Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Disponibilità con ridondanza
Quando un carico di lavoro utilizza sottosistemi multipli, indipendenti e ridondanti, può raggiungere un livello di disponibilità teorica più elevato rispetto all'utilizzo di un singolo sottosistema. Ad esempio, si consideri un carico di lavoro composto da due sottosistemi identici. Può essere completamente operativo se è operativo il sottosistema uno o il sottosistema due. Affinché l'intero sistema sia inattivo, entrambi i sottosistemi devono essere disattivati contemporaneamente.
Se la probabilità di guasto di un sottosistema è 1 − α, allora la probabilità che due sottosistemi ridondanti siano inattivi contemporaneamente è il prodotto della probabilità di guasto di ciascun sottosistema, F = (1− α) × (1− α1). 2 Per un carico di lavoro con due sottosistemi ridondanti, utilizzando l'equazione (3), si ottiene una disponibilità definita come:
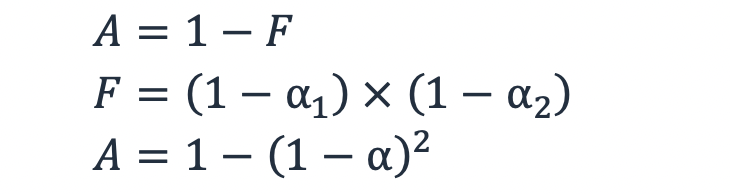
Equazione 5
Quindi, per due sottosistemi la cui disponibilità è del 99%, la probabilità che uno fallisca è dell'1% e la probabilità che entrambi falliscano è (1− 99%) × (1− 99%) = 0,01%. Ciò rende la disponibilità utilizzando due sottosistemi ridondanti del 99,99%.
Questo può essere generalizzato per incorporare anche ricambi ridondanti aggiuntivi. Nell'Equazione (5) abbiamo ipotizzato solo un singolo pezzo di riserva, ma un carico di lavoro potrebbe avere due, tre o più pezzi di riserva in modo da poter sopravvivere alla perdita simultanea di più sottosistemi senza influire sulla disponibilità. Se un carico di lavoro ha tre sottosistemi e due sono di riserva, la probabilità che tutti e tre i sottosistemi falliscano contemporaneamente è (1− α) × (1− α) × (1− α) o (1− α) 3. In generale, un carico di lavoro con s unità di riserva avrà esito negativo solo se i sottosistemi s+1 falliscono.
Per un carico di lavoro con n sottosistemi e s parti di riserva, f è il numero di modalità di errore o i modi in cui i sottosistemi s+1 possono fallire su n.
Questo è in effetti il teorema binomiale, la matematica combinatoria che consiste nello scegliere k elementi da un insieme di n, o «n sceglie k». In questo caso, k è s + 1.
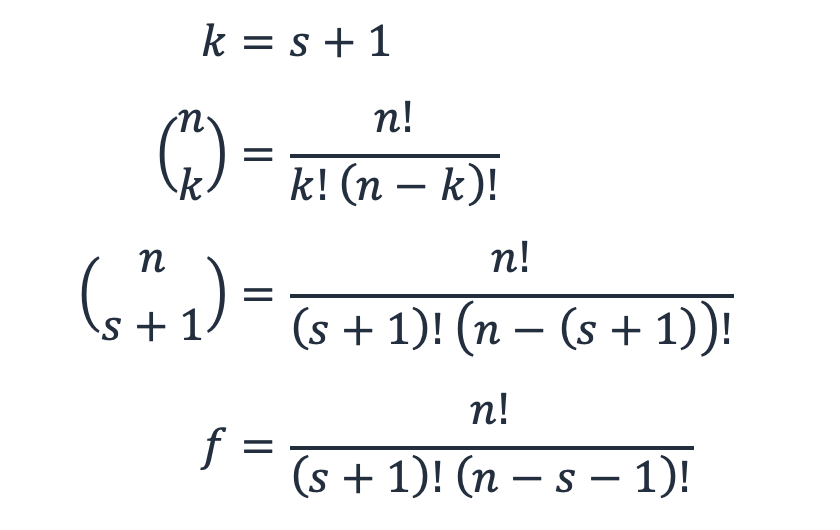
Equazione 6
Possiamo quindi produrre un'approssimazione della disponibilità generalizzata che incorpori il numero di modalità di guasto e il risparmio. (Per capire il motivo, in forma approssimativa, fate riferimento all'Appendice 2 di Highleyman, et al. Rompere la barriera
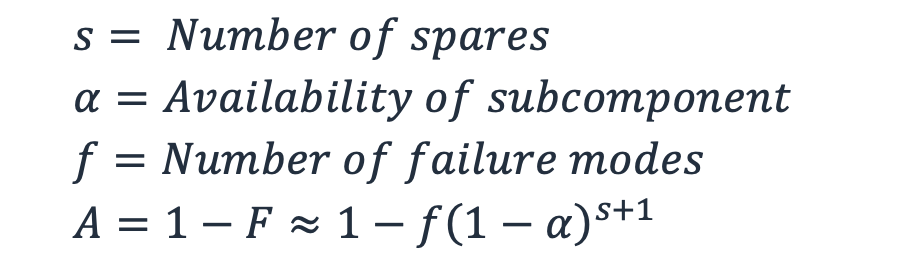
Equazione 7
Lo sparing può essere applicato a qualsiasi dipendenza che fornisca risorse che falliscono indipendentemente. Ne sono un esempio le istanze Amazon EC2 in diverse AZ o i bucket Amazon S3 in diverse aree. Regioni AWS L'utilizzo delle risorse di riserva aiuta tale dipendenza a raggiungere una maggiore disponibilità totale per supportare gli obiettivi di disponibilità del carico di lavoro.
Regola 5
Usa sparing per aumentare la disponibilità delle dipendenze in un carico di lavoro.
Tuttavia, il risparmio ha un costo. Ogni pezzo di ricambio aggiuntivo ha lo stesso costo del modulo originale, con un costo almeno lineare. La creazione di un carico di lavoro in grado di utilizzare parti di ricambio ne aumenta anche la complessità. Deve saper identificare i fallimenti legati alla dipendenza, assegnare un peso al lavoro e dedicarlo a una risorsa sana e gestire la capacità complessiva del carico di lavoro.
La ridondanza è un problema di ottimizzazione. Troppi pezzi di ricambio e il carico di lavoro può fallire più frequentemente del desiderato, troppe parti di ricambio e l'esecuzione del carico di lavoro costa troppo. Esiste una soglia oltre la quale l'aggiunta di ulteriori ricambi costerà più della disponibilità aggiuntiva garantita.
Utilizzando la nostra formula di disponibilità generale con ricambi, Equation (7), per un sottosistema con una disponibilità del 99,5%, con due unità di riserva la disponibilità del carico di lavoro è A ≈ 1 − (1) (1−.995) 3 = 99,9999875% (circa 3,94 secondi di inattività all'anno) e con 10 ricambi otteniamo A ≈ 1 − (1) (1−.995) = 11 25,5 9 ′ s (il tempo di inattività approssimativo sarebbe di 1,26252 × 10 −15 m s all'anno, in effetti 0). Confrontando questi due carichi di lavoro, abbiamo registrato un aumento di 5 volte del costo dello risparmio per ottenere quattro secondi di inattività in meno all'anno. Per la maggior parte dei carichi di lavoro, l'aumento dei costi sarebbe ingiustificato per questo aumento della disponibilità. La figura seguente mostra questa relazione.

Rendimenti decrescenti derivanti da un maggiore risparmio
Con tre ricambi di riserva e oltre, il risultato è una frazione di secondo dei tempi di inattività previsti all'anno, il che significa che dopo questo punto si raggiunge l'area dei rendimenti decrescenti. Potrebbe essere necessario «aggiungere altro» per raggiungere livelli di disponibilità più elevati, ma in realtà i vantaggi in termini di costi scompaiono molto rapidamente. L'utilizzo di più di tre pezzi di ricambio non offre un guadagno sostanziale e notevole per quasi tutti i carichi di lavoro quando il sottosistema stesso ha una disponibilità almeno del 99%.
Regola 6
Esiste un limite massimo all'efficienza in termini di costi del risparmio. Utilizzate il minor numero di ricambi necessario per ottenere la disponibilità richiesta.
È necessario considerare l'unità di guasto quando si seleziona il numero corretto di ricambi. Ad esempio, esaminiamo un carico di lavoro che richiede 10 istanze EC2 per gestire la capacità di picco e che vengono distribuite in un'unica AZ.
Poiché le AZ sono progettate per fungere da limiti di isolamento dei guasti, l'unità di errore non è solo una singola istanza EC2, poiché un'intera istanza EC2 può fallire insieme. In questo caso, ti consigliamo di aggiungere ridondanza con un'altra AZ, implementando 10 istanze EC2 aggiuntive per gestire il carico in caso di errore AZ, per un totale di 20 istanze EC2 (seguendo lo schema di stabilità statica).
Anche se sembrano essere 10 istanze EC2 di riserva, in realtà si tratta solo di una singola istanza AZ di riserva, quindi non abbiamo superato il limite di rendimenti decrescenti. Tuttavia, puoi essere ancora più efficiente in termini di costi e allo stesso tempo aumentare la disponibilità utilizzando tre AZ e implementando cinque istanze EC2 per AZ.
Ciò fornisce una zona di emergenza con un totale di 15 istanze EC2 (rispetto a due AZ con 20 istanze), fornendo comunque le 10 istanze totali necessarie per soddisfare la massima capacità durante un evento che ha un impatto su una singola AZ. Pertanto, è necessario incorporare sparing per garantire la tolleranza agli errori in tutti i limiti di isolamento dei guasti utilizzati dal carico di lavoro (istanza, cella, AZ e regione).
