Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizza passaggi predefiniti
Quando crei un flusso di lavoro, puoi scegliere di aggiungere uno dei seguenti passaggi predefiniti descritti in questo argomento. Puoi anche scegliere di aggiungere fasi personalizzate di elaborazione dei file. Per ulteriori informazioni, consulta Utilizza passaggi di elaborazione dei file personalizzati.
Argomenti
Copia il file
Una fase di copia del file crea una copia del file caricato in una nuova posizione Amazon S3. Attualmente, puoi utilizzare una fase di copia del file solo con Amazon S3.
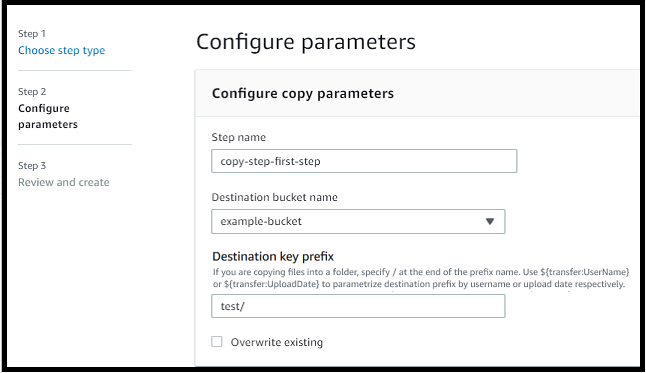
La seguente fase di copia del file copia i file nella test cartella inamzn-s3-demo-destination-bucket.
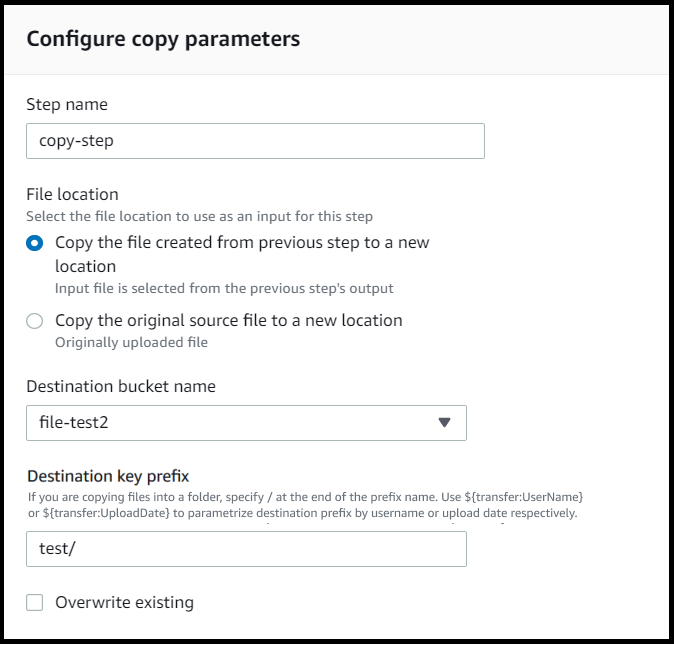
Se la fase di copia del file non è la prima fase del flusso di lavoro, puoi specificare la posizione del file. Specificando la posizione del file, è possibile copiare il file utilizzato nel passaggio precedente o il file originale caricato. È possibile utilizzare questa funzione per creare più copie del file originale mantenendo intatto il file di origine per l'archiviazione dei file e la conservazione dei record. Per vedere un esempio, consulta Esempio di workflow di etichettatura ed eliminazione.
Fornisci il bucket e i dettagli chiave
È necessario fornire il nome del bucket e una chiave per la destinazione della fase di copia del file. La chiave può essere un nome di percorso o un nome di file. Il fatto che la chiave venga considerata come un nome di percorso o un nome di file dipende dal fatto che terminiate la chiave con il carattere forward slash (/).
Se il carattere finale è/, il file viene copiato nella cartella e il suo nome non cambia. Se il carattere finale è alfanumerico, il file caricato viene rinominato con il valore chiave. In questo caso, se esiste già un file con quel nome, il comportamento dipende dall'impostazione del campo Sovrascrivi esistente.
-
Se è selezionato Sovrascrivi esistente, il file esistente viene sostituito con il file in fase di elaborazione.
-
Se l'opzione Sovrascrivi esistente non è selezionata, non succede nulla e l'elaborazione del flusso di lavoro si interrompe.
Suggerimento
Se le scritture simultanee vengono eseguite sullo stesso percorso del file, è possibile che si verifichi un comportamento imprevisto durante la sovrascrittura dei file.
Ad esempio, se il valore chiave ètest/, i file caricati vengono copiati nella cartella. test Se il valore della chiave ètest/today, (e l'opzione Sovrascrivi esistente è selezionata) ogni file caricato viene copiato in un file denominato today nella test cartella e ogni file successivo sovrascrive quello precedente.
Nota
Amazon S3 supporta i bucket e gli oggetti e non sono presenti gerarchie. Tuttavia, puoi utilizzare prefissi e delimitatori nei nomi delle chiavi degli oggetti per creare una gerarchia e organizzare i dati in modo simile alle cartelle.
Utilizzate una variabile denominata in una fase di copia del file
In una fase di copia del file, è possibile utilizzare una variabile per copiare dinamicamente i file in cartelle specifiche dell'utente. Attualmente, puoi utilizzare ${transfer:UserName} or ${transfer:UploadDate} come variabile per copiare i file in una posizione di destinazione per un determinato utente che sta caricando i file o in base alla data corrente.
Nell'esempio seguente, se l'utente richard-roe carica un file, questo viene copiato nella cartella. amzn-s3-demo-destination-bucket/richard-roe/processed/ Se l'utente mary-major carica un file, questo viene copiato nella cartella. amzn-s3-demo-destination-bucket/mary-major/processed/
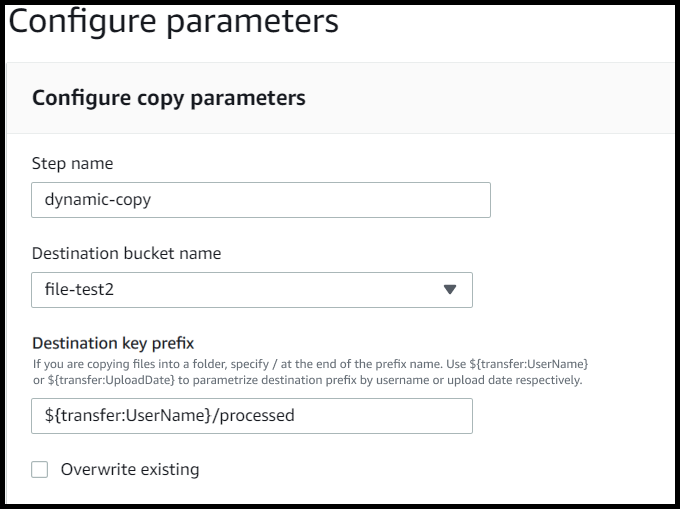
Allo stesso modo, è possibile utilizzarli ${transfer:UploadDate} come variabile per copiare i file in una posizione di destinazione denominata in base alla data corrente. Nell'esempio seguente, se impostate la destinazione ${transfer:UploadDate}/processed sul 1° febbraio 2022, i file caricati vengono copiati nella amzn-s3-demo-destination-bucket/2022-02-01/processed/ cartella.
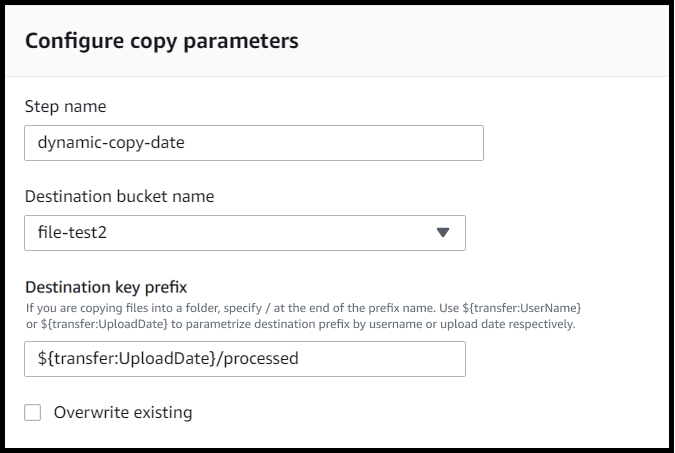
È inoltre possibile utilizzare entrambe queste variabili insieme, combinandone le funzionalità. Ad esempio, è possibile impostare il prefisso della chiave di destinazione sufolder/${transfer:UserName}/${transfer:UploadDate}/, che creerebbe ad esempio cartelle annidate. folder/marymajor/2023-01-05/
Autorizzazioni IAM per la fase di copia
Per consentire il completamento di una fase di copia, assicurati che il ruolo di esecuzione per il tuo flusso di lavoro contenga le seguenti autorizzazioni.
{ "Sid": "ListBucket", "Effect": "Allow", "Action": "s3:ListBucket", "Resource": [ "arn:aws:s3:::amzn-s3-demo-destination-bucket" ] }, { "Sid": "HomeDirObjectAccess", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObjectVersion", "s3:DeleteObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::amzn-s3-demo-destination-bucket/*" }
Nota
L's3:ListBucketautorizzazione è necessaria solo se non si seleziona Sovrascrivi esistente. Questa autorizzazione controlla il tuo bucket per vedere se esiste già un file con lo stesso nome. Se hai selezionato Sovrascrivi esistente, non è necessario che il flusso di lavoro verifichi la presenza del file e può semplicemente scriverlo.
Se i tuoi file Amazon S3 hanno tag, devi aggiungere una o due autorizzazioni alla tua policy IAM.
-
Aggiungi
s3:GetObjectTaggingper un file Amazon S3 senza versione. -
Aggiungi
s3:GetObjectVersionTaggingper un file Amazon S3 con versione.
Decrittografa il file
Il blog AWS sullo storage ha un post che descrive come decrittografare semplicemente i file senza scrivere alcun codice utilizzando i flussi di lavoro Transfer Family Managed, crittografare e decrittografare i file con PGP e
Algoritmi di crittografia simmetrica supportati
Per la decrittografia PGP, Transfer Family supporta algoritmi di crittografia simmetrica utilizzati per crittografare i dati effettivi dei file all'interno dei file PGP.
-
Per informazioni dettagliate sugli algoritmi di crittografia simmetrica supportati, vedere. Algoritmi di crittografia simmetrica PGP
-
Per informazioni sugli algoritmi di key pair PGP utilizzati con questi algoritmi simmetrici, vedere. Algoritmi di key pair PGP
Usa la decrittografia PGP nel tuo flusso di lavoro
Transfer Family ha il supporto integrato per la decrittografia Pretty Good Privacy (PGP). Puoi utilizzare la decrittografia PGP su file caricati tramite SFTP, FTPS o FTP su Amazon Simple Storage Service (Amazon S3) o Amazon Elastic File System (Amazon EFS).
Per utilizzare la decrittografia PGP, devi creare e archiviare le chiavi private PGP che verranno utilizzate per la decrittografia dei tuoi file. I tuoi utenti possono quindi crittografare i file utilizzando le chiavi di crittografia PGP corrispondenti prima di caricare i file sul server Transfer Family. Dopo aver ricevuto i file crittografati, puoi decrittografarli nel tuo flusso di lavoro. Per un tutorial dettagliato, consulta Configurazione di un flusso di lavoro gestito per la decrittografia di un file.
Per informazioni sugli algoritmi PGP supportati e sui consigli, consulta. Algoritmi di crittografia e decrittografia PGP
Per utilizzare la decrittografia PGP nel flusso di lavoro
-
Identifica un server Transfer Family per ospitare il tuo flusso di lavoro o creane uno nuovo. È necessario disporre dell'ID del server prima di poter memorizzare le chiavi PGP Gestione dei segreti AWS con il nome segreto corretto.
-
Memorizza la tua chiave PGP Gestione dei segreti AWS con il nome segreto richiesto. Per informazioni dettagliate, vedi Gestire le chiavi PGP. I flussi di lavoro possono individuare automaticamente la chiave PGP corretta da utilizzare per la decrittografia in base al nome segreto in Secrets Manager.
Nota
Quando memorizzi segreti in Secrets Manager, ti vengono Account AWS addebitati dei costi. Per informazioni sui prezzi, consulta Gestione dei segreti AWS Pricing
. -
Crittografa un file usando la tua coppia di chiavi PGP. (Per un elenco dei client supportati, consulta.) Client PGP supportati Se stai usando la riga di comando, esegui il comando seguente. Per usare questo comando, sostituiscilo
username@example.comtestfile.txtgpg -e -rusername@example.comtestfile.txtImportante
Quando crittografate i file per utilizzarli con i AWS Transfer Family flussi di lavoro, assicuratevi sempre di specificare un destinatario non anonimo utilizzando il parametro.
-rLa crittografia anonima (senza specificare un destinatario) può causare errori di decrittografia nel flusso di lavoro perché il sistema non sarà in grado di identificare quale chiave utilizzare per la decrittografia. Le informazioni di debug relative a questo problema sono disponibili all'indirizzo. Risolvi i problemi di crittografia dei destinatari anonimi -
Carica il file crittografato sul tuo server Transfer Family.
-
Configura una fase di decrittografia nel tuo flusso di lavoro. Per ulteriori informazioni, consulta Aggiungi una fase di decrittografia.
Aggiungi una fase di decrittografia
Una fase di decrittografia decrittografa un file crittografato che è stato caricato su Amazon S3 o Amazon EFS come parte del tuo flusso di lavoro. Per dettagli sulla configurazione della decrittografia, consulta. Usa la decrittografia PGP nel tuo flusso di lavoro
Quando si crea la fase di decrittografia per un flusso di lavoro, è necessario specificare la destinazione dei file decrittografati. È inoltre necessario selezionare se sovrascrivere i file esistenti se un file esiste già nella posizione di destinazione. Puoi monitorare i risultati del flusso di lavoro di decrittografia e ottenere log di controllo per ogni file in tempo reale utilizzando Amazon Logs. CloudWatch
Dopo aver scelto il tipo di file Decrypt per il passaggio, viene visualizzata la pagina Configura parametri. Inserisci i valori per la sezione Configura i parametri di decrittografia PGP.
Le opzioni disponibili sono le seguenti:
-
Nome della fase: immettere un nome descrittivo per la fase.
-
Posizione del file: specificando la posizione del file, è possibile decrittografare il file utilizzato nel passaggio precedente o il file originale caricato.
Nota
Questo parametro non è disponibile se questo passaggio è il primo passaggio del flusso di lavoro.
-
Destinazione per i file decrittografati: scegli un bucket Amazon S3 o un file system Amazon EFS come destinazione per il file decrittografato.
-
Se scegli Amazon S3, devi fornire un nome del bucket di destinazione e un prefisso della chiave di destinazione. Per parametrizzare il prefisso della chiave di destinazione in base al nome utente,
${transfer:UserName}immettete Destination key prefix. Analogamente, per parametrizzare il prefisso della chiave di destinazione in base alla data di caricamento,${Transfer:UploadDate}immettete Destination key prefix. -
Se scegli Amazon EFS, devi fornire un file system e un percorso di destinazione.
Nota
L'opzione di archiviazione scelta qui deve corrispondere al sistema di storage utilizzato dal server Transfer Family a cui è associato questo flusso di lavoro. In caso contrario, riceverai un errore quando tenterai di eseguire questo flusso di lavoro.
-
-
Sovrascrivi file esistenti: se carichi un file e nella destinazione esiste già un file con lo stesso nome, il comportamento dipende dall'impostazione di questo parametro:
-
Se si seleziona Sovrascrivi esistente, il file esistente viene sostituito con il file in fase di elaborazione.
-
Se l'opzione Sovrascrivi esistente non è selezionata, non succede nulla e l'elaborazione del flusso di lavoro si interrompe.
Suggerimento
Se le scritture simultanee vengono eseguite sullo stesso percorso del file, è possibile che si verifichi un comportamento imprevisto durante la sovrascrittura dei file.
-
La schermata seguente mostra un esempio delle opzioni che è possibile scegliere per la fase di decrittografia del file.
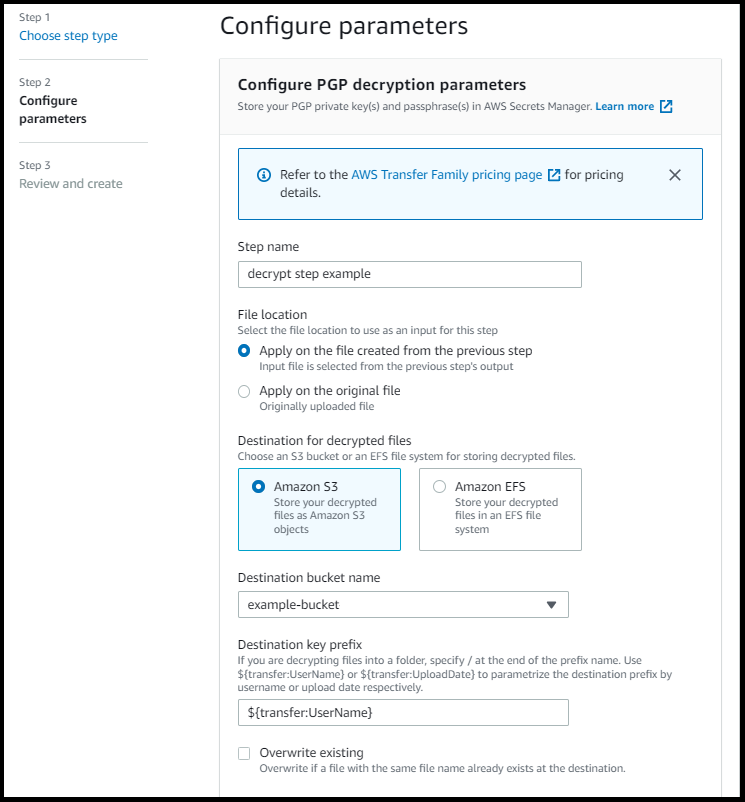
Autorizzazioni IAM per la fase di decrittografia
Per consentire il successo di una fase di decrittografia, assicurati che il ruolo di esecuzione per il tuo flusso di lavoro contenga le seguenti autorizzazioni.
{ "Sid": "ListBucket", "Effect": "Allow", "Action": "s3:ListBucket", "Resource": [ "arn:aws:s3:::amzn-s3-demo-destination-bucket" ] }, { "Sid": "HomeDirObjectAccess", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObjectVersion", "s3:DeleteObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::amzn-s3-demo-destination-bucket/*" }, { "Sid": "Decrypt", "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", ], "Resource": "arn:aws:secretsmanager:region:account-id:secret:aws/transfer/*" }
Nota
L's3:ListBucketautorizzazione è necessaria solo se non si seleziona Sovrascrivi esistente. Questa autorizzazione controlla il tuo bucket per vedere se esiste già un file con lo stesso nome. Se hai selezionato Sovrascrivi esistente, non è necessario che il flusso di lavoro verifichi la presenza del file e può semplicemente scriverlo.
Se i tuoi file Amazon S3 hanno tag, devi aggiungere una o due autorizzazioni alla tua policy IAM.
-
Aggiungi
s3:GetObjectTaggingper un file Amazon S3 senza versione. -
Aggiungi
s3:GetObjectVersionTaggingper un file Amazon S3 con versione.
Tag: file
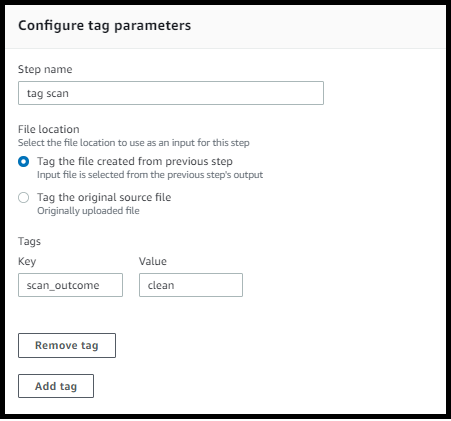
Per etichettare i file in arrivo per un'ulteriore elaborazione a valle, utilizzate un passaggio di tag. Immettete il valore del tag che desiderate assegnare ai file in arrivo. Attualmente, l'operazione di tag è supportata solo se utilizzi Amazon S3 per lo storage del server Transfer Family.
Il seguente esempio di tag step assegna scan_outcome e clean come tag, rispettivamente, la chiave e il valore.
Per consentire il completamento di una fase di tag, assicurati che il ruolo di esecuzione per il tuo flusso di lavoro contenga le seguenti autorizzazioni.
{ "Sid": "Tag", "Effect": "Allow", "Action": [ "s3:PutObjectTagging", "s3:PutObjectVersionTagging" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/*" ] }
Nota
Se il flusso di lavoro contiene un'istruzione di tag che viene eseguita prima di una fase di copia o decrittografia, devi aggiungere una o due autorizzazioni alla tua policy IAM.
-
Aggiungi
s3:GetObjectTaggingper un file Amazon S3 senza versione. -
Aggiungi
s3:GetObjectVersionTaggingper un file Amazon S3 con versione.
Eliminare il file
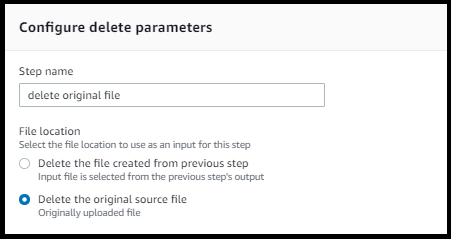
Per eliminare un file elaborato da una fase precedente del flusso di lavoro o per eliminare il file originariamente caricato, utilizzate un passaggio di eliminazione del file.
Per consentire il completamento di un passaggio di eliminazione, assicurati che il ruolo di esecuzione per il tuo flusso di lavoro contenga le seguenti autorizzazioni.
{ "Sid": "Delete", "Effect": "Allow", "Action": [ "s3:DeleteObjectVersion", "s3:DeleteObject" ], "Resource": "arn:aws:secretsmanager:region:account-ID:secret:aws/transfer/*" }
Variabili denominate per i flussi di lavoro
Per le fasi di copia e decrittografia, puoi utilizzare una variabile per eseguire azioni in modo dinamico. Attualmente, AWS Transfer Family supporta le seguenti variabili denominate.
-
Consente
${transfer:UserName}di copiare o decrittografare i file in una destinazione in base all'utente che carica i file. -
${transfer:UploadDate}Da utilizzare per copiare o decrittografare i file in una posizione di destinazione in base alla data corrente.
Esempio di workflow di etichettatura ed eliminazione
L'esempio seguente illustra un flusso di lavoro che contrassegna i file in entrata che devono essere elaborati da un'applicazione a valle, ad esempio una piattaforma di analisi dei dati. Dopo aver taggato il file in arrivo, il flusso di lavoro elimina quindi il file originariamente caricato per risparmiare sui costi di archiviazione.