Architecture overview
This section provides a reference implementation architecture diagram for the components deployed with this solution.
Architecture diagram
Deploying this solution with the default parameters deploys the following components in your AWS account.
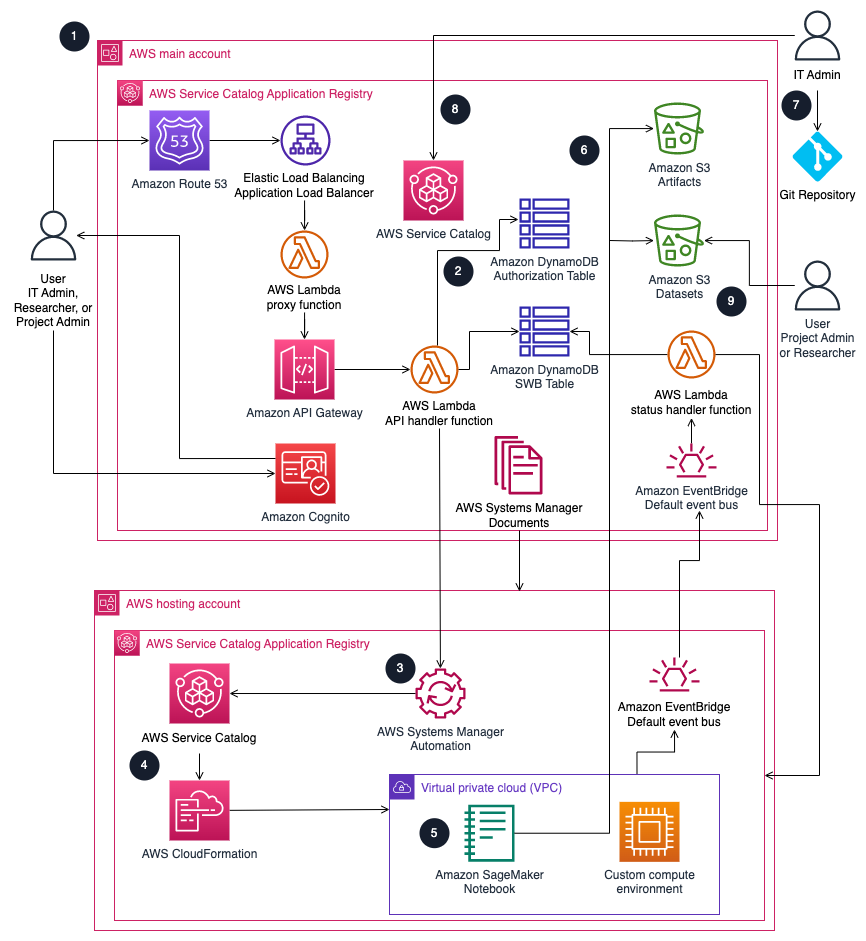
Figure 1: Research Service Workbench architecture on AWS
Note
AWS CloudFormation resources are created from AWS Cloud Development Kit (AWS CDK) (AWS CDK) constructs.
The high-level process flow for the solution components deployed with the AWS CloudFormation template is as follows:
Deploy using CloudFormation template or by using the CDK CLI in the main account and hosting account subsequently.
-
Users get access based on group permissions stored in the encrypted Amazon DynamoDB authorization table.
-
Systems Manager processes the shared documents from the main account in the hosting account to launch the environment.
-
To launch an environment, AWS Service Catalog runs the AWS CloudFormation template within the product.
-
CloudFormation creates a stack from the template to launch the environment within the Virtual Private Cloud (VPC) of the Hosting Account. Environments are created within Public Subnets of the VPC. An example of these environments is an Amazon SageMaker notebook.
-
After creation, environments within the hosting account can connect to the Amazon Simple Storage Service (Amazon S3) artifacts bucket in the main account to set up custom scripts in the instance. After creation, environments created with attached datasets can access datasets within the Amazon S3 datasets bucket through Access Points in the main account.
-
IT Admins can customize the source code hosted on GitHub, including full customization of environment lifecycles (launch, terminate, start, and stop) and connection. Changes to source code require re-deployment to take effect.
-
IT Admins can publish custom environment types to Service Catalog within the main account.
-
Users can request pre-signed S3 URLs through an RSW API endpoint. With the pre-signed S3 URL, users can add data to datasets within the Datasets S3 bucket in the main account.
Bring Your Own Network (BYON) architecture
Bring Your Own Network (BYON) is an alternative architecture for Research Service Workbench on AWS where you deploy the solution into an existing network configuration. In addition to the previous architecture details, the Application Load Balancer can be deployed into an existing VPC and a set of either private or public subnets by specifying those values in the configuration files during deployment.
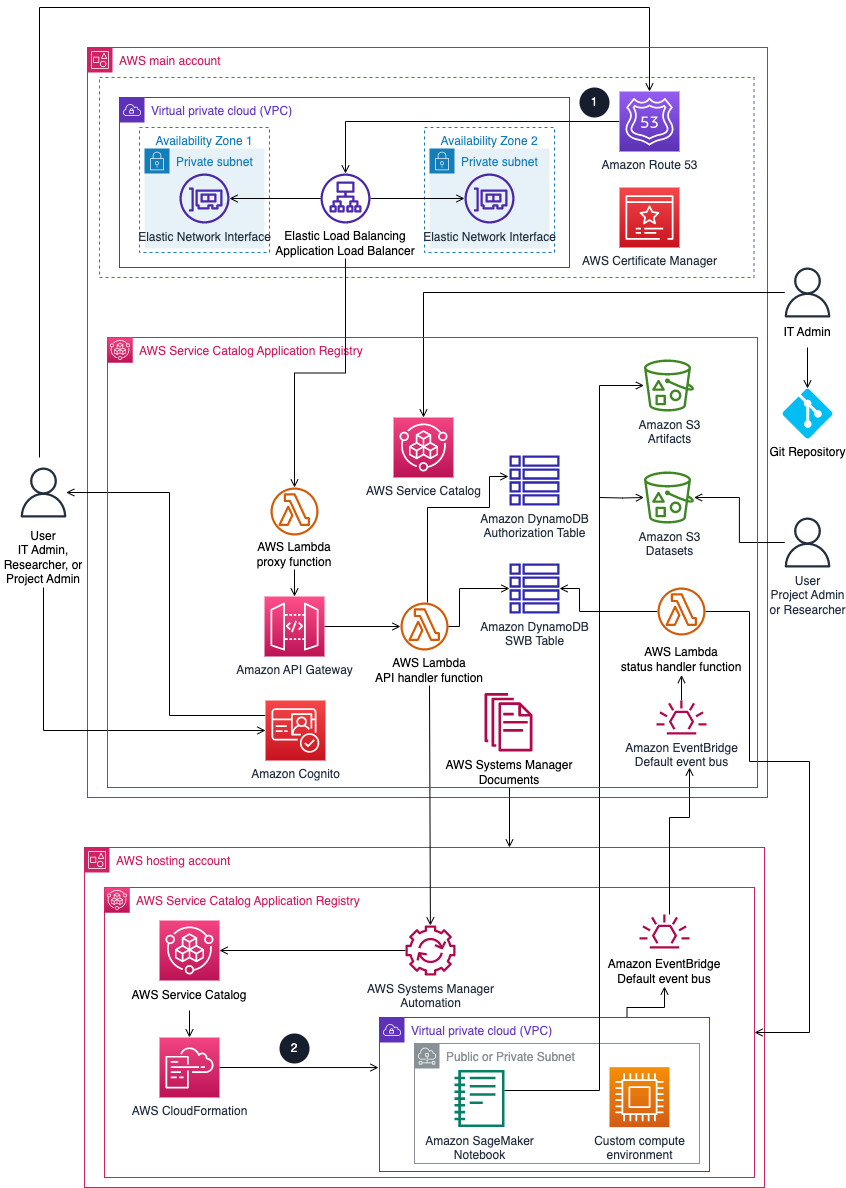
Figure 2: BYON architecture on AWS
Note
AWS CloudFormation resources are created from AWS Cloud Development Kit (AWS CDK) (AWS CDK) constructs.
In addition to the previous architecture diagram, the high-level process flow for the BYON solution components deployed is as follows:
-
Incoming traffic is balanced using an Application Load Balancer in a VPC subnet within the main account. Depending on configuration, the subnets can be private or public and be deployed to multiple Availability Zones.
-
When creating an environment, CloudFormation launches an environment within the VPC of the hosting account using a stack from the template. Depending on your network configuration, environments deploy within either public or private subnets of the VPC. An example of these environments is a SageMaker notebook. How you onboard a hosting account affects the architecture of the subnets.
AWS Well-Architected design considerations
This solution was designed with best practices from the
AWS Well-Architected Framework
This section describes how the design principles and best practices of the Well-Architected Framework were applied when building this solution.
Operational excellence
This section describes how the principles and best practices of the operational excellence pillar were applied when designing this solution.
-
Research Service Workbench provides metrics to Amazon CloudWatch for infrastructure visibility, and all processes handled by our compute layer are logged in CloudWatch. This includes both our API servers and our backend worker processes.
-
Infrastructure deployment is managed through the AWS CDK
.
Security
This section describes how the principles and best practices of the security pillar were applied when designing this solution.
-
Inter-service communications use AWS IAM roles.
-
Multi-account communications use AWS IAM roles.
-
Roles used by the solution follow least-privilege access. It only requires minimum permissions to function properly.
-
Amazon Cognito handles communication between the end user and the Amazon API Gateway by generating a JWT token.
-
Data storage, including Amazon S3 buckets, have encryption at rest.
-
Controlled Access Points protects access to data within the Datasets S3 bucket.
-
Dynamic Authorization using Amazon Cognito and DynamoDB tables ensures user access complies with the permissions within each project.
Reliability
This section describes how the principles and best practices of the reliability pillar were applied when designing this solution.
-
To ensure high availability and recovery from service failure, the solution uses AWS Serverless Services wherever possible (examples include AWS Lambda, Amazon API Gateway, and Amazon S3).
-
Data stored within Amazon DynamoDB has Point-in-time recovery (PITR) by default to protect from accidental write or delete operations. With point in time recovery, you don't have to worry about creating, maintaining, or scheduling on-demand backups. Amazon DynamoDB automatically scales the database capacity based on traffic.
-
Data processing uses AWS Lambda functions. AWS Lambda functions run in multiple Availability Zones to ensure that it is available to process events in case of a service interruption in a single zone by default.
Performance efficiency
This section describes how the principles and best practices of the performance efficiency pillar were applied when designing this solution.
-
The solution uses AWS serverless architecture throughout. This removes the operational burden of managing physical servers, and can lower transactional costs because managed services operate at cloud scale.
-
The solution can launch in any region that supports AWS services used in this solution such as: AWS Lambda, Amazon API Gateway, Amazon S3, Amazon Cognito, and Service Catalog.
-
The solution uses managed services throughout to reduce the operational burden of resource provisioning and management.
Cost optimization
This section describes how the principles and best practices of the cost optimization pillar were applied when designing this solution.
-
Because the solution uses serverless architecture where possible, costs have been minimized.
-
Amazon DynamoDB scales capacity on demand, so you only pay for the capacity you need.
Sustainability
This section describes how the principles and best practices of the sustainability pillar were applied when designing this solution.
-
To minimize the environmental impact of the backend services, Research Service Workbench uses managed and serverless services. Serverless technology (such as AWS Lambda and Amazon DynamoDB) reduces the carbon footprint compared to continually operating on-premise servers.
