di Electronic Health Record (EHR), laboratori, strutture di sequenziamento e centri di imaging. AWS offre una suite di servizi come AWS Data Exchange
Amazon Kinesis ,,, AWS Transfer FamilyAWS DataSyncAWS Migration HubAWS HealthLake , e AWS Glue (ETL). Puoi utilizzare questi servizi per facilitare la migrazione del set di dati interno e per abbonarti a set di dati interni ed esterni. -
Data domain 1 include un flusso di lavoro completo per l'elaborazione di dati multimodali orientati al paziente, inclusi dati clinici, omici e di imaging. I dati clinici EHR vengono inseriti e archiviati in un HealthLake data store, un servizio gestito appositamente progettato per i dati clinici. AWS HealthOmics
, un servizio appositamente progettato per i dati omici, gestisce l'archivio di sequenze e varianti e il flusso di lavoro. I dati di imaging vengono acquisiti e archiviati in. AWS HealthImaging Questi dati vengono quindi trasformati in prodotti pronti per il consumo e pubblicati in un marketplace di dati aziendali per un'ampia accessibilità e utilizzo. -
In data domain 2, Amazon Kinesis AWS Glue, e AWS Data Exchange inserisci dati grezzi in una pipeline di dati. Le fonti per i dati possono includere registri pubblici, monitoraggio remoto dei pazienti e programmi di Enterprise Resource Planning (ERP). La pipeline carica i dati grezzi nei bucket Amazon Simple Storage Service (Amazon S3)
. Questi dati vengono puliti, curati, trasformati e archiviati per la pubblicazione come prodotto di dati. Amazon Athena offre un motore di query interattivo che i produttori di dati possono utilizzare per trasformare i dati tramite SQL. AWS Glue DataBrew fornisce funzionalità visive di trasformazione, normalizzazione e profilazione dei dati. -
Amazon DataZone
gestisce la pubblicazione di metadati, progetti di dati collaborativi e della libreria di prodotti di dati nel catalogo aziendale centrale. -
Un portale unificato di analisi dei dati consente la collaborazione sui dati fornendo una visualizzazione dei prodotti di dati attraverso una governance federata. Amazon DataZone abilita un flusso di lavoro self-service con AWS Glue Data Catalog backup by AWS Lake Formation, in modo che gli utenti possano condividere, cercare, scoprire dati e richiedere l'autorizzazione per il consumo.
-
I consumatori di dati possono accedere ai dati, creare viste downstream e utilizzare strumenti appositamente progettati come Amazon Athena, Amazon, Amazon Redshift
, Amazon AI e QuickSight Amazon Bedrock per effettuare le seguenti SageMaker operazioni : -
Analisi operativa
-
Informatica clinica
-
Ricerca
-
Coinvolgimento clinico e del paziente
I consumatori di dati possono anche sviluppare applicazioni innovative utilizzando l'intelligenza artificiale generativa e possono pubblicare prodotti di dati nel catalogo aziendale.
-
Per ulteriori informazioni sull'architettura Data Mesh, consulta Cos'è una Data Mesh
AI generativa
Le organizzazioni sanitarie utilizzano l'intelligenza artificiale generativa per una serie di applicazioni, dall'automazione dell'interpretazione delle immagini mediche alla generazione di raccomandazioni diagnostiche e piani di trattamento basati su immagini e dati testuali. L'adozione dell'IA generativa sta accelerando l'innovazione e migliorando l'efficienza in tutto il continuum assistenziale. La nuova attenzione all'intelligenza artificiale generativa ha costretto l'assistenza sanitaria a espandere la propria attenzione ai dati per includere più forme di dati non strutturati, ampliando il numero e la varietà di casi d'uso riconducibili all'IA. In generale, le organizzazioni possono scegliere tra quattro modelli, a seconda del caso d'uso, per implementare soluzioni di intelligenza artificiale generativa:
-
Progettazione tempestiva: nella progettazione tempestiva, gli utenti forniscono i dati pertinenti come contesto, guidando il modello di intelligenza artificiale generativa a creare i contenuti desiderati. Organizations con una moderna strategia di gestione dei dati sanitari possono garantire che i dati pertinenti siano facilmente individuabili, condivisibili e utilizzabili.
-
Retrieval Augmented Generation (RAG): il modello RAG si basa su una progettazione tempestiva. Invece di essere un utente a fornire dati pertinenti, un programma intercetta la domanda o l'input dell'utente. Il programma esegue una ricerca in un archivio di dati per recuperare il contenuto pertinente alla domanda o all'input. Il programma invia i dati che trova al modello di intelligenza artificiale generativa per generare contenuti. Una moderna strategia di gestione dei dati sanitari consente la cura e l'indicizzazione dei dati aziendali. I dati possono quindi essere ricercati e utilizzati come contesto per richieste o domande, aiutando un modello linguistico di grandi dimensioni (LLM) a generare risposte.
L'organizzazione può utilizzare i due modelli seguenti per concentrare i risultati del modello di intelligenza artificiale generativa sulla generazione di contenuti appropriati al contesto dei propri dati.
-
Ottimizzazione: utilizzando questo modello, l'organizzazione può fare un ulteriore passo avanti personalizzando i modelli di intelligenza artificiale generativa. Ciò comporta la messa a punto dei modelli su un piccolo campione di dati specifici dell'organizzazione. Poiché la dimensione del campione è ridotta, questo modello fornisce un equilibrio tra costi e personalizzazione. Per evitare distorsioni negli output del modello, utilizzate un piccolo set di dati di esempio che sia il più possibile diversificato e rappresentativo dei modelli di dati dell'organizzazione. Una moderna strategia di dati sanitari supporta l'accesso efficiente a un'ampia varietà di dati per preparare i set di dati di esempio.
-
Crea il tuo modello: se la tua organizzazione ha bisogno di generare contenuti su grandi volumi di dati altamente specializzati e se i tre modelli precedenti non sono adeguati, puoi creare modelli personalizzati.
Una moderna strategia di dati svolge un ruolo fondamentale nelle soluzioni di intelligenza artificiale generativa, contribuendo a garantire che i dati abbiano le seguenti caratteristiche:
-
Dati di alta qualità a supporto della precisione
-
Dati in tempo reale o quasi in tempo reale per garantire che gli output del modello siano pertinenti
-
Molteplici modalità di dati su una varietà di fonti di dati per fornire al modello l'accesso a set di dati arricchiti per la generazione di contenuti
Il diagramma seguente mostra l'implementazione di una moderna strategia di dati sanitari che utilizza un'architettura data mesh per supportare soluzioni di intelligenza artificiale generativa.
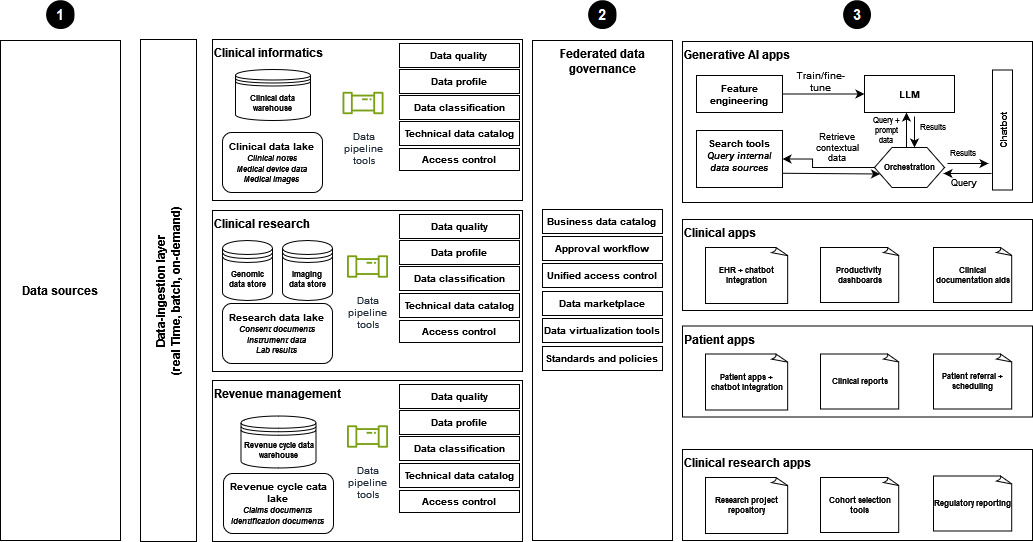
-
I dati vengono acquisiti da diverse fonti di dati nei settori dell'informatica clinica, della ricerca clinica e della gestione delle entrate e vengono messi a disposizione dell'organizzazione sanitaria.
-
La governance dei dati federata aiuta a garantire un controllo rigoroso degli accessi per la condivisione dei dati e l'accesso unificato.
-
I consumatori di dati includono quanto segue:
-
Applicazioni di intelligenza artificiale generativa, in particolare quelle che utilizzano i dati per addestrare e LLMs perfezionare. Queste applicazioni utilizzano i dati aziendali per i chatbot di domande e risposte per migliorare l'efficienza operativa e le esperienze di pazienti e fornitori.
-
Applicazioni cliniche dotate di strumenti come chatbot integrati in EHR, dashboard di produttività e supporti alla documentazione.
-
Applicazioni incentrate sul paziente per migliorare l'esperienza dei pazienti. Queste applicazioni offrono interazioni con chatbot, report clinici e processi di riferimento e pianificazione efficienti.
-
Ricerca clinica, con un archivio di progetti di ricerca e applicazioni progettate per l'analisi di coorte e la rendicontazione normativa.
-
Con questa architettura, le parti interessate dell'organizzazione possono concentrarsi sulla cura e sulla gestione dei dati raccolti da altre fonti, rendendo al contempo i propri dati accessibili al resto dell'organizzazione. Possono utilizzare gli strumenti disponibili nel livello di governance dei dati federato per definire i metadati, gestire i flussi di lavoro di approvazione degli accessi e definire e applicare le politiche. Inoltre, il livello di governance dei dati federato fornisce il controllo centralizzato degli accessi. Questo crea un ambiente per la gestione di una varietà di fonti di dati e per l'aggiornamento di asset di dati di alta qualità con una frequenza specifica per mantenerne la pertinenza. AWS offre un set completo di funzionalità per soddisfare le esigenze di intelligenza artificiale generativa. Amazon Bedrock
