翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
自動検出の動作
このセクションでは、クライアントアプリケーションが ElastiCache クラスタークライアントを使用してキャッシュノード接続を管理し、キャッシュ内のデータ項目を操作する方法について説明します。
キャッシュノードへの接続
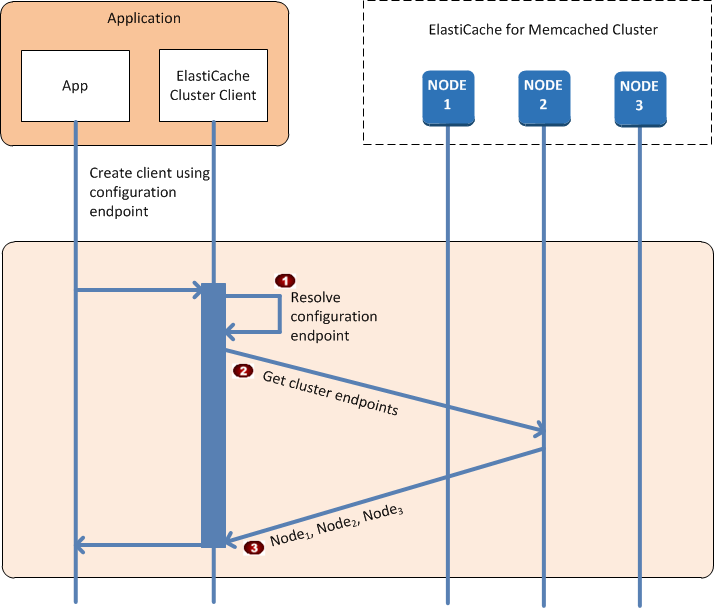
アプリケーションの観点からは、クラスター設定エンドポイントへの接続は、個々のキャッシュノードに直接接続するのと変わりません。次の一連の図は、キャッシュノードに接続するプロセスを示したものです。

|
アプリケーションは、設定エンドポイントの DNS 名を解決します。設定エンドポイントには、すべてのキャッシュノードの CNAME エントリが保持されているため、DNS 名はいずれかのノードに解決されます。その後、クライアントはそのノードに接続できます。 |

|
クライアントは、他のすべてのノードの設定情報をリクエストします。各ノードにはクラスター内のすべてのノードの設定情報が保持されているため、どのノードでも必要に応じて設定情報をクライアントに渡すことができます。 |

|
クライアントは、キャッシュノードのホスト名と IP アドレスの最新のリストを受け取ります。その後、クライアントはクラスター内の他のすべてのノードに接続できます。 |
注記
クライアントプログラムは、キャッシュノードのホスト名と IP アドレスのリストを 1 分に 1 回更新します。このポーリング間隔は、必要に応じて変更できます。
通常のクラスターオペレーション
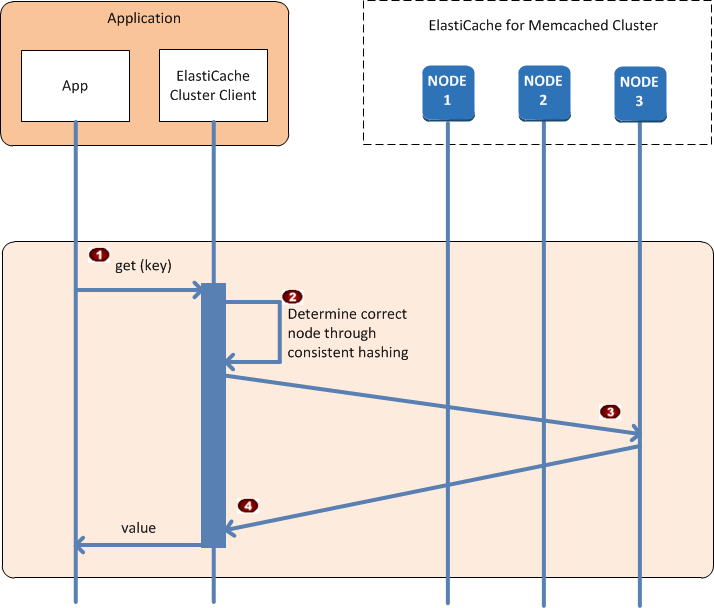
アプリケーションがすべてのキャッシュノードに接続されている場合、ElastiCache クラスタークライアントは、個々のデータ項目を格納する必要があるノードと、それらのデータ項目のクエリを実行する必要があるノードを判断します。次の一連の図は、通常のクラスターオペレーションのプロセスを示しています。
|
|
アプリケーションは、特定のデータ項目に対して get リクエストを発行します (キーにより識別されます)。 |
|
|
クライアントは、キーに対してハッシュアルゴリズムを使用して、データ項目が格納されているキャッシュノードを調べます。 |
|
|
データ項目が適切なノードからリクエストされます。 |

|
データ項目がアプリケーションに戻ります。 |
その他のオペレーション
状況によっては、クラスターのノードに変更を加えることがあります。例えば、追加の需要に対応するためにノードを追加したり、需要の減少期間中にコストを節約するためにノードを削除したりできます。または、ある種類のノード障害が原因でノードを置き換えることもできます。
クラスターのエンドポイントへのメタデータ更新を必要とするクラスターを変更するときは、すべてのノードへの変更が同時に行われます。したがって、特定のノードのメタデータと、クラスター内の他のすべてのノードのメタデータの整合性がとられます。
この場合、メタデータは、クラスター内のすべてのノードで同時に更新されるため、すべてのノード間で整合性がとられます。クラスターのさまざまなノードのエンドポイントを取得するため、設定エンドポイントを必ず使用する必要があります。設定エンドポイントを使用して、「非表示」のノードからはエンドポイントデータを取得しないようにしてください。
ノードの追加
ノードがスピンアップされている間、エンドポイントはメタデータには含まれません。エンドポイントは、ノードが利用可能となった時点で、クラスターの各ノードのメタデータに追加されます。このシナリオではメタデータはすべてのノード間で整合性がとられ、新しいノードとは、それが利用可能になった後にやり取りできるようになります。ノードが利用可能になる前にはそのノードについては認識できず、新しいノードが存在しないかのようにクラスターのノードとやり取りすることになります。
ノードの削除
ノードが削除されるときは、まずエンドポイントがメタデータから削除され、ノードがクラスターから削除されます。このシナリオではメタデータはすべてのノード間で整合性がとられており、ノードが利用できない間、削除されるノードのエンドポイントがメタデータに含まれることはありません。ノードを削除している間、そのノードはメタデータでは報告されないため、アプリケーションはそのノードが存在しないかのように n-1 の残りのノードのみとやり取りします。
ノードの置換
ノードに障害が発生した場合、ElastiCache がそのノードを停止し、別のノードを起動します。この置換プロセスは数分かかります。この間、すべてのノードのメタデータには、障害のあるノードに対応するエンドポイントが表示されますが、そのノードとのやり取りの試みは失敗します。そのため、ロジックには必ず再試行ロジックを組み込んでください。
