Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica dell'architettura
Questa sezione fornisce un diagramma dell'architettura di implementazione di riferimento per i componenti distribuiti con questa soluzione.
Diagramma architetturale
La distribuzione di questa soluzione con i parametri predefiniti crea il seguente ambiente nel cloud AWS.
Workload Discovery sull'architettura AWS
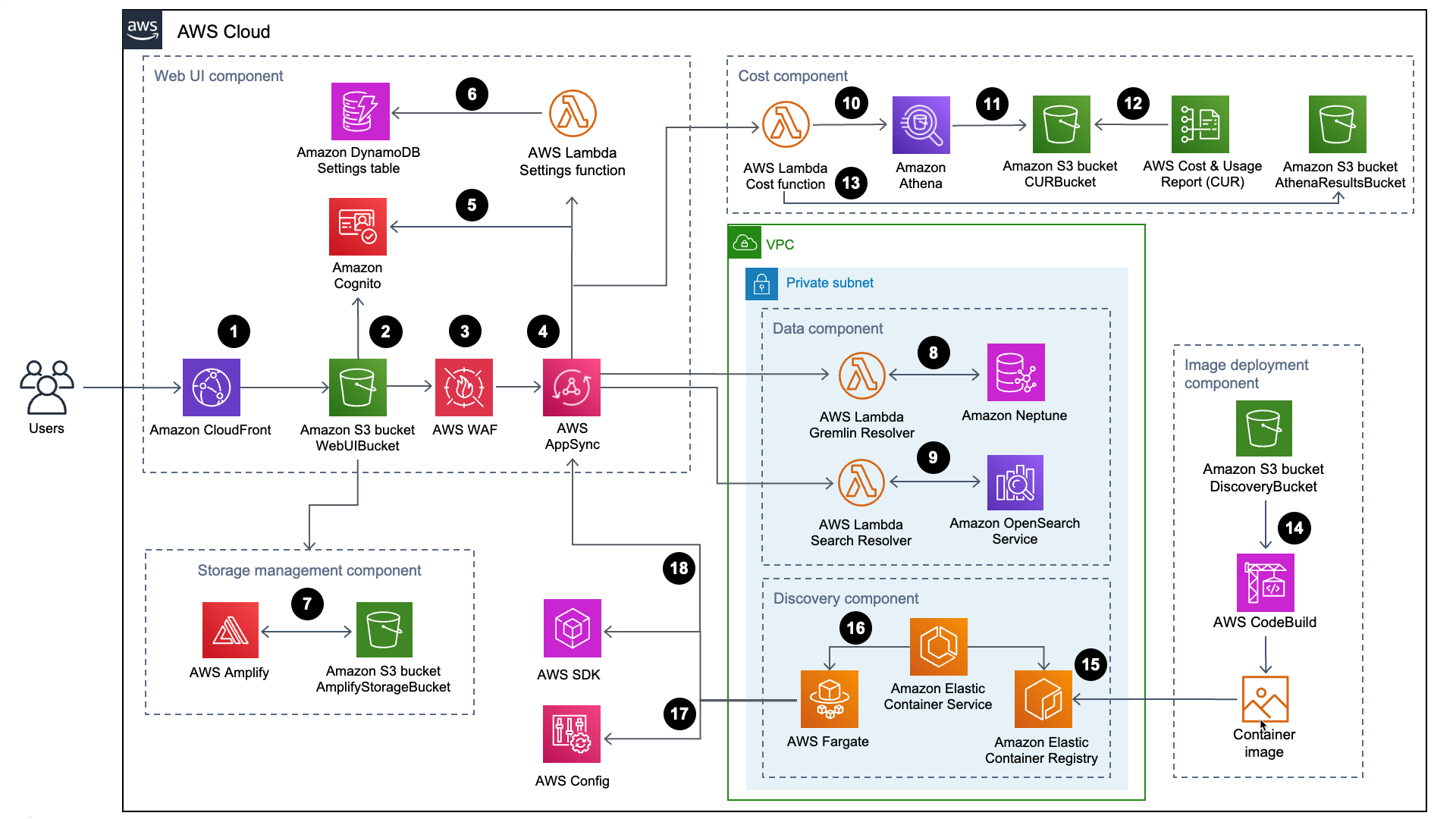
Il flusso di processo di alto livello per i componenti della soluzione distribuiti con il CloudFormation modello AWS è il seguente:
-
HTTP Strict-Transport-Security (HSTS)
aggiunge intestazioni di sicurezza a ogni risposta della distribuzione Amazon CloudFront . -
Un bucket Amazon Simple Storage Service
(Amazon S3) ospita l'interfaccia utente Web, distribuita con Amazon. CloudFront Amazon Cognito autentica l'accesso degli utenti all'interfaccia utente Web. -
AWS WAF
protegge l' AppSync API da exploit e bot comuni che possono influire sulla disponibilità, compromettere la sicurezza o consumare risorse eccessive. -
Gli AppSync endpoint AWS
consentono al componente dell'interfaccia utente Web di richiedere dati sulle relazioni tra le risorse, eseguire query sui costi, importare nuove regioni AWS e aggiornare le preferenze. AWS consente AppSync inoltre al componente discovery di archiviare dati persistenti nei database della soluzione. -
AWS AppSync utilizza JSON Web Tokens
(JWTs) forniti da Amazon Cognito per autenticare ogni richiesta. -
La funzione
SettingsAWS Lambdamantiene le regioni importate e altre configurazioni in Amazon DynamoDB. -
La soluzione implementa AWS Amplify e
un bucket Amazon S3 come componente di gestione dello storage per archiviare le preferenze degli utenti e i diagrammi di architettura salvati. -
Il componente dati utilizza la funzione
Gremlin ResolverAWS Lambda per interrogare e restituire dati da un database Amazon Neptune. -
Il componente dati utilizza la funzione
Search ResolverLambda per interrogare e rendere persistenti i dati delle risorse in un dominio Amazon OpenSearchService. -
La funzione
CostLambda utilizza Amazon Athenaper interrogare AWS Cost and Usage Reports (AWS CUR) per fornire dati sui costi stimati all'interfaccia utente Web. -
Amazon Athena esegue query su AWS CUR.
-
AWS CUR invia i report al bucket
CostAndUsageReportBucketAmazon S3. -
La funzione
CostLambda memorizza i risultati di Amazon Athena nel bucket AmazonAthenaResultsBucketS3. -
AWS CodeBuild
crea l'immagine del contenitore del componente di rilevamento nel componente di distribuzione dell'immagine. -
Amazon Elastic Container Registry
(Amazon ECR) contiene un'immagine Docker fornita dal componente di distribuzione dell'immagine. -
Amazon Elastic Container Service
(Amazon ECS) gestisce il task AWS Fargate e fornisce la configurazione necessaria per eseguirlo. AWS Fargate esegue un'attività di container ogni 15 minuti per aggiornare i dati di inventario e risorse. -
Le chiamate AWS Config
e AWS SDK aiutano il componente discovery a mantenere un inventario dei dati delle risorse dalle regioni importate, quindi a memorizzarne i risultati nel componente dati. -
Il task AWS Fargate mantiene i risultati delle chiamate AWS Config e AWS SDK in un database Amazon Neptune e in un dominio Amazon Service con chiamate API all'API. OpenSearch AppSync
