Amazon Redshift non supporterà più la creazione di nuovi Python a UDFs partire dal 1° novembre 2025. Se vuoi usare Python UDFs, crea la UDFs data precedente a quella data. Python esistente UDFs continuerà a funzionare normalmente. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione di un cluster con provisioning ad Amazon Redshift Serverless
Puoi migrare i cluster predisposti esistenti su Amazon Redshift Serverless, abilitando la scalabilità on-demand e automatica delle risorse di elaborazione. La migrazione di un cluster predisposto su Amazon Redshift Serverless consente di ottimizzare i costi pagando solo per le risorse utilizzate e scalando automaticamente la capacità in base alle richieste del carico di lavoro. I casi d'uso più comuni per la migrazione includono l'esecuzione di query ad hoc, processi periodici di elaborazione dei dati o la gestione di carichi di lavoro imprevedibili senza sovradimensionare le risorse. Esegui la seguente serie di attività per migrare il cluster Amazon Redshift di cui hai effettuato il provisioning verso l'opzione di distribuzione serverless.
Creazione di uno snapshot del cluster con provisioning
Nota
Amazon Redshift converte automaticamente le chiavi interlacciate in chiavi composte quando si ripristina uno snapshot di cluster con provisioning in uno spazio dei nomi serverless.
Per trasferire i dati dal cluster con provisioning ad Amazon Redshift Serverless, crea uno snapshot del cluster, quindi ripristina lo snapshot in Amazon Redshift Serverless.
Nota
Prima di migrare i dati verso un gruppo di lavoro serverless, assicurati che le esigenze del cluster sottoposto a provisioning siano compatibili con la quantità di RPU scelta in Amazon Redshift Serverless.
Creazione di uno snapshot del cluster con provisioning
Accedi AWS Management Console e apri la console Amazon Redshift all'indirizzo. https://console.aws.amazon.com/redshiftv2/
-
Dal menu di navigazione, scegli Clusters (Cluster), Snapshots (Snapshot), quindi scegli Create snapshot (Crea snapshot).
-
Inserisci le proprietà della definizione dello snapshot, quindi scegli Create snapshot (Crea snapshot). La disponibilità dello snapshot potrebbe richiedere del tempo.
Per ripristinare uno snapshot cluster con provisioning in uno spazio dei nomi serverless:
Accedi AWS Management Console e apri la console Amazon Redshift all'indirizzo. https://console.aws.amazon.com/redshiftv2/
-
Avvia la console del cluster con provisioning Amazon Redshift e passa alla pagina Clusters (Cluster), Snapshots (Snapshot).
-
Scegliere uno snapshot da utilizzare.
-
Sceglie Ripristina da snapshot (Restore snapshot), Restore to serverless namespace (Ripristina su spazio dei nomi serverless).
-
Scegli uno spazio dei nomi in cui ripristinare lo snapshot.
-
Conferma di voler eseguire il ripristino dallo snapshot. Questa azione sostituisce tutti i database dell'endpoint serverless con i dati del cluster sottoposto a provisioning. Scegli Restore (Ripristina).
Per ulteriori informazioni sugli snapshot del cluster con provisioning, consulta Snapshot di Amazon Redshift.
Connessione ad Amazon Redshift serverless usando un driver
Per connetterti ad Amazon Redshift Serverless con il tuo client SQL preferito, puoi utilizzare il driver JDBC versione 2.x fornito da Amazon Redshift. Ti consigliamo di connetterti ad Amazon Redshift utilizzando la versione più recente del driver JDBC Amazon Redshift versione 2.x. Il numero di porta è facoltativo. Se non lo includi, Amazon Redshift Serverless utilizzerà il numero di porta 5439. È possibile passare a un'altra porta compresa nell'intervallo 5431-5455 o 8191-8215. Per modificare la porta predefinita per un endpoint serverless, usa l'API AWS CLI e Amazon Redshift.
Per trovare l'endpoint esatto da utilizzare per il driver JDBC, ODBC o Python, consulta Configurazione del gruppo di lavoro in Amazon Redshift serverless. Puoi anche utilizzare l'operazione API Serverless di Amazon Redshift GetWorkgroup o l' AWS CLI operazione get-workgroups per restituire informazioni sul tuo gruppo di lavoro e quindi connetterti.
Connessione tramite autenticazione basata su password
Per stabilire una connessione utilizzando il driver JDBC Amazon Redshift versione 2.x con autenticazione basata su password, utilizza la seguente sintassi:
jdbc:redshift://<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com:5439/?username=username&password=password
Per stabilire una connessione utilizzando il connettore Amazon Redshift Python con autenticazione basata su password, utilizza la seguente sintassi:
import redshift_connector with redshift_connector.connect( host='<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com', database='<database-name>', user='username', password='password' # port value of 5439 is specified by default ) as conn: pass
Per stabilire una connessione utilizzando il driver ODBC Amazon Redshift versione 2.x con autenticazione basata su password, utilizza la seguente sintassi:
Driver={Amazon Redshift ODBC Driver (x64)}; Server=<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com; Database=database-name; User=username; Password=password
Connessione tramite IAM
Se preferisci accedere con IAM, utilizza l'operazione API GetCredentialsServerless di Amazon Redshift.
Per utilizzare l'autenticazione IAM, aggiungi iam: l'URL JDBC di Amazon Redshift seguentejdbc:redshift:, come illustrato nell'esempio seguente.
jdbc:redshift:iam://<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com:5439/<database-name>
Questo endpoint Serverless Amazon Redshift non supporta la personalizzazione di dbUser, dbGroup o la creazione automatica. Per impostazione predefinita, il driver crea automaticamente gli utenti del database al momento dell'accesso. Quindi assegna gli utenti ai ruoli del database Amazon Redshift in base ai tag specificati in IAM o in base ai gruppi definiti nel tuo provider di identità (IdP).
Assicurati che la tua AWS identità disponga della politica IAM corretta per l'azione. redshift-serverless:GetCredentials Di seguito è riportato un esempio di policy IAM che concede le autorizzazioni corrette a un' AWS identità per connettersi ad Amazon Redshift Serverless. Per ulteriori informazioni sulle autorizzazioni IAM, consulta Aggiungere e rimuovere le autorizzazioni di identità IAM nella Guida per l'utente IAM.
Per stabilire una connessione utilizzando il connettore Amazon Redshift Python con autenticazione basata su IAM, utilizza iam=true nel codice, come mostrato nella seguente sintassi:
import redshift_connector with redshift_connector.connect( iam=True, host='<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com', database='<database-name>' <IAM credentials> ) as conn: pass
InfattiIAM credentials, puoi utilizzare qualsiasi credenziale, incluse le seguenti:
-
AWS configurazione del profilo.
-
credenziali IAM (un ID della chiave di accesso, una chiave di accesso segreta e, facoltativamente, un token di sessione).
-
Federazione dei provider di identità.
Per stabilire una connessione utilizzando il driver ODBC Amazon Redshift versione 2.x con autenticazione basata su IAM e un profilo, utilizza la seguente sintassi:
Driver={Amazon Redshift ODBC Driver (x64)}; IAM=true; Server=<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com; Database=database-name; Profile=aws-profile-name;
Connessione tramite IAM con l'API GetClusterCredentials
Nota
Quando ti connetti ad Amazon Redshift Serverless, ti consigliamo di utilizzare l'API. GetCredentials Questa API offre funzionalità complete di controllo degli accessi basato sui ruoli (RBAC) e altre nuove funzionalità che non sono disponibili in. GetClusterCredentials Supportiamo l'GetClusterCredentialsAPI per semplificare la transizione dai cluster predisposti ai gruppi di lavoro serverless, ma consigliamo vivamente di passare a Using il prima possibile per una compatibilità ottimale. GetCredentials
Puoi stabilire una connessione ad Amazon Redshift Serverless utilizzando l'API. GetClusterCredentials Per implementare questo metodo di autenticazione, modifica il client o l'applicazione incorporando i seguenti parametri:
iam=trueclusterid/cluster_identifier=redshift-serverless-<workgroup-name>region=<aws-region>
Gli esempi seguenti illustrano il plug-in BrowserSAML su tutti e tre i driver. Questo rappresenta uno dei diversi approcci di autenticazione disponibili. Gli esempi possono essere modificati per utilizzare metodi o plugin di autenticazione alternativi in base ai requisiti specifici.
Autorizzazioni della policy IAM per GetClusterCredentials
Di seguito è riportato un esempio di policy IAM con le autorizzazioni necessarie per l'uso GetClusterCredentials con Amazon Redshift Serverless:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "redshift:CreateClusterUser", "redshift:JoinGroup", "redshift:GetClusterCredentials", "redshift:ExecuteQuery", "redshift:FetchResults", "redshift:DescribeClusters", "redshift:DescribeTable" ], "Resource": [ "arn:aws:redshift:us-east-1:<account-id>:cluster:redshift-serverless-<workgroup-name>", "arn:aws:redshift:us-east-1:<account-id>:dbgroup:redshift-serverless-<workgroup-name>", "arn:aws:redshift:us-east-1:<account-id>:dbname:redshift-serverless-<workgroup-name>/${redshift:DbName}", "arn:aws:redshift:us-east-1:<account-id>:dbuser:redshift-serverless-<workgroup-name>/${redshift:DbUser}" ] } ] }
Per stabilire una connessione utilizzando il driver JDBC Amazon Redshift versione 2.x conGetClusterCredentials, utilizza la seguente sintassi:
jdbc:redshift:iam://redshift-serverless-<workgroup-name>:<aws-region>/<database-name>?plugin_name=com.amazon.redshift.plugin.BrowserSamlCredentialsProvider&login_url=<single sign-on URL from IdP>"
Per stabilire una connessione utilizzando il connettore Amazon Redshift Python conGetClusterCredentials, utilizza la seguente sintassi:
import redshift_connector with redshift_connector.connect( iam=True, cluster_identifier='redshift-serverless-<workgroup-name>', region='<aws-region>', database='<database-name>', credentials_provider='BrowserSamlCredentialsProvider' login_url='<single sign-on URL from IdP>' # port value of 5439 is specified by default ) as conn: pass
Per stabilire una connessione utilizzando il driver ODBC Amazon Redshift versione 2.x conGetClusterCredentials, utilizza la seguente sintassi:
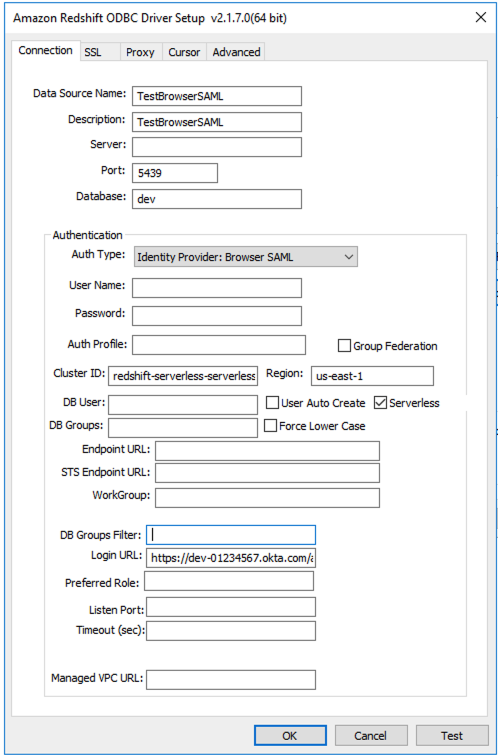
Driver= {Amazon Redshift ODBC Driver (x64)}; IAM=true; isServerless=true; ClusterId=redshift-serverless-<workgroup-name>; region=<aws-region>; plugin_name=BrowserSAML;login_url=<single sign-on URL from IdP>
Di seguito è riportato un esempio di configurazione ODBC DSN in Windows:
Utilizzo dell'SDK di Amazon Redshift Serverless
Se l'utente ha scritto script di gestione utilizzando l'SDK di Amazon Redshift, è necessario utilizzare il nuovo SDK per gestire l'istanza e le risorse di Amazon Redshift serverless. Per ulteriori informazioni sulle operazioni API disponibili, consulta Documentazione di riferimento delle API di Amazon Redshift Serverless.
