Amazon S3 データからのデータのインポートの概要
S3 データを Aurora PostgreSQL にインポートするには
まず、関数で指定する必要がある詳細情報を収集します。この情報には、Aurora PostgreSQL DB クラスターのインスタンス のテーブルの名前、バケット名、ファイルパス、ファイルタイプ、Amazon S3 データが保存される AWS リージョンが含まれます。詳細については、Amazon Simple Storage Service ユーザーガイドの「オブジェクトの表示」を参照してください。
注記
Amazon S3 からのマルチパートデータインポートは現在サポートされていません。
aws_s3.table_import_from_s3関数によってデータがインポートされるテーブルの名前を取得します。例えば、次のコマンドにより、後の手順で使用されるテーブルt1が作成されます。postgres=>CREATE TABLE t1 (col1 varchar(80), col2 varchar(80), col3 varchar(80));Amazon S3 バケットの詳細とインポートするデータを取得します。これを実行するには、Amazon S3 コンソール (https://console.aws.amazon.com/s3/
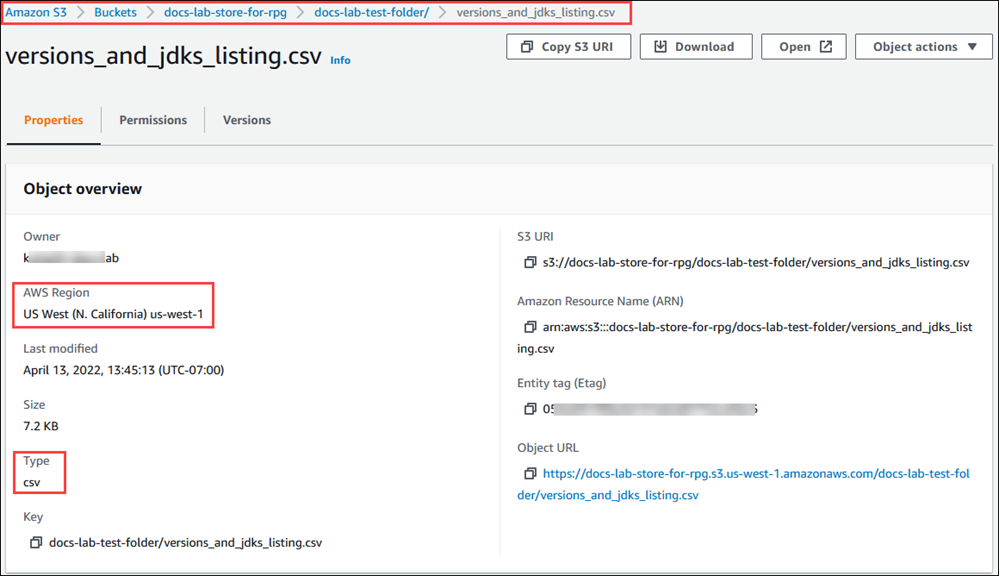
) を開き、[Bucket] (バケット) を選択します。リストで、データを含むバケットを探します。バケットを選択し、オブジェクト概要ページを開き、[Properties] (プロパティ) を選択します。 バケット名、パス、AWS リージョン、およびファイルタイプを書き留めておきます。IAM ロールによる Amazon S3 へのアクセスを設定するには、後で Amazon リソースネーム (ARN) が必要になります。詳細については、「Amazon S3 バケットへのアクセスを設定する」を参照してください。次のイメージは例を示しています。
AWS CLI コマンド
aws s3 cpを使用して、Amazon S3 バケットのデータへのパスを確認できます。情報が正しい場合、このコマンドは Amazon S3 ファイルのコピーをダウンロードします。aws s3 cp s3://amzn-s3-demo-bucket/sample_file_path./-
Aurora PostgreSQL DB クラスター に対するアクセス許可を設定して、Amazon S3 バケット上のファイルへのアクセスを許可します。これを行うには、AWS Identity and Access Management (IAM) ロールまたはセキュリティ認証情報を使用します。詳しくは、「Amazon S3 バケットへのアクセスを設定する」を参照してください。
収集したパスと他の Amazon S3 オブジェクトの詳細 (ステップ 2 を参照) を
create_s3_uri関数で指定し、Amazon S3 URI オブジェクトを構成します。この関数の詳細については、「aws_commons.create_s3_uri」を参照してください。psql セッション中にこのオブジェクトを構成する例は次のとおりです。postgres=>SELECT aws_commons.create_s3_uri( 'docs-lab-store-for-rpg', 'versions_and_jdks_listing.csv', 'us-west-1' ) AS s3_uri \gset次のステップでは、このオブジェクト (
aws_commons._s3_uri_1) をaws_s3.table_import_from_s3関数に渡して、データをテーブルにインポートします。-
aws_s3.table_import_from_s3関数を呼び出して、Amazon S3 からテーブルにデータをインポートします。参考情報については、「aws_s3.table_import_from_s3」を参照してください。例については「Amazon S3 から Aurora PostgreSQL DB クラスター にデータをインポートする」を参照してください。
