Amazon Redshift non supporterà più la creazione di nuovi Python a UDFs partire dal 1° novembre 2025. Se vuoi usare Python UDFs, crea la UDFs data precedente a quella data. Python esistente UDFs continuerà a funzionare normalmente. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Visualizzazione di dati di prestazioni dei cluster
I parametri dei cluster in Amazon Redshift consentono di completare le seguenti attività comuni relative alle prestazioni:
-
Determinare se i parametri dei cluster sono anormali nel corso di un intervallo di tempo specificato e se è il caso, identificare le query responsabili del peggioramento delle prestazioni.
-
Verificare se le query storiche o correnti hanno un impatto sulle prestazioni dei cluster. Se identifichi una query problematica, puoi visualizzarne i dettagli, incluse le prestazioni del cluster, durante l'esecuzione della query. Puoi utilizzare queste informazioni per diagnosticare il motivo per cui la query era lenta e le soluzioni per migliorarne le prestazioni.
Per visualizzare i dati relativi alle prestazioni
-
Accedi AWS Management Console e apri la console Amazon Redshift all'indirizzo. https://console.aws.amazon.com/redshiftv2/
-
Dal menu di navigazione, scegliere Clusters (Cluster), quindi scegliere dall'elenco il nome del cluster per visualizzarne i dettagli. Vengono visualizzati i dettagli del cluster, che possono includere le schede Prestazioni del cluster, Monitoraggio della query, Database, Condivisioni di dati, Pianificazioni, Manutenzione e Proprietà.
-
Scegli la scheda Cluster performance (Prestazioni del cluster) per visualizzare le informazioni relative alle prestazioni tra cui:
-
Utilizzo CPU
-
Percentuale di spazio su disco utilizzata
-
Connessioni database
-
Health status (Stato di integrità)
-
Durata query
-
Volume di elaborazione query
-
Attività di dimensionamento della concorrenza
Sono disponibili molti altri parametri. Per visualizzare i parametri disponibili e scegliere quelli da visualizzare, scegli l'icona Preferences (Preferenze).
-
Grafici delle prestazioni del cluster
Negli esempi seguenti vengono illustrati alcuni dei grafici che vengono visualizzati nella nuova console Amazon Redshift.
-
Utilizzo della CPU: mostra la percentuale di utilizzo della CPU per tutti i nodi (principale e di calcolo). Per individuare il momento in cui l'utilizzo del cluster è minimo prima di pianificare la migrazione del cluster o altre operazioni che richiedono risorse, monitora questo grafico per visualizzare l'utilizzo della CPU per singolo nodo o per tutti i nodi.
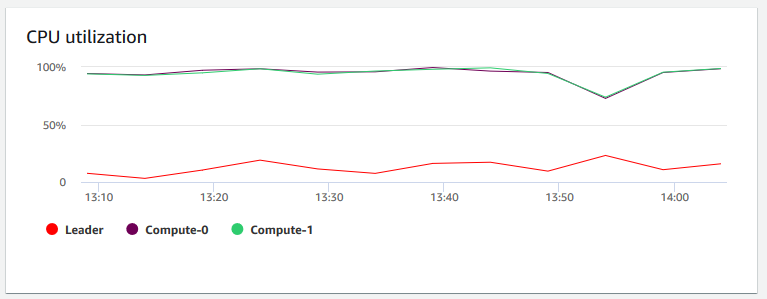
-
Modalità di manutenzione: indica se il cluster è in modalità di manutenzione all'ora specificata utilizzando gli indicatori
OneOff. È possibile visualizzare l'ora in cui il cluster è in fase di manutenzione. È quindi possibile correlare questa volta alle operazioni eseguite al cluster per stimarne i tempi di inattività futuri per eventi ricorrenti.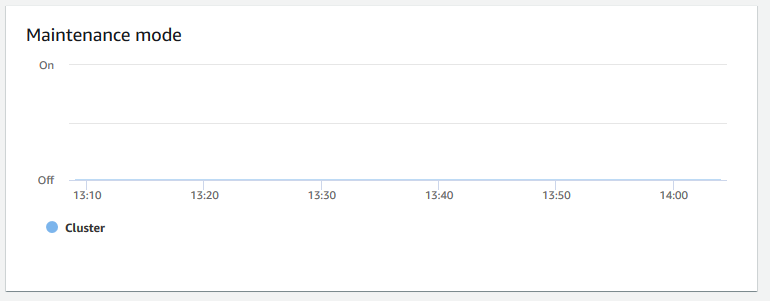
-
Percentuale di spazio su disco utilizzato: indica la percentuale di utilizzo dello spazio su disco per ciascun nodo di calcolo e non per il cluster nel suo complesso. Puoi esaminare questo grafico per monitorare l'utilizzo del disco. Le operazioni di manutenzione come VACUUM e COPY utilizzano spazio di storage temporaneo intermedio per le operazioni di ordinamento, quindi è previsto un picco nell'utilizzo del disco.

-
Throughput di lettura: mostra il numero medio di megabyte letti dal disco al secondo. Puoi esaminare questo grafico per monitorare l'aspetto fisico corrispondente del cluster. Questo throughput non include il traffico di rete tra le istanze nel cluster e il volume.
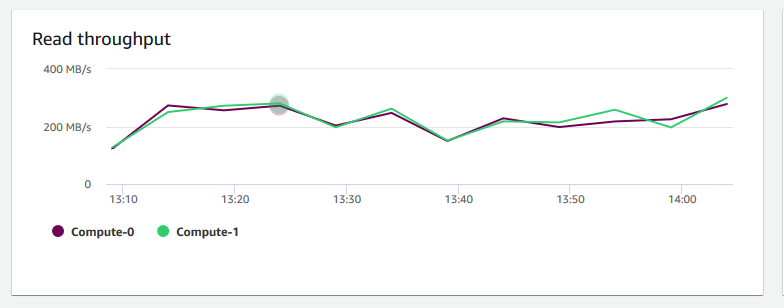
-
Latenza di lettura: mostra il tempo medio impiegato per le I/O operazioni di lettura del disco per millisecondo. Puoi visualizzare i tempi di risposta per la restituzione dei dati. Quando la latenza è elevata significa che il sender trascorre più tempo in inattività (non inviando nuovi pacchetti), riducendo così la velocità di crescita del throughput.

-
Throughput di scrittura: mostra il numero medio di megabyte scritti sul disco al secondo. Puoi esaminare questo parametro per monitorare l'aspetto fisico corrispondente del cluster. Questo throughput non include il traffico di rete tra le istanze nel cluster e il volume.
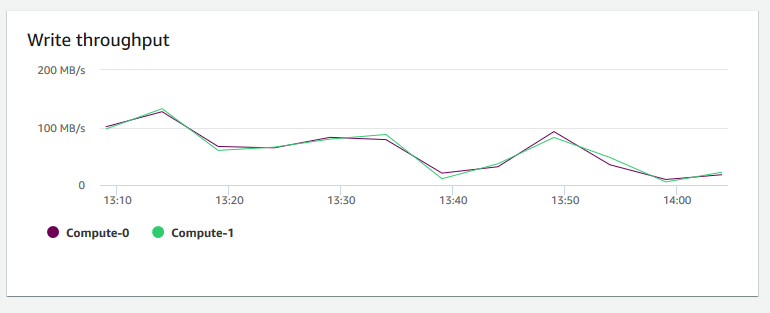
-
Latenza di scrittura: mostra il tempo medio, in millisecondi, impiegato per le operazioni di scrittura su disco. I/O Puoi valutare il tempo di restituzione della conferma di scrittura. Quando la latenza è elevata significa che il sender trascorre più tempo in inattività (non inviando nuovi pacchetti), riducendo così la velocità di crescita del throughput.
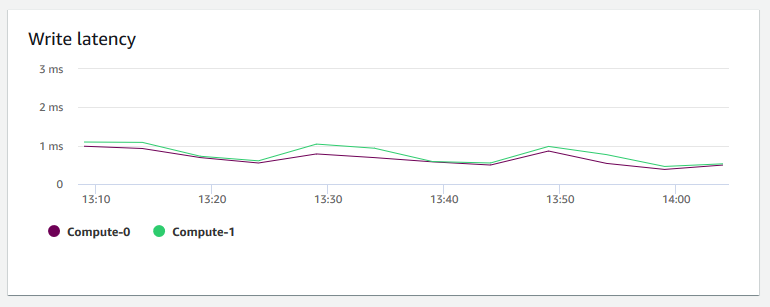
-
Connessioni al database: mostra il numero di connessioni al database per un cluster. È possibile utilizzare questo grafico per vedere il numero di connessioni stabilite al database e individuare l'ora in cui l'utilizzo del cluster è più basso.
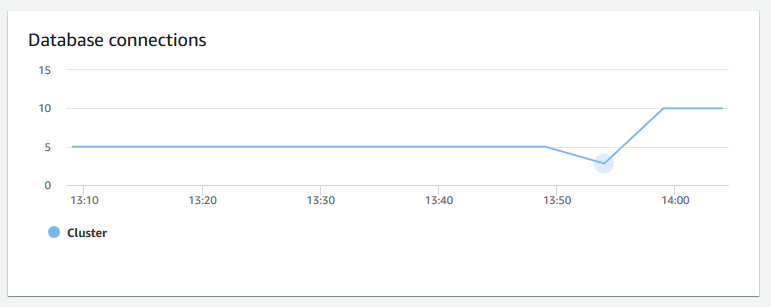
-
Numero totale di tabelle: mostra il numero di tabelle utente aperte in un determinato momento all'interno di un cluster. Puoi monitorare le prestazioni del cluster quando il numero di tabelle aperte è elevato.
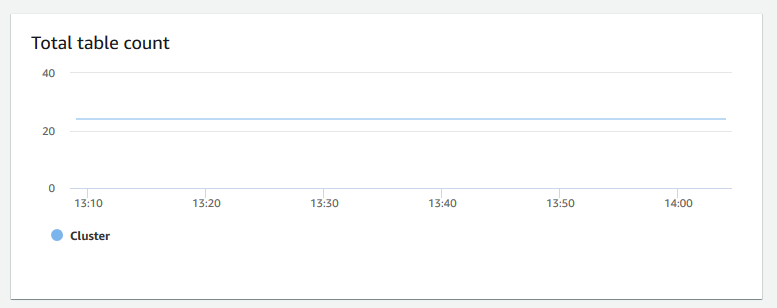
-
Stato di integrità: indica lo stato di integrità del cluster come
HealthyoUnhealthy. Se il cluster è in grado di connettersi al database ed esegue correttamente una query semplice, il cluster viene considerato integro. In caso contrario, il cluster non è integro. Uno stato non integro può verificarsi quando il database del cluster è sovraccaricato eccessivamente oppure se si verifica un problema di configurazione con un database sul cluster.
-
Durata della query: mostra il tempo medio impiegato per completare una query in microsecondi. Puoi confrontare i dati di questo grafico per misurare I/O le prestazioni all'interno del cluster e ottimizzare le query che richiedono più tempo, se necessario.
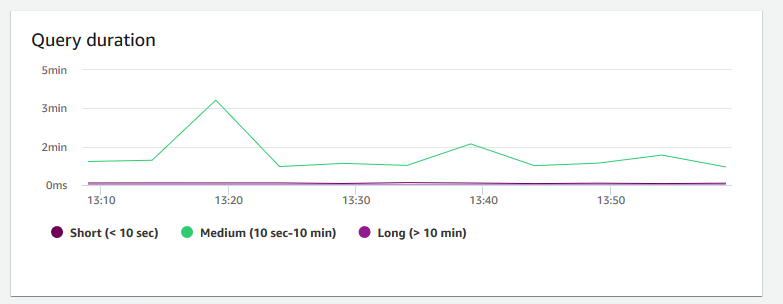
-
Throughput della query: mostra il numero medio di query completate al secondo. Puoi analizzare i dati in questo grafico per misurare le prestazioni del database e caratterizzare la capacità del sistema di supportare un carico di lavoro multiutente in modo equilibrato.
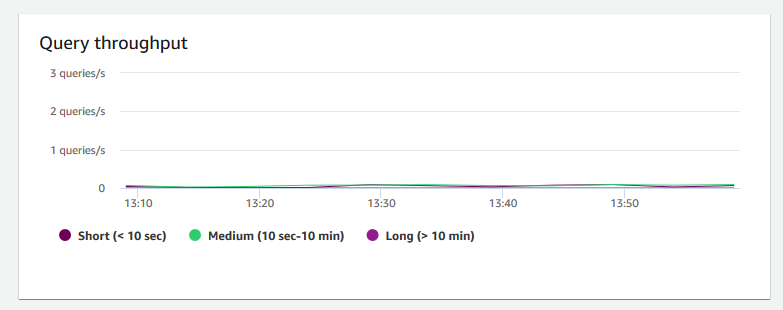
-
Durata delle query per coda WLM: mostra il tempo medio per completare una query in microsecondi. È possibile confrontare i dati di questo grafico per misurare le I/O prestazioni per coda WLM e, se necessario, ottimizzarne le query che richiedono più tempo.
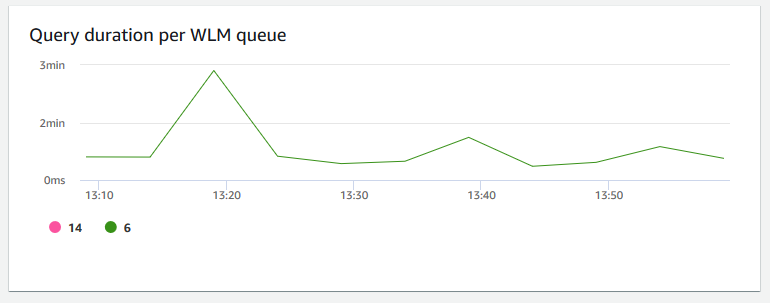
-
Throughput delle query per coda WLM: indica il numero medio di query completate al secondo. Puoi analizzare i dati in questo grafico per misurare le prestazioni del database per coda WLM.

-
Attività di dimensionamento simultaneo: mostra il numero di cluster di dimensionamento simultaneo attivi nell'intervallo di tempo selezionato. Quando il dimensionamento simultaneo è abilitato, Amazon Redshift aggiunge automaticamente ulteriore capacità del cluster quando necessario per elaborare un aumento delle query di lettura simultanee.

