Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Architettura per un sistema di scansione web scalabile su AWS
Il seguente diagramma di architettura mostra un sistema di web crawler progettato per estrarre eticamente dati ambientali, sociali e di governance (ESG) dai siti Web. Si utilizza un Pythonun crawler basato su un crawler ottimizzato per l' AWS infrastruttura. Lo usi AWS Batch per orchestrare i processi di scansione su larga scala e usa Amazon Simple Storage Service (Amazon S3) per lo storage. Le applicazioni downstream possono importare e archiviare i dati dal bucket Amazon S3.
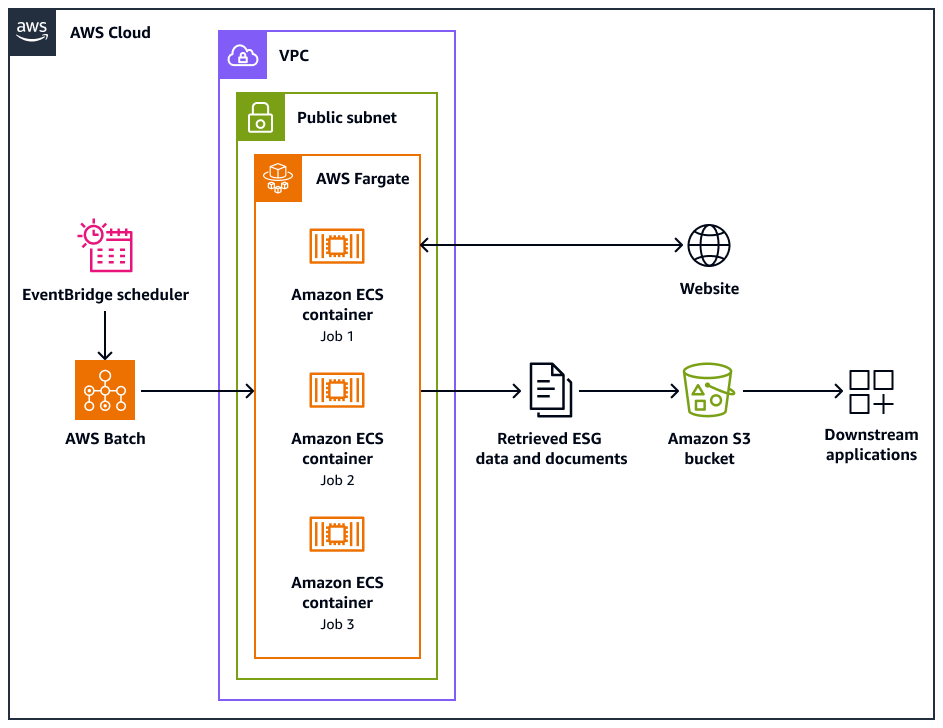
Il diagramma mostra il flusso di lavoro seguente:
-
Amazon EventBridge Scheduler avvia il processo di scansione a intervalli da te pianificati.
-
AWS Batch gestisce l'esecuzione dei processi del web crawler. La coda dei AWS Batch lavori contiene e orchestra i lavori di scansione in sospeso.
-
I processi di scansione Web vengono eseguiti nei contenitori Amazon Elastic Container Service (Amazon ECS) su. AWS Fargate I processi vengono eseguiti in una sottorete pubblica di un cloud privato virtuale (VPC).
-
Il web crawler esegue la scansione del sito Web di destinazione e recupera dati e documenti ESG, come PDF, CSV o altri file di documenti.
-
Il web crawler archivia i dati recuperati e i file raw in un bucket Amazon S3.
-
Altri sistemi o applicazioni acquisiscono o elaborano i dati e i file archiviati nel bucket Amazon S3.
Progettazione e funzionamento del web crawler
Alcuni siti Web sono progettati specificamente per essere eseguiti su desktop o dispositivi mobili. Il web crawler è progettato per supportare l'uso di un agente utente desktop o di un agente utente mobile. Questi agenti consentono di effettuare correttamente le richieste al sito Web di destinazione.
Dopo l'inizializzazione, il web crawler esegue le seguenti operazioni:
-
Il web crawler chiama il metodo.
setup()Questo metodo recupera e analizza il file robots.txt.Nota
Puoi anche configurare il web crawler per recuperare e analizzare la mappa del sito.
-
Il web crawler elabora il file robots.txt. Se nel file robots.txt viene specificato un ritardo di scansione, il web crawler estrae il ritardo di scansione per lo user agent desktop. Se nel file robots.txt non è specificato un ritardo di scansione, il web crawler utilizza un ritardo casuale.
-
Il web crawler chiama il
crawl()metodo, che avvia il processo di scansione. Se nessuno è presente URLs in coda, aggiunge l'URL iniziale.Nota
Il crawler continua fino a raggiungere il numero massimo di pagine o fino a esaurimento delle pagine da scansionare. URLs
-
Il crawler elabora il. URLs Per ogni URL nella coda, il crawler verifica se l'URL è già stato sottoposto a scansione.
-
Se un URL non è stato sottoposto a scansione, il crawler chiama il metodo nel modo seguente:
crawl_url()-
Il crawler controlla il file robots.txt per determinare se può utilizzare l'agente utente desktop per eseguire la scansione dell'URL.
-
Se consentito, il crawler tenta di eseguire la scansione dell'URL utilizzando l'agente utente desktop.
-
Se non è consentito o se l'agente utente desktop non riesce a eseguire la scansione per indicizzazione, il crawler controlla il file robots.txt per determinare se può utilizzare lo user agent mobile per eseguire la scansione dell'URL.
-
Se consentito, il crawler tenta di eseguire la scansione dell'URL utilizzando lo user agent mobile.
-
-
Il crawler richiama il
attempt_crawl()metodo, che recupera ed elabora il contenuto. Il crawler invia una richiesta GET all'URL con le intestazioni appropriate. Se la richiesta fallisce, il crawler utilizza la logica di riprova. -
Se il file è in formato HTML, il crawler chiama il metodo.
extract_esg_data()Utilizza Beautiful Soupper analizzare il contenuto HTML. Estrae dati ambientali, sociali e di governance (ESG) utilizzando la corrispondenza delle parole chiave. Se il file è un PDF, il crawler chiama il metodo.
save_pdf()Il crawler scarica e salva il file PDF nel bucket Amazon S3. -
Il crawler chiama il metodo.
extract_news_links()Questo consente di trovare e archiviare collegamenti ad articoli di notizie, comunicati stampa e post di blog. -
Il crawler chiama il
extract_pdf_links()metodo. Questo identifica e archivia i collegamenti ai documenti PDF. -
Il crawler chiama il metodo.
is_relevant_to_sustainable_finance()Questo verifica se le notizie o gli articoli sono correlati alla finanza sostenibile utilizzando parole chiave predefinite. -
Dopo ogni tentativo di scansione, il crawler implementa un ritardo utilizzando il metodo.
delay()Se è stato specificato un ritardo nel file robots.txt, utilizza tale valore. Altrimenti, utilizza un ritardo casuale compreso tra 1 e 3 secondi. -
Il crawler richiama il
save_esg_data()metodo per salvare i dati ESG in un file CSV. Il file CSV viene salvato nel bucket Amazon S3. -
Il crawler richiama il
save_news_links()metodo per salvare i link alle notizie in un file CSV, incluse le informazioni pertinenti. Il file CSV viene salvato nel bucket Amazon S3. -
Il crawler richiama il
save_pdf_links()metodo per salvare i collegamenti PDF in un file CSV. Il file CSV viene salvato nel bucket Amazon S3.
Suddivisione in batch ed elaborazione dei dati
Il processo di scansione è organizzato ed eseguito in modo strutturato. AWS Batch assegna i lavori per ogni azienda in modo che vengano eseguiti in parallelo, in batch. Ogni batch si concentra sul dominio e sui sottodomini di una singola azienda, così come li hai identificati nel tuo set di dati. Tuttavia, i processi dello stesso batch vengono eseguiti in sequenza in modo da non inondare il sito Web di troppe richieste. Questo aiuta l'applicazione a gestire il carico di lavoro di scansione in modo più efficiente e a garantire che tutti i dati pertinenti vengano acquisiti per ciascuna azienda.
Organizzando la scansione del Web in batch specifici dell'azienda, i dati raccolti vengono containerizzati. Questo aiuta a evitare che i dati di un'azienda vengano mescolati con i dati di altre società.
Il batching aiuta l'applicazione a raccogliere in modo efficiente i dati dal Web, mantenendo al contempo una struttura e una separazione chiare delle informazioni in base alle aziende target e ai rispettivi domini Web. Questo approccio aiuta a garantire l'integrità e l'usabilità dei dati raccolti, poiché sono organizzati in modo ordinato e associati all'azienda e ai domini appropriati.
