Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Misurazione della disponibilità
Come abbiamo visto in precedenza, creare un modello di disponibilità lungimirante per un sistema distribuito è difficile e potrebbe non fornire le informazioni desiderate. Ciò che può fornire maggiore utilità è lo sviluppo di metodi coerenti per misurare la disponibilità del carico di lavoro.
La definizione di disponibilità come uptime e downtime rappresenta un errore come opzione binaria, a prescindere dal fatto che il carico di lavoro sia attivo o meno.
Tuttavia, questo è raramente il caso. L'errore ha un certo impatto e si verifica spesso in alcuni sottoinsiemi del carico di lavoro, influendo su una percentuale di utenti o richieste, su una percentuale di sedi o su un percentile di latenza. Queste sono tutte modalità di guasto parziale.
E sebbene MTTR e MTBF siano utili per comprendere cosa determina la disponibilità risultante di un sistema e, quindi, come migliorarlo, la loro utilità non è una misura empirica della disponibilità. Inoltre, i carichi di lavoro sono composti da molti componenti. Ad esempio, un carico di lavoro come un sistema di elaborazione dei pagamenti è costituito da molte interfacce di programmazione delle applicazioni (API) e sottosistemi. Quindi, quando vogliamo porre una domanda del tipo «qual è la disponibilità dell'intero carico di lavoro?» , in realtà è una domanda complessa e ricca di sfumature.
In questa sezione, esamineremo tre modi in cui è possibile misurare empiricamente la disponibilità: percentuale di successo delle richieste lato server, percentuale di successo delle richieste lato client e tempi di inattività annuali.
Percentuale di successo delle richieste lato server e lato client
I primi due metodi sono molto simili, differiscono solo dal punto di vista della misurazione effettuata. Le metriche lato server possono essere raccolte dalla strumentazione del servizio. Tuttavia, non sono completi. Se i clienti non sono in grado di accedere al servizio, non puoi raccogliere tali metriche. Per comprendere l'esperienza del cliente, invece di affidarsi alla telemetria dei clienti per le richieste non riuscite, un modo più semplice per raccogliere dati sul lato client consiste nel simulare il traffico dei clienti con canarini, un software che analizza regolarmente i servizi e registra le metriche.
Questi due metodi calcolano la disponibilità come la frazione del totale delle unità di lavoro valide che il servizio riceve e quelle elaborate correttamente (questo ignora le unità di lavoro non valide, come una richiesta HTTP che genera un errore 404).

Equazione 8
Per un servizio basato su richieste, l'unità di lavoro è la richiesta, come una richiesta HTTP. Per i servizi basati su eventi o attività, le unità di lavoro sono eventi o attività, come l'elaborazione di un messaggio da una coda. Questa misura della disponibilità è utile in brevi intervalli di tempo, come finestre di un minuto o cinque minuti. È anche più adatto da una prospettiva granulare, ad esempio a livello di API per un servizio basato su richiesta. La figura seguente fornisce una panoramica di come potrebbe apparire la disponibilità nel tempo se calcolata in questo modo. Ogni data point sul grafico viene calcolato utilizzando l'equazione (8) in una finestra di cinque minuti (puoi scegliere altre dimensioni temporali come intervalli di un minuto o dieci minuti). Ad esempio, il punto dati 10 mostra una disponibilità del 94,5%. Ciò significa che, nei minuti da t+45 a t+50, se il servizio ha ricevuto 1.000 richieste, solo 945 di esse sono state elaborate correttamente.
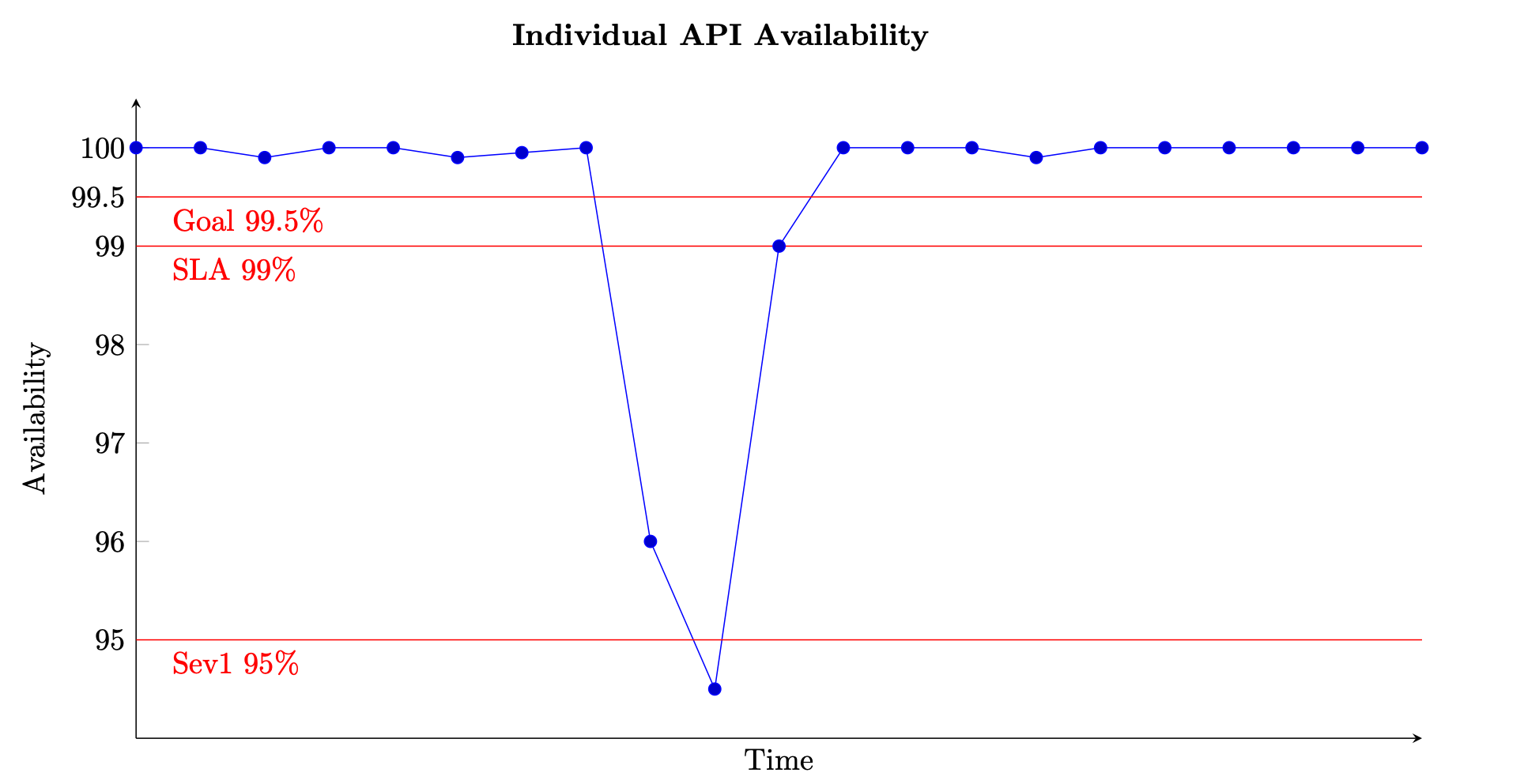
Esempio di misurazione della disponibilità nel tempo per una singola API
Il grafico mostra anche l'obiettivo di disponibilità dell'API, la disponibilità del 99,5%, il contratto sul livello di servizio (SLA) offerto ai clienti, la disponibilità del 99% e la soglia per un allarme ad alta gravità, il 95%. Senza il contesto di queste diverse soglie, un grafico della disponibilità potrebbe non fornire informazioni significative sul funzionamento del servizio.
Vogliamo anche essere in grado di tracciare e descrivere la disponibilità di un sottosistema più grande, come un piano di controllo o un intero servizio. Un modo per farlo consiste nel calcolare la media di ogni data point di cinque minuti per ogni sottosistema. Il grafico sarà simile a quello precedente, ma sarà rappresentativo di un insieme più ampio di input. Assegna inoltre lo stesso peso a tutti i sottosistemi che costituiscono il servizio. Un approccio alternativo potrebbe consistere nel sommare tutte le richieste ricevute ed elaborate con successo da tutte le API del servizio per calcolare la disponibilità a intervalli di cinque minuti.
Tuttavia, quest'ultimo metodo potrebbe nascondere una singola API con una velocità effettiva ridotta e una scarsa disponibilità. Come semplice esempio, considera un servizio con due API.
La prima API riceve 1.000.000 di richieste in una finestra di cinque minuti e ne elabora con successo 999.000, con una disponibilità del 99,9%. La seconda API riceve 100 richieste nella stessa finestra di cinque minuti e ne elabora correttamente solo 50, garantendo una disponibilità del 50%.
Se sommiamo le richieste di ciascuna API, ci sono 1.000.100 richieste valide totali e 999.050 di esse vengono elaborate correttamente, con una disponibilità complessiva del servizio del 99,895%. Tuttavia, se calcoliamo la media delle disponibilità delle due API, secondo il primo metodo, otteniamo una disponibilità del 74,95%, che potrebbe essere più indicativa dell'esperienza effettiva.
Nessuno dei due approcci è sbagliato, ma dimostra l'importanza di capire cosa ci dicono le metriche di disponibilità. Puoi scegliere di preferire la somma delle richieste per tutti i sottosistemi se il tuo carico di lavoro riceve un volume di richieste simile per ognuno di essi. Questo approccio si concentra sulla «richiesta» e sul suo successo come misura della disponibilità e dell'esperienza del cliente. In alternativa, è possibile scegliere di calcolare la disponibilità media dei sottosistemi per rappresentarne equamente la criticità nonostante le differenze nel volume delle richieste. Questo approccio si concentra sul sottosistema e sulla capacità di ciascuno di essi come indicatore dell'esperienza del cliente.
Tempo di inattività annuale
Il terzo approccio consiste nel calcolare i tempi di inattività annuali. Questa forma di metrica della disponibilità è più appropriata per la definizione e la revisione degli obiettivi a lungo termine. È necessario definire il significato dei tempi di inattività per il carico di lavoro. È quindi possibile misurare la disponibilità in base al numero di minuti in cui il carico di lavoro non è stato in condizioni di «interruzione» rispetto al numero totale di minuti in un determinato periodo.
Alcuni carichi di lavoro potrebbero essere in grado di definire il downtime come una riduzione della disponibilità al di sotto del 95% di una singola API o funzione di carico di lavoro per un intervallo di un minuto o cinque minuti (come nel precedente grafico della disponibilità). È inoltre possibile considerare i tempi di inattività solo in quanto si applicano a un sottoinsieme di operazioni critiche sul piano dati. Ad esempio, il contratto sul livello di servizio di Amazon Messaging (SQS, SNS)
Carichi di lavoro più grandi e complessi potrebbero dover definire metriche di disponibilità a livello di sistema. Per un sito di e-commerce di grandi dimensioni, una metrica a livello di sistema può essere qualcosa come la percentuale degli ordini dei clienti. In questo caso, un calo del 10% o più degli ordini rispetto alla quantità prevista durante qualsiasi finestra di cinque minuti può determinare i tempi di inattività.
In entrambi gli approcci, è quindi possibile sommare tutti i periodi di interruzione per calcolare una disponibilità annuale. Ad esempio, se durante un anno solare si sono verificati 27 periodi di inattività da cinque minuti, definiti come la disponibilità di qualsiasi API del piano dati che scende al di sotto del 95%, il tempo di inattività complessivo è stato di 135 minuti (alcuni periodi di cinque minuti potrebbero essere stati consecutivi, altri isolati), con una disponibilità annua del 99,97%.
Questo metodo aggiuntivo di misurazione della disponibilità può fornire dati e informazioni mancanti nelle metriche lato client e lato server. Ad esempio, si consideri un carico di lavoro ridotto e con tassi di errore significativamente elevati. I clienti con questo carico di lavoro potrebbero smettere del tutto di effettuare chiamate ai suoi servizi. Forse hanno attivato un interruttore automatico o hanno seguito il piano di disaster recovery
Latenza
Infine, è anche importante misurare la latenza delle unità di lavoro di elaborazione all'interno del carico di lavoro. Parte della definizione di disponibilità consiste nell'eseguire il lavoro nell'ambito di uno SLA stabilito. Se la restituzione di una risposta richiede più tempo del timeout del client, il client ha la percezione che la richiesta sia fallita e il carico di lavoro non sia disponibile. Tuttavia, sul lato server, la richiesta potrebbe sembrare essere stata elaborata correttamente.
La misurazione della latenza fornisce un'altra lente con cui valutare la disponibilità. L'uso dei percentili e della media ridotta sono buone statistiche per questa misurazione. Sono comunemente misurati al 50° percentile (P50 e TM50) e al 99° percentile (P99 e TM99). La latenza deve essere misurata con canarini per rappresentare l'esperienza del cliente e con metriche lato server. Ogni volta che la media di una latenza percentile, come P99 o TM99.9, supera lo SLA target, puoi considerare il tempo di inattività, che contribuisce al calcolo dei tempi di inattività annuali.
