Fase 4: valutazione dei predittori
Un tipico flusso di lavoro nel machine learning consiste nell'addestrare un set di modelli o una combinazione di modelli su un set di addestramento e quindi valutarne la precisione su un set di dati di controllo. Questa sezione spiega come dividere i dati cronologici e quali metriche usare per valutare i modelli nella previsione di serie temporali. Per la previsione, la tecnica del backtesting è lo strumento principale per valutare la precisione delle previsioni.
Backtesting
Un framework di valutazione e backtesting adeguato è tra i fattori più importanti per realizzare un'applicazione di machine learning di successo. Puoi usare test retrospettivi efficaci con i tuoi modelli per acquisire familiarità con le capacità predittive future dei modelli. Inoltre, puoi ottimizzare i modelli tramite l'ottimizzazione degli iperparametri, apprendere le combinazioni dei modelli e abilitare il meta-learning e AutoML.
La caratteristica tempo della previsione di serie temporali si distingue in termini di metodologia di valutazione e backtesting dagli altri campi di applicazione del machine learning. In genere, nelle attività di machine learning per valutare l'errore predittivo in un test retrospettivo, è necessario dividere un set di dati in base agli articoli. Ad esempio, per la convalida incrociata in attività correlate alle immagini, eseguirai l'addestramento su una certa percentuale delle immagini e quindi userai altre parti per i test e la convalida. Nella previsione devi dividere i dati principalmente in base al tempo (e in misura minore in base agli articoli) per evitare la fuoriuscita di informazioni dal set di addestramento al set per i test e la convalida e per simulare il caso di produzione il più fedelmente possibile.
La divisione in base al tempo deve essere eseguita con attenzione, perché è bene non scegliere un singolo momento, ma più momenti. In caso contrario, la precisione dipenderà eccessivamente dalla data di inizio della previsione, definita dal punto di divisione. Una valutazione continuativa della previsione, in cui viene eseguita una serie di divisioni su più momenti e che restituisce il risultato medio, produce risultati più solidi e affidabili durante i test retrospettivi. La figura seguente mostra quattro diverse divisioni per i test retrospettivi.

Figura di quattro scenari di backtesting diversi con set di addestramento di dimensioni crescenti, ma test con dimensioni costanti
Nella figura precedente tutti gli scenari di backtesting hanno dati interamente disponibili in modo da valutare i valori previsti rispetto a quelli effettivi.
Il motivo per cui sono necessarie più finestre di backtesting è che la maggior parte delle serie temporali reali è normalmente non stazionaria. L'azienda di e-commerce presentata nel case study ha sede in Nord America e gran parte della sua domanda di prodotti è determinata dal picco del quarto trimestre, con picchi particolari attorno al Ringraziamento e prima di Natale. Nella stagione degli acquisti del quarto trimestre la variabilità delle serie temporali è maggiore rispetto al resto dell'anno. La presenza di più finestre di backtesting permette di valutare i modelli di previsione in un contesto più equilibrato.
Per ogni scenario di backtesting, la figura seguente mostra gli elementi di base della terminologia di Amazon Forecast. Amazon Forecast divide automaticamente i dati in set di dati di addestramento e test. Amazon Forecast decide come dividere i dati di input usando il parametro BackTestWindowOffset specificato come parametro nell'API create_predictor oppure usa il valore predefinito di ForecastHorizon.
Nella figura seguente puoi osservare il caso precedente più generale quando i parametri ForecastHorizon e BackTestWindowOffset non sono uguali. Il parametro BackTestWindowOffset definisce una data di inizio della previsione virtuale, mostrata come linea verticale tratteggiata nella figura seguente. Può essere usato per rispondere a questa domanda ipotetica: se il modello viene implementato in questo giorno, quale sarà la previsione? ForecastHorizon definisce il numero di fasi temporali da prevedere dalla data di inizio della previsione virtuale.
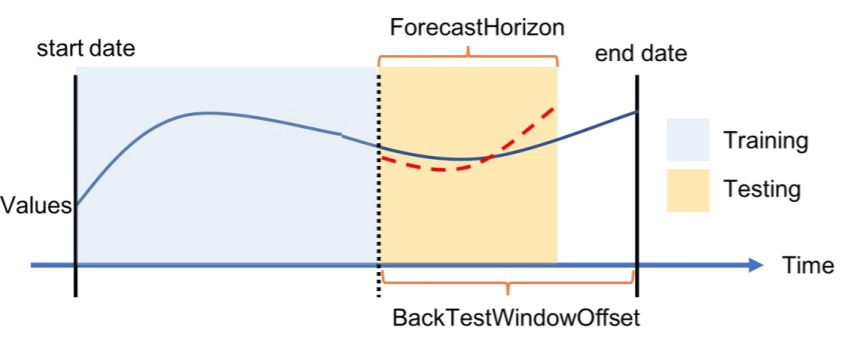
Figura di un singolo scenario di backtesting e della sua configurazione in Amazon Forecast
Amazon Forecast può esportare i valori previsti e le metriche di precisione generate durante il backtesting. I dati esportati possono essere usati per valutare determinati articoli in momenti e a quantili specifici.
Quantili di previsione e metriche di precisione
I quantili di previsione possono fornire un limite superiore e uno inferiore per le previsioni. Ad esempio, usando i tipi di previsione 0,1 (p10), 0,5 (p50) e 0,9 (p90), viene fornito un intervallo di valori noto come intervallo di confidenza dell'80% intorno alla previsione p50. Generando previsioni a p10, p50 e p90, possiamo aspettarci che il valore reale rientri tra questi limiti l'80% delle volte.
Continueremo a parlare dei quantili nella sezione Fase 5.
Amazon Forecast usa le metriche di precisione di perdita quantilica ponderata (wQL, Weighted Quantile Loss), errore quadratico medio (RMSE, Root Mean Square Error) ed errore percentuale assoluto ponderato (WAPE, Weighted Absolute Percentage Error) per valutare i predittori durante il backtesting.
Perdita quantilica ponderata (wQl)
La metrica di errore della perdita quantilica ponderata (wQL) misura la precisione della previsione di un modello a un quantile specificato. È particolarmente utile in presenza di costi diversi per le previsioni sottostimate e quelle sovrastimate. L'impostazione del peso (τ) della funzione wQL incorpora automaticamente penalità diverse per le previsioni sottostimate e quelle sovrastimate.
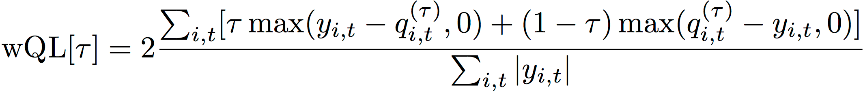
Funzione wQL
Dove:
-
τ: quantile nel set {0,01, 0,02, ..., 0,99}
-
qi,t(τ): quantile τ previsto dal modello.
-
yi, t: valore osservato in corrispondenza del punto (i,t)
Errore percentuale assoluto ponderato (WAPE)
L'errore percentuale assoluto ponderato (WAPE) è una metrica comunemente usata per misurare la precisione del modello. La metrica misura la deviazione complessiva dei valori previsti rispetto ai valori osservati.
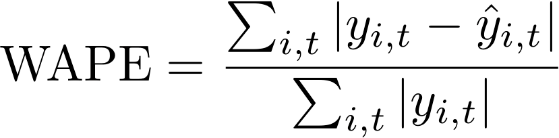
WAPE
Dove:
-
yi, t: valore osservato in corrispondenza del punto (i, t)
-
ŷi,t: valore previsto in corrispondenza del punto (i,t)
Per la previsione viene usata la previsione media come valore previsto ŷi,t.
Errore quadratico medio (RMSE)

L'errore quadratico medio (RMSE) è una metrica comunemente usata per misurare la precisione del modello. Come la metrica WAPE, misura la deviazione complessiva delle stime rispetto ai valori osservati.
Dove:
-
yi, t: valore osservato in corrispondenza del punto (i, t)
-
ŷi,t: valore previsto in corrispondenza del punto (i,t)
-
nT: numero di punti dati in un set di test
Per la previsione viene usata la previsione media come valore previsto ŷi,t. Nel calcolo delle metriche dei predittori, nT è il numero di punti dati in una finestra di backtesting.
Problemi con WAPE e RMSE
Nella maggior parte dei casi, le previsioni puntuali che possono essere generate internamente o da altri strumenti di previsione devono corrispondere al quantile p50 o alle previsioni medie. Per le metriche WAPE ed RMSE, Amazon Forecast usa la previsione media per rappresentare il valore previsto (yhat).
Per tau = 0,5 nell'equazione wQL [tau], i due pesi sono uguali e wQL[0,5] si riduce all'errore percentuale assoluto ponderato (WAPE) comunemente usato per le previsioni puntuali:
![Immagine dell'equazione wQL[0,5].](images/wql.png)
Dove yhat = q(0,5) è la previsione del calcolo. Nella formula wQL viene usato il fattore di scala 2 per annullare il fattore 0,5 e ottenere l'esatta espressione WAPE[mediano].
La definizione precedente della metrica WAPE differisce dall'interpretazione comune dell'errore assoluto medio percentuale (MAPE
A differenza della metrica di perdita quantilica ponderata per tau diverso da 0,5, la distorsione intrinseca di ogni quantile non può essere acquisita da un calcolo come WAPE, in cui i pesi sono uguali. Altri svantaggi della metrica WAPE: non è simmetrica, ha un'inflazione eccessiva degli errori percentuali per numeri piccoli ed è solo una metrica puntuale.
La metrica RMSE è il quadrato del termine di errore in WAPE e una metrica di errore comune in altre applicazioni di machine learning. La metrica RMSE favorisce un modello in cui i singoli errori hanno un ordine di grandezza coerente, perché grandi variazioni nell'errore aumentano la sovraporzionalità di RMSE. A causa dell'errore quadratico, pochi valori previsti erroneamente in una previsione altrimenti valida possono aumentare la metrica RMSE. Inoltre, a causa dei termini al quadrato, i termini di errore più piccoli hanno un peso inferiore in RMSE che non in WAPE.
Le metriche di precisione permettono una valutazione quantitativa delle previsioni. In particolare per i confronti su larga scala (il metodo A è migliore del metodo B in generale?), sono fondamentali. Tuttavia, spesso è importante integrare questi risultati con immagini per singoli SKU.
