Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Affidabilità
Definizione
L'affidabilità si riferisce alla capacità di un servizio o di un sistema di svolgere la funzione prevista quando richiesto. L'affidabilità di un sistema può essere misurata in base al livello della sua qualità operativa entro un determinato periodo di tempo. Paragonalo alla resilienza, che si riferisce alla capacità di un sistema di riprendersi da interruzioni dell'infrastruttura o del servizio, in modo dinamico e affidabile.
Per maggiori dettagli su come la disponibilità e la resilienza vengono utilizzate per misurare l'affidabilità, consulta il Reliability Pillar del Well-Architected AWS Framework.
Domande chiave
Disponibilità
La disponibilità è la percentuale di tempo per cui un carico di lavoro è disponibile per l'uso. Gli obiettivi comuni includono il 99% (3,65 giorni di inattività consentiti all'anno), il 99,9% (8,77 ore) e il 99,99% (52,6 minuti), con un'abbreviazione del numero di nove nella percentuale («due nove» per il 99%, «tre nove» per il 99,9% e così via). La disponibilità della soluzione di rete tra AWS e il data center locale può essere diversa dalla disponibilità complessiva della soluzione o dell'applicazione.
Le domande chiave sulla disponibilità di una soluzione di rete includono:
-
Le mie AWS risorse possono continuare a funzionare se non riescono a comunicare con le mie risorse locali? Viceversa?
-
Devo considerare i tempi di inattività programmati per la manutenzione pianificata inclusi o esclusi dalla metrica di disponibilità?
-
Come posso misurare la disponibilità del livello di rete, indipendentemente dallo stato generale delle applicazioni?
La sezione Availability del Well-Architected Framework Reliability Pillar contiene suggerimenti e formule per la disponibilità dei calcoli.
Resilienza
La resilienza è la capacità di un carico di lavoro di ripristinarsi a seguito di interruzioni dell'infrastruttura o del servizio, acquisire in modo dinamico le risorse di calcolo per soddisfare la domanda e mitigare le interruzioni, quali configurazioni errate o problemi di rete transitori. Se un componente di rete ridondante (collegamento, dispositivi di rete e così via) non dispone di una disponibilità sufficiente per fornire da solo la funzione prevista, ha una bassa resilienza ai guasti. La conseguenza è un'esperienza utente scadente e degradata.
Le domande chiave per la resilienza di una soluzione di rete includono:
-
Quanti guasti simultanei e discreti devo consentire?
-
Come posso ridurre i singoli punti di errore sia con le soluzioni di connettività che con la mia rete interna?
-
Qual è la mia vulnerabilità agli eventi Distributed Denial of Service (DDoS)?
Soluzione tecnica
Innanzitutto, è importante notare che non tutte le soluzioni di connettività di rete ibrida richiedono un elevato livello di affidabilità e che livelli crescenti di affidabilità comportano un corrispondente aumento dei costi. In alcuni scenari, un sito primario può richiedere connessioni affidabili (ridondanti e resilienti) poiché i tempi di inattività hanno un impatto maggiore sull'attività, mentre i siti regionali potrebbero non richiedere lo stesso livello di affidabilità a causa del minore impatto sull'attività in caso di guasto. Si consiglia di fare riferimento alle raccomandazioni sulla AWS Direct Connect resilienza
Per ottenere una soluzione di connettività di rete ibrida affidabile nel contesto della resilienza, la progettazione deve prendere in considerazione i seguenti aspetti:
-
Ridondanza: mira a eliminare ogni singolo punto di errore nel percorso di connettività di rete ibrida, inclusi, a titolo esemplificativo, le connessioni di rete, i dispositivi di rete periferici, la ridondanza tra le zone di disponibilità e le posizioni DX Regioni AWS, le fonti di alimentazione dei dispositivi, i percorsi in fibra e i sistemi operativi. Per lo scopo e l'ambito di questo white paper, la ridondanza si concentra sulle connessioni di rete, sui dispositivi periferici (ad esempio, i dispositivi gateway del cliente), sulla posizione AWS DX e Regioni AWS (per le architetture multiregionali).
-
Componenti di failover affidabili: in alcuni scenari, un sistema potrebbe funzionare, ma non svolgere le sue funzioni al livello richiesto. Una situazione di questo tipo è comune nel caso di un singolo evento di guasto, in cui si scopre che i componenti ridondanti pianificati funzionavano in modo non ridondante: il carico di rete non ha altro a cui rivolgersi a causa dell'utilizzo, il che si traduce in una capacità insufficiente per l'intera soluzione.
-
Tempo di failover: il tempo di failover è il tempo impiegato da un componente secondario per assumere completamente il ruolo di componente principale. Il tempo di failover è legato a diversi fattori: il tempo necessario per rilevare l'errore, il tempo necessario per abilitare la connettività secondaria e il tempo necessario per notificare la modifica al resto della rete. Il rilevamento degli errori può essere migliorato utilizzando Dead Peer Detection (DPD) per VPN i link e Bidirectional Forwarding Detection () per i link. BFD AWS Direct Connect Il tempo necessario per abilitare la connettività secondaria può essere molto breve (se queste connessioni sono sempre attive), può essere breve (se è necessario abilitare una VPN connessione preconfigurata) o più lungo (se è necessario spostare risorse fisiche o configurare nuove risorse). La notifica al resto della rete avviene in genere tramite protocolli di routing all'interno della rete del cliente, ognuno dei quali ha tempi di convergenza e opzioni di configurazione diversi: la configurazione di questi non rientra nell'ambito di questo white paper.
-
Ingegneria del traffico: l'ingegneria del traffico nel contesto della progettazione resiliente della connettività di rete ibrida mira a definire il modo in cui il traffico dovrebbe fluire su più connessioni disponibili in scenari normali e di guasto. Si consiglia di seguire il concetto di progettazione in caso di errore, in cui è necessario esaminare come funzionerà la soluzione in diversi scenari di errore e se sarà accettabile per l'azienda o meno. Questa sezione illustra alcuni dei casi d'uso più comuni di ingegneria del traffico che mirano a migliorare il livello di resilienza complessivo della soluzione di connettività di rete ibrida. La AWS Direct Connect sezione dedicata al routing BGP illustra diverse opzioni di ingegneria del traffico per influenzare il flusso del traffico (comunità, preferenze BGP locali, lunghezza del percorso AS). Per progettare una soluzione di ingegneria del traffico efficace, è necessario avere una buona conoscenza di come ciascuno dei componenti di AWS rete gestisce il routing IP in termini di valutazione e selezione del percorso, nonché dei possibili meccanismi per influenzare la selezione del percorso. I dettagli in merito non rientrano nell'ambito di questo documento. Per ulteriori informazioni, consulta Transit Gateway Route Evaluation Order, Site-to-Site VPNRoute Priority e Direct Connect Routing e BGP la documentazione necessaria.
Nota
Nella tabella delle VPC rotte, è possibile fare riferimento a un elenco di prefissi che contiene regole di selezione delle rotte aggiuntive. Per ulteriori informazioni su questo caso d'uso, consulta la priorità delle rotte per gli elenchi di prefissi. AWS Transit Gateway Le tabelle di routing supportano anche gli elenchi di prefissi, ma una volta applicate vengono estese a voci di percorso specifiche.
Esempio di Site-to-Site VPN connessioni doppie con percorsi più specifici
Questo scenario si basa su un piccolo sito locale che si connette a un unico Regione AWS sito tramite VPN connessioni ridondanti via Internet a. AWS Transit Gateway Il progetto di ingegneria del traffico illustrato nella Figura 10 mostra che con l'ingegneria del traffico è possibile influenzare la selezione del percorso che aumenta l'affidabilità della soluzione di connettività ibrida mediante:
-
Connettività ibrida resiliente: tutte VPN le connessioni ridondanti offrono la stessa capacità prestazionale, supportano il failover automatico utilizzando il protocollo di routing dinamico (BGP) e velocizzano il rilevamento degli errori di connessione utilizzando il rilevamento «dead peer». VPN
-
Efficienza delle prestazioni: la configurazione ECMP su entrambe le VPN connessioni AWS Transit Gateway aiuta a massimizzare la larghezza di banda complessiva della connessione. VPN In alternativa, pubblicizzando percorsi diversi e più specifici insieme al percorso di riepilogo del sito, è possibile gestire il carico in modo indipendente tra le due connessioni VPN
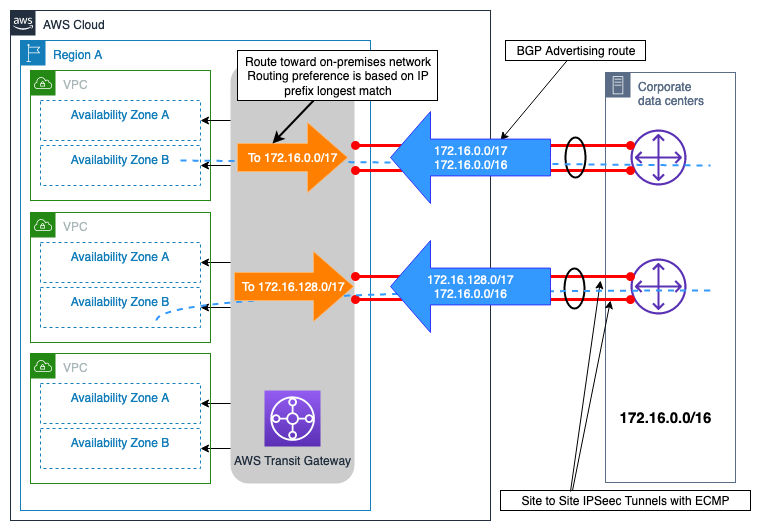
Figura 10 — Esempio di Site-to-Site VPN connessioni doppie con percorsi più specifici
Esempio di due siti locali con più connessioni DX
Lo scenario illustrato nella Figura 11 mostra due siti di data center locali situati in diverse regioni geografiche e collegati tramite il modello di connettività Maximum Resiliency (descritto nelle Raccomandazioni sulla AWS Direct Connect resilienza
Associando gli attributi BGP Community alle rotte pubblicizzate AWS DXGW, è possibile influenzare lateralmente la selezione del percorso di uscita. AWS DXGW Questi attributi comunitari controllano AWS l'attributo BGP Local Preference assegnato al percorso pubblicizzato. Per ulteriori informazioni, consulta le politiche e le AWS community di DX Routing. BGP
Per massimizzare l'affidabilità della connettività a Regione AWS livello, ogni coppia di connessioni AWS DX viene configurata in ECMP modo che entrambe possano essere utilizzate contemporaneamente per il trasferimento di dati tra ogni sito locale e. AWS
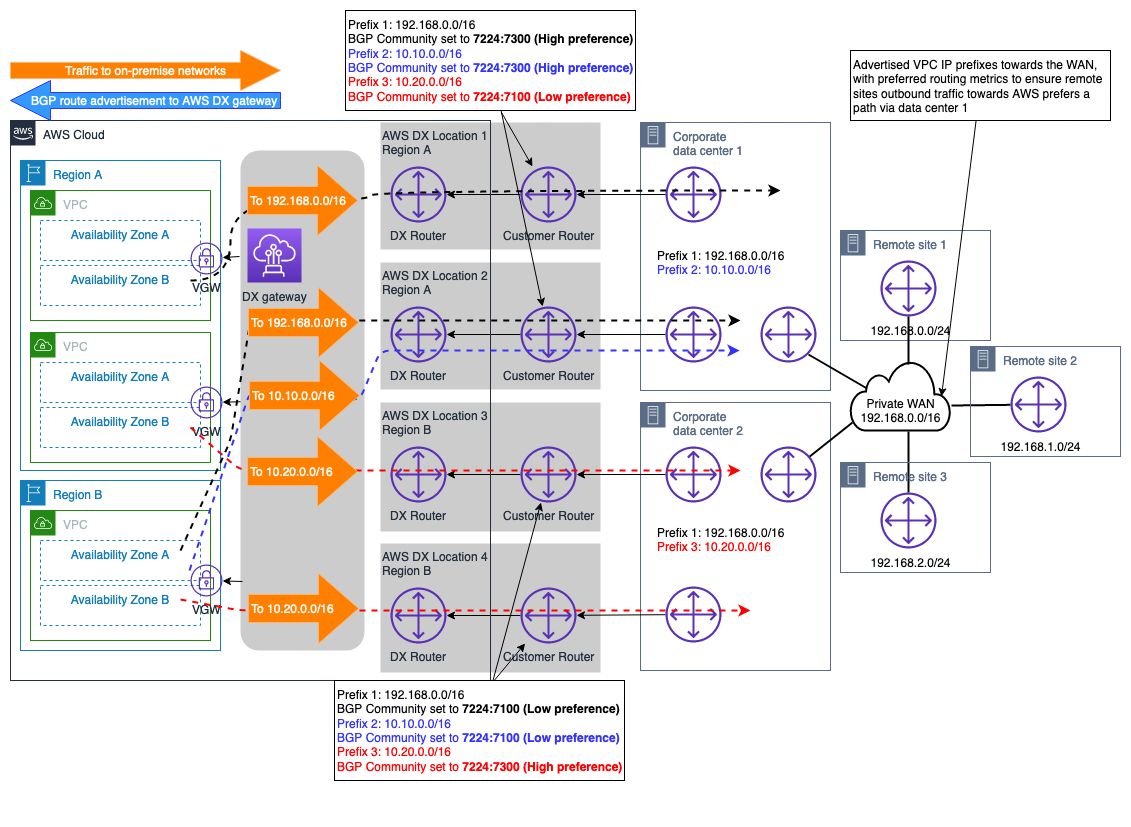
Figura 11 — Esempio di due siti locali con più connessioni DX
Con questo design, i flussi di traffico destinati alle reti locali (con la stessa lunghezza del prefisso e la stessa BGP community pubblicizzati) verranno distribuiti tra le doppie connessioni DX utilizzate dal sito. ECMP Tuttavia, se non ECMP è richiesto attraverso la connessione DX, lo stesso concetto discusso in precedenza e descritto nella documentazione BGPsulle politiche e le comunità di routing può essere utilizzato per progettare ulteriormente la selezione del percorso a livello di connessione DX.
Nota: se nel percorso all'interno dei data center locali sono presenti dispositivi di sicurezza, questi dispositivi devono essere configurati per consentire ai flussi di traffico in uscita da un collegamento DX e provenienti da un altro collegamento DX (entrambi i collegamenti utilizzatiECMP) all'interno dello stesso sito del data center.
VPNconnessione come esempio di connessione di backup a DX AWS
VPNpuò essere selezionato per fornire una connessione di rete di backup a una AWS Direct Connect connessione. In genere, questo tipo di modello di connettività è determinato dal costo, in quanto offre un livello di affidabilità inferiore alla soluzione complessiva di connettività ibrida a causa delle prestazioni indeterministiche su Internet, e non SLA è possibile ottenere una connessione tramite la rete Internet pubblica. È un modello di connettività valido ed economico e deve essere utilizzato quando il costo è la priorità assoluta e il budget è limitato, o magari come soluzione provvisoria fino al provisioning di un DX secondario. La Figura 12 illustra la progettazione di questo modello di connettività. Una considerazione fondamentale di questa progettazione, in cui entrambe le connessioni VPN e DX terminano in corrispondenza del AWS Transit Gateway, è che la VPN connessione può annunciare un numero maggiore di rotte rispetto a quelle che possono essere pubblicizzate tramite una connessione DX a cui è connessa. AWS Transit Gateway Ciò può causare una situazione di routing non ottimale. Un'opzione per risolvere questo problema consiste nel configurare il filtraggio delle rotte sul dispositivo gateway del cliente (CGW) per le rotte ricevute dalla VPN connessione, consentendo l'accettazione solo delle rotte di riepilogo.
Nota: per creare il percorso di riepilogo su AWS Transit Gateway, è necessario specificare un percorso statico verso un allegato arbitrario nella tabella delle rotte in modo che il riepilogo venga inviato lungo il AWS Transit Gateway percorso più specifico.
Dal punto di vista della tabella di AWS Transit Gateway routing, le rotte per il prefisso locale vengono ricevute sia dalla connessione AWS DX (viaDXGW) che daVPN, con la stessa lunghezza del prefisso. Seguendo la logica di priorità del percorso di AWS Transit Gateway, le rotte ricevute tramite Direct Connect hanno una preferenza maggiore rispetto a quelle ricevute su Site-to-SiteVPN, e quindi il percorso su di AWS Direct Connect sarà il preferito per raggiungere le reti locali.
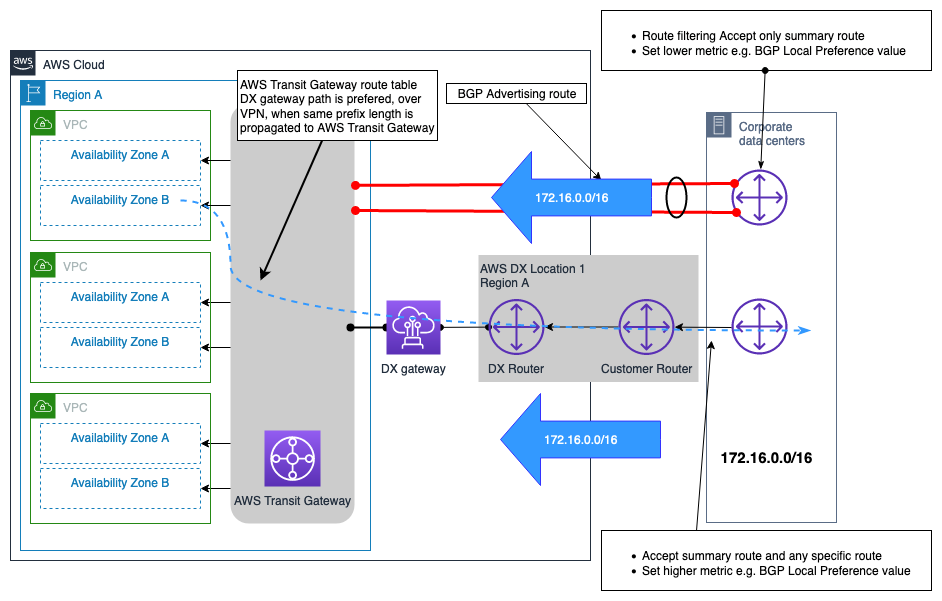
Figura 12 — esempio di VPN connessione come backup su AWS DX
Il seguente albero decisionale guida l'utente nel prendere la decisione desiderata per ottenere una connettività di rete ibrida resiliente (che si tradurrà in una connettività di rete ibrida affidabile). Per ulteriori informazioni, consulta AWS Direct Connect Resiliency Toolkit.
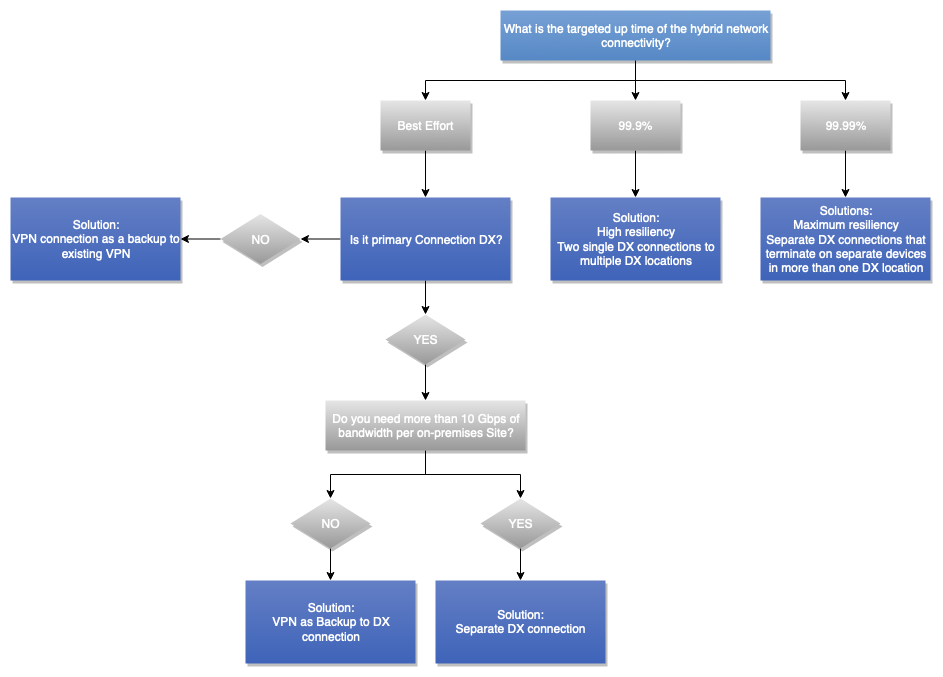
Figura 13 — Albero decisionale sull'affidabilità
