Amazon Redshift non supporterà più la creazione di nuovi Python a UDFs partire dal 1° novembre 2025. Se vuoi usare Python UDFs, crea la UDFs data precedente a quella data. Python esistente UDFs continuerà a funzionare normalmente. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Storage colonnare
Questa sezione descrive lo storage a colonne, che è il metodo utilizzato da Amazon Redshift per archiviare i dati tabulari in modo efficiente.
L'archiviazione a colonne per le tabelle di database è un fattore importante nell'ottimizzazione delle prestazioni delle query di analisi, in quanto riduce drasticamente i requisiti complessivi di I/O su disco. Riduce la quantità di dati che è necessario caricare dal disco.
La serie di figure seguente descrive in che modo l'archiviazione di dati a colonne migliori l'efficienza e come questo si traduca in altrettanta efficienza durante il recupero di dati in memoria.
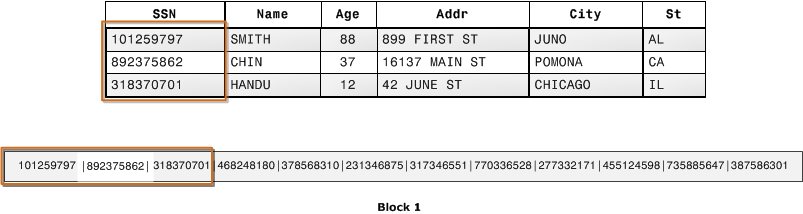
La prima figura mostra in che modo vengono generalmente archiviati i record delle tabelle di database in blocchi di dischi per riga.

In una normale tabella di database relazionale, ogni riga contiene valori dei campi per un singolo record. Nello storage di database basato su righe, i blocchi di dati archiviano i valori in sequenza per ogni colonna consecutiva che costituisce l'intera riga. Se le dimensioni del blocco sono minori di quelle di un record, lo storage per un intero record può richiedere più di un blocco. Se le dimensioni del blocco sono maggiori di quelle di un record, lo storage per un intero record può richiedere meno di un blocco, causando un uso poco efficiente dello spazio su disco. Nelle applicazioni di elaborazione di transazioni online (OLTP), la maggior parte delle transazioni comporta letture e scritture frequenti di tutti i valori per interi record, in genere un record o un numero ridotto di record per volta. Di conseguenza, lo storage basato su righe è ottimale per i database OLTP.
La figura seguente mostra in che modo con lo storage a colonne i valori per ogni colonna vengono archiviati in sequenza in blocchi del disco.
Usando lo storage a colonne, ogni blocco di dati archivia i valori di una singola colonna per più righe. Man mano che i record raggiungono il sistema, Amazon Redshift converte in modo trasparente i dati in storage a colonne per ognuna delle colonne.
In questo esempio semplificato, usando lo storage a colonne, ogni blocco di dati contiene valori dei campi di colonna per tre volte il numero di record dello storage basato su righe. Questo significa che la lettura dello stesso numero di valori dei campi di colonna per lo stesso numero di record richiede un terzo delle operazioni di I/O rispetto allo storage basato su righe. In pratica, usando tabelle con quantità molto elevate di colonne e quantità molto elevate di righe, l'efficienza dello storage è ancora maggiore.
Un altro vantaggio è che, poiché ogni blocco contiene lo stesso tipo di dati, i dati dei blocchi possono usare uno schema di compressione selezionato appositamente per il tipo di dati di colonna, riducendo ulteriormente lo spazio su disco e l'I/O. Per ulteriori informazioni sulle codifiche di compressione in base ai tipi di dati, consultare Codifiche di compressione.
I risparmi in termini di spazio per lo storage dei dati su disco si applicano anche al recupero e al successivo storage dei dati in memoria. Poiché molte operazioni di database devono solo accedere o operare in una colonna o un numero ridotto di colonne per volta, puoi risparmiare spazio di memoria recuperando solo i blocchi per le colonne effettivamente necessarie per una query. Nei casi in cui le transazioni OLTP interessano in genere la maggior parte o tutte le colonne in una riga per un numero ridotto di record, le query del data warehouse leggono normalmente solo poche colonne per un numero molto elevato di righe. Questo significa che la lettura dello stesso numero di valori dei campi di colonna per lo stesso numero di righe richiede un numero inferiore di operazioni di I/O. Utilizza una quantità inferiore della memoria necessaria per l'elaborazione di blocchi per riga. In pratica, usando tabelle con quantità molto elevate di colonne e quantità molto elevate di righe, i vantaggi in termini di efficienza sono proporzionalmente maggiori. Ad esempio, supponi che una tabella contenga 100 colonne. Una query che usa cinque colonne dovrà leggere solo circa il 5% dei dati contenuti nella tabella. Questi vantaggi si ripetono possibilmente per miliardi o addirittura trilioni di record per i database di grandi dimensioni. Al contrario, un database basato su righe dovrebbe leggere anche i blocchi che contengono le 95 colonne non necessarie.
In genere le dimensioni dei blocchi di database sono comprese tra 2 KB e 32 KB. In Amazon Redshift la dimensione dei blocchi è pari a 1 MB, che è più efficiente e riduce ulteriormente il numero di richieste di I/O necessarie per eseguire qualsiasi caricamento di database o altre operazioni che fanno parte dell'esecuzione di query.
