Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Rilevamento dei guasti mediante rilevamento dei valori anomali
Una lacuna rispetto all'approccio precedente potrebbe verificarsi quando si riscontrano tassi di errore elevati in più zone di disponibilità che si verificano per un motivo non correlato. Immagina uno scenario in cui EC2 le istanze siano distribuite in tre zone di disponibilità e la soglia di allarme di disponibilità sia del 99%. Quindi, si verifica un danno a una singola zona di disponibilità, che isola molte istanze e fa scendere la disponibilità in quella zona al 55%. Allo stesso tempo, ma in una zona di disponibilità diversa, una singola EC2 istanza esaurisce tutto lo storage del EBS volume e non è più in grado di scrivere file di log. Ciò fa sì che inizi a restituire errori, ma supera comunque i controlli di integrità del load balancer perché questi non attivano la scrittura di un file di registro. Ciò si traduce in una riduzione della disponibilità al 98% in quella zona di disponibilità. In questo caso, l'allarme di impatto di una singola zona di disponibilità non si attiverebbe perché si riscontra un impatto sulla disponibilità in più zone di disponibilità. Tuttavia, è comunque possibile mitigare quasi tutto l'impatto evacuando la zona di disponibilità compromessa.
In alcuni tipi di carichi di lavoro, è possibile che si verifichino errori coerenti in tutte le zone di disponibilità, per cui la precedente metrica di disponibilità potrebbe non essere utile. Prendiamo ad AWS Lambda esempio. AWS consente ai clienti di creare il proprio codice da eseguire nella funzione Lambda. Per utilizzare il servizio, è necessario caricare il codice in un ZIP file, comprese le dipendenze, e definire il punto di ingresso alla funzione. Ma a volte i clienti sbagliano questa parte, ad esempio potrebbero dimenticare una dipendenza critica nel ZIP file o digitare erroneamente il nome del metodo nella definizione della funzione Lambda. Ciò fa sì che la funzione non venga richiamata e genera un errore. AWS Lambda vede continuamente questo tipo di errori, ma non è indicativo che qualcosa sia necessariamente malsano. Tuttavia, anche qualcosa come una compromissione della zona di disponibilità potrebbe causare la comparsa di questi errori.
Per individuare il segnale in presenza di questo tipo di rumore, è possibile utilizzare il rilevamento dei valori anomali per determinare se esiste una differenza statisticamente significativa nel numero di errori tra le zone di disponibilità. Sebbene riscontriamo errori in più zone di disponibilità, se si verificasse davvero un errore in una di esse, ci aspetteremmo di vedere un tasso di errore molto più elevato in quella zona di disponibilità rispetto alle altre, o potenzialmente molto inferiore. Ma quanto più alto o più basso?
Un modo per eseguire questa analisi consiste nell'utilizzare un test chi-squared
Un test chi-squared valuta la probabilità che si verifichi una certa distribuzione dei risultati. In questo caso, siamo interessati alla distribuzione degli errori in un insieme definito di. AZs Per questo esempio, per semplificare i calcoli, considera quattro zone di disponibilità.
Innanzitutto, stabilite l'ipotesi nulla, che definisce quello che ritenete sia il risultato predefinito. In questo test, l'ipotesi nulla è che ci si aspetti che gli errori vengano distribuiti uniformemente in ogni zona di disponibilità. Quindi, genera l'ipotesi alternativa, ovvero che gli errori non siano distribuiti in modo uniforme, il che indica una compromissione della zona di disponibilità. Ora puoi testare queste ipotesi utilizzando i dati delle tue metriche. A tal fine, campionerai le tue metriche in una finestra di cinque minuti. Supponiamo di ottenere 1000 punti dati pubblicati in quella finestra, in cui vengono visualizzati 100 errori totali. Ti aspetti che con una distribuzione uniforme gli errori si verifichino il 25% delle volte in ciascuna delle quattro zone di disponibilità. Supponiamo che la tabella seguente mostri ciò che ti aspettavi rispetto a ciò che hai effettivamente visto.
Tabella 1: Errori previsti e errori effettivi rilevati
| AZ | Expected (Atteso) | Effettivo |
|---|---|---|
use1-az1 |
25 | 20 |
use1-az2 |
25 | 20 |
use1-az3 |
25 | 25 |
use1-az4 |
25 | 35 |
Quindi, vedete che la distribuzione in realtà non è uniforme. Tuttavia, potresti credere che ciò sia avvenuto a causa di un certo livello di casualità nei punti dati che hai campionato. Esiste un certo livello di probabilità che questo tipo di distribuzione si verifichi nel set di campioni e si presume comunque che l'ipotesi nulla sia vera. Ciò porta alla seguente domanda: qual è la probabilità di ottenere un risultato almeno così estremo? Se tale probabilità è inferiore a una soglia definita, si rifiuta l'ipotesi nulla. Per essere statisticamente significativa
1 Craparo, Robert M. (2007). «Livello di significatività». In Salkind, Neil J. Enciclopedia della misurazione e della statistica 3. Thousand Oaks, CA: Pubblicazioni. pp. 889—891. SAGE ISBN1-412-91611-9.
Come si calcola la probabilità di questo risultato? Si utilizza la statistica χ 2 che fornisce distribuzioni molto ben studiate e può essere utilizzata per determinare la probabilità di ottenere un risultato così estremo o più estremo utilizzando questa formula.
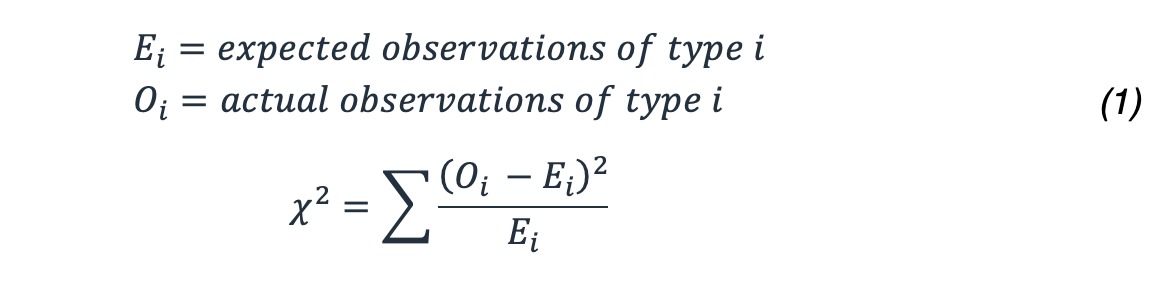
Nel nostro esempio, ciò si traduce in:

Quindi, cosa 6 significa in termini di probabilità? È necessario considerare una distribuzione chi-quadrata con il giusto grado di libertà. La figura seguente mostra diverse distribuzioni chi-squared per diversi gradi di libertà.
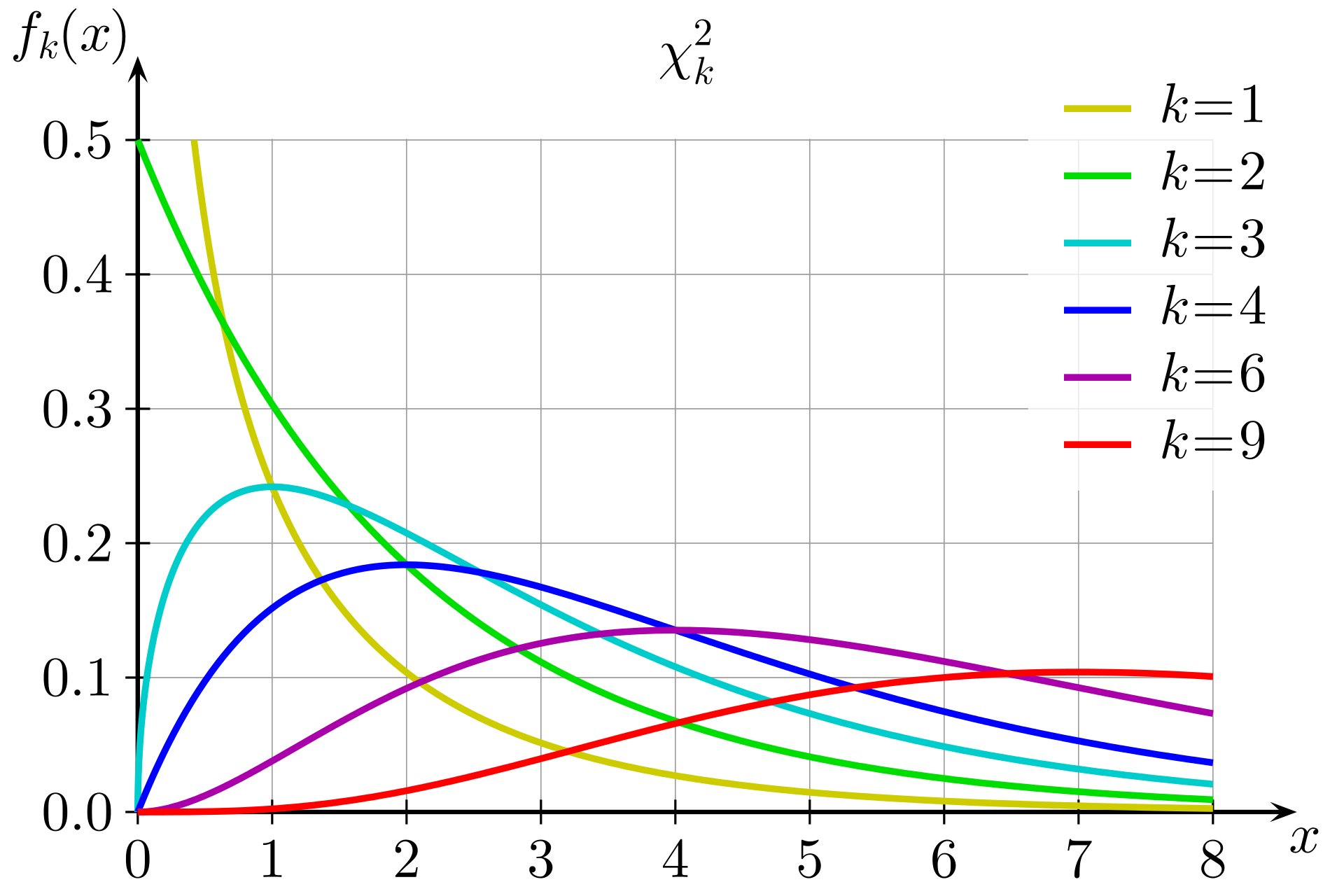
Distribuzioni chi-squared per diversi gradi di libertà
Il grado di libertà viene calcolato come uno in meno rispetto al numero di scelte del test. In questo caso, poiché vi sono quattro zone di disponibilità, il grado di libertà è tre. Quindi, vuoi conoscere l'area sotto la curva (l'integrale) per x ≥ 6 sul grafico k = 3. È inoltre possibile utilizzare una tabella precalcolata con valori di uso comune per approssimare tale valore.
Tabella 2: Valori critici al quadrato di Chi
| Gradi di libertà | Probabilità inferiore al valore critico | ||||
|---|---|---|---|---|---|
| 0,75 | 0,90 | 0,95 | 0,99 | 0,999 | |
| 1 | 1,323 | 2,706 | 3,841 | 6,635 | 10,828 |
| 2 | 2,773 | 4,605 | 5,991 | 9,210 | 13,816 |
| 3 | 4,108 | 6,251 | 7,815 | 11,345 | 16,266 |
| 4 | 5,385 | 7,779 | 9,488 | 13,277 | 18,467 |
Per tre gradi di libertà, il valore chi-quadrato di sei rientra tra le colonne di probabilità 0,75 e 0,9. Ciò significa che esiste una probabilità superiore al 10% che si verifichi questa distribuzione, che non è inferiore alla soglia del 5%. Pertanto, si accetta l'ipotesi nulla e si stabilisce che non vi è una differenza statisticamente significativa nei tassi di errore tra le zone di disponibilità.
L'esecuzione di un test di statistica chi-squared non è supportata nativamente nella matematica CloudWatch metrica, quindi dovrai raccogliere le metriche di errore applicabili CloudWatch ed eseguire il test in un ambiente di calcolo come Lambda. Puoi decidere di eseguire questo test a livello di MVC Controller/Action o di microservizio individuale oppure a livello di zona di disponibilità. Dovrai valutare se una compromissione della zona di disponibilità influirebbe allo stesso modo su ogni controller/azione o microservizio o se qualcosa come un DNS guasto potrebbe avere un impatto su un servizio a basso throughput e non su un servizio a throughput elevato, che potrebbe mascherare l'impatto se aggregato. In entrambi i casi, selezionate le dimensioni appropriate per creare la query. Il livello di granularità influirà anche sugli CloudWatch allarmi risultanti che creerai.
Raccogli la metrica del conteggio degli errori per ogni AZ e Controller/Action in una finestra temporale specificata. Innanzitutto, calcola il risultato del test chi-squared come vero (c'era un'inclinazione statisticamente significativa) o falso (non c'era, cioè vale l'ipotesi nulla). Se il risultato è falso, pubblica un punto di dati pari a 0 nel flusso di metriche per i risultati chi-squared per ogni zona di disponibilità. Se il risultato è vero, pubblica un punto dati 1 per la zona di disponibilità con gli errori più lontani dal valore previsto e uno 0 per gli altri (fare riferimento a Appendice B — Esempio di calcolo al quadrato per un codice di esempio che può essere utilizzato in una funzione Lambda). È possibile seguire lo stesso approccio dei precedenti allarmi di disponibilità utilizzando la creazione di un allarme CloudWatch metrico a 3 righe e un allarme CloudWatch metrico a 3 su 5 in base ai punti dati prodotti dalla funzione Lambda. Come negli esempi precedenti, questo approccio può essere modificato per utilizzare più o meno punti dati in una finestra più o meno lunga.
Quindi, aggiungete questi allarmi all'allarme di disponibilità esistente della zona di disponibilità per la combinazione Controller e Azione, mostrata nella figura seguente.

Integrazione del test statistico chi-squared con allarmi compositi
Come accennato in precedenza, quando si incorporano nuove funzionalità nel carico di lavoro, è sufficiente creare gli allarmi CloudWatch metrici appropriati specifici per quella nuova funzionalità e aggiornare il livello successivo nella gerarchia composita degli allarmi per includere tali allarmi. Il resto della struttura degli allarmi rimane statico.
