Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Disponibilità del sistema distribuito
I sistemi distribuiti sono costituiti sia da componenti software che da componenti hardware. Alcuni componenti software potrebbero essere essi stessi un altro sistema distribuito. La disponibilità dei componenti hardware e software sottostanti influisce sulla conseguente disponibilità del carico di lavoro.
Il calcolo della disponibilità mediante MTBF e MTTR affonda le sue radici nei sistemi hardware. Tuttavia, i sistemi distribuiti falliscono per ragioni molto diverse rispetto a quelle di un componente hardware. Se un produttore è in grado di calcolare in modo coerente il tempo medio che precede l'usura di un componente hardware, gli stessi test non possono essere applicati ai componenti software di un sistema distribuito. L'hardware segue in genere una curva approssimativa del tasso di guasto, mentre il software segue una curva sfalsata causata da difetti aggiuntivi che vengono introdotti con ogni nuova versione (vedi Affidabilità del software
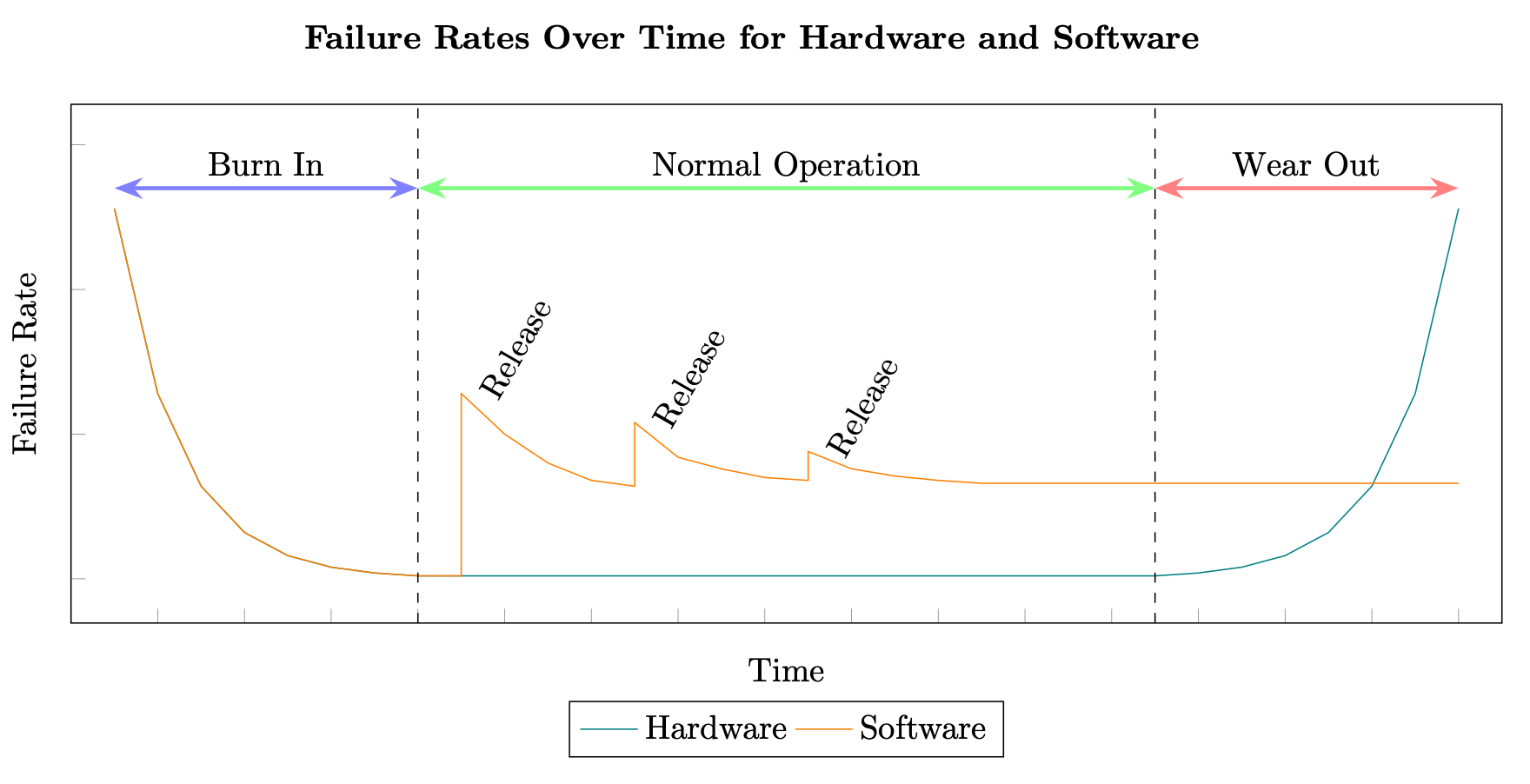
Percentuali di guasti hardware e software
Inoltre, il software nei sistemi distribuiti cambia in genere a velocità esponenzialmente superiori a quelle dell'hardware. Ad esempio, un disco rigido magnetico standard potrebbe avere un tasso di guasto annualizzato medio (AFR) dello 0,93% che, in pratica per un HDD, può significare una durata di almeno 3-5 anni prima che raggiunga il periodo di usura, potenzialmente più lungo (vedi Backblaze Hard Drive Data and Stats, 2020).
L'hardware è inoltre soggetto al concetto di obsolescenza pianificata, ossia ha una durata di vita incorporata e dovrà essere sostituito dopo un certo periodo di tempo. (Vedi The Great
Tutto ciò significa che gli stessi modelli di test e previsione utilizzati per l'hardware per generare i numeri MTBF e MTTR non si applicano al software. Ci sono stati centinaia di tentativi di creare modelli per risolvere questo problema a partire dagli anni '70, ma generalmente rientrano tutti in due categorie: modelli di previsione e modelli di stima. (Vedi Elenco dei modelli di affidabilità del software
Pertanto, il calcolo di un MTBF e di un MTTR lungimiranti per sistemi distribuiti, e quindi di una disponibilità previsionale, sarà sempre derivato da qualche tipo di previsione o previsione. Possono essere generati mediante modellazione predittiva, simulazione stocastica, analisi storica o test rigorosi, ma tali calcoli non garantiscono tempi di attività o tempi di inattività.
I motivi per cui un sistema distribuito ha fallito in passato potrebbero non ripresentarsi mai. Le ragioni per cui fallirà in futuro saranno probabilmente diverse e forse inconoscibili. I meccanismi di ripristino necessari potrebbero inoltre essere diversi per i guasti futuri rispetto a quelli utilizzati in passato e richiedere tempi significativamente diversi.
Inoltre, MTBF e MTTR sono valori medi. Ci sarà una certa varianza tra il valore medio e i valori effettivi visti (la deviazione standard, ₂, misura questa variazione). Pertanto, i carichi di lavoro possono trascorrere un periodo di tempo più o meno lungo tra i guasti e i tempi di ripristino nell'effettivo utilizzo in produzione.
Detto questo, la disponibilità dei componenti software che costituiscono un sistema distribuito è ancora importante. Il software può fallire per numerose ragioni (discusse più approfonditamente nella prossima sezione) e influire sulla disponibilità del carico di lavoro. Pertanto, per i sistemi distribuiti ad alta disponibilità, occorre prestare la stessa attenzione al calcolo, alla misurazione e al miglioramento della disponibilità dei componenti software per quanto riguarda l'hardware e i sottosistemi software esterni.
Regola 2
La disponibilità del software nel carico di lavoro è un fattore importante della disponibilità complessiva del carico di lavoro e dovrebbe ricevere la stessa attenzione degli altri componenti.
È importante notare che, nonostante MTBF e MTTR siano difficili da prevedere per i sistemi distribuiti, forniscono comunque informazioni chiave su come migliorare la disponibilità. La riduzione della frequenza dei guasti (MTBF più elevato) e la riduzione del tempo di ripristino dopo il verificarsi del guasto (MTTR inferiore) porteranno entrambe a una maggiore disponibilità empirica.
Tipi di guasti nei sistemi distribuiti
Esistono generalmente due classi di bug nei sistemi distribuiti che influiscono sulla disponibilità, chiamate affettuosamente Bohrbug e Heisenbug (vedi «A Conversation with Bruce Lindsay», ACM Queue vol. 2,
Un Bohrbug è un problema software funzionale ripetibile. Con lo stesso input, il bug produrrà costantemente lo stesso output errato (come il modello atomico deterministico di Bohr, che è solido e facilmente rilevabile). Questi tipi di bug sono rari quando un carico di lavoro entra in produzione.
Un Heisenbug è un bug transitorio, il che significa che si verifica solo in condizioni specifiche e non comuni. Queste condizioni sono in genere correlate a fattori come l'hardware (ad esempio, un guasto temporaneo del dispositivo o specifiche dell'implementazione hardware come la dimensione del registro), le ottimizzazioni del compilatore e l'implementazione del linguaggio, le condizioni limite (ad esempio, l'esaurimento temporaneo dello spazio di archiviazione) o le condizioni di gara (ad esempio, il mancato utilizzo di un semaforo per operazioni multithread).
Gli Heisenbug costituiscono la maggior parte dei bug in produzione e sono difficili da trovare perché sono sfuggenti e sembrano cambiare comportamento o scomparire quando si tenta di osservarli o eseguirne il debug. Tuttavia, se si riavvia il programma, è probabile che l'operazione fallita abbia successo perché l'ambiente operativo è leggermente diverso, eliminando le condizioni che hanno introdotto l'Heisenbug.
Pertanto, la maggior parte degli errori di produzione sono transitori e quando l'operazione viene ritentata, è improbabile che si verifichi nuovamente un errore. Per essere resilienti, i sistemi distribuiti devono essere tolleranti ai guasti nei confronti di Heisenbugs. Scopriremo come raggiungere questo obiettivo nella sezione Incrementare l'MTBF dei sistemi distribuiti.
