ソース Aurora DB クラスターへのデータの追加と、Amazon Redshift でのクエリ
Amazon Aurora から Amazon Redshift にデータをレプリケートするゼロ ETL 統合の作成を終了するには、Amazon Redshift に送信先データベースを作成する必要があります。
まず、Amazon Redshift クラスターまたはワークグループに接続し、統合識別子を参照してデータベースを作成します。これで、ソースの Aurora DB クラスターにデータを追加し、Amazon Redshift でクエリを実行できます。
トピック
Amazon Redshift での送信先データベースの作成
Amazon Redshift へのデータの複製を開始する前に、統合を作成後、送信先データベースをターゲットのデータウェアハウスに作成する必要があります。この送信先データベースには、統合識別子への参照が含まれている必要があります。Amazon Redshift コンソールまたはクエリエディタ v2 を使用して、データベースを作成することができます。
デスティネーションデータベースを作成する手順については、「Amazon Redshift にデスティネーションデータベースを作成する」を参照してください。
ソース DB クラスターへのデータの追加
統合を設定した後で、Amazon Redshift データウェアハウスにレプリケートするデータを Aurora DB クラスターに追加できます。
注記
Amazon Aurora と Amazon Redshift のデータ型には違いがあります。データ型マッピングの表については、「 データベースのデータタイプの違い」を参照してください。
まず、任意の MySQL または PostgreSQL クライアントを使用して、ソース DB クラスターに接続します。手順については、Amazon Aurora DB クラスターへの接続 を参照してください。
次に、テーブルを作成し、1 行のサンプルデータを挿入します。
重要
テーブルにプライマリキーがあることを確認してください。そうしないと、ターゲットのデータウェアハウスに複製できません。
pg_dump および pg_restore PostgreSQL ユーティリティは、最初にプライマリキーなしでテーブルを作成し、後で追加します。これらのユーティリティのいずれかを使用している場合は、まずスキーマを作成し、次に別のコマンドでデータをロードすることをお勧めします。
MySQL
次の例では、MySQL Workbench ユーティリティ
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
PostgreSQL
次の例では、psql PostgreSQL インタラクティブターミナルを使用しています。クラスターに接続するときは、統合の作成時に指定した名前付きデータベースを含めます。
psql -hmycluster.cluster-123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, "The Shining", "Stephen King", 1977, "Supernatural fiction");
Amazon Redshift での Aurora データのクエリ
Aurora DB クラスターにデータを追加すると、Amazon Redshift にレプリケートされ、クエリを実行できるようになります。
複製されたデータをクエリするには
-
Amazon Redshift コンソールに移動し、左側のナビゲーションペインから [クエリエディタ v2] を選択します。
-
クラスターまたはワークグループに接続し、ドロップダウンメニュー (この例では destination_database) から送信先データベース (統合から作成したもの) を選択します。デスティネーションデータベースを作成する手順については、「Amazon Redshift にデスティネーションデータベースを作成する」を参照してください。
-
SELECT ステートメントを使用してデータをクエリします。この例では、次のコマンドを実行して、ソースの Aurora DB クラスターで作成したテーブルからすべてのデータを選択します。
SELECT * frommy_db."books_table";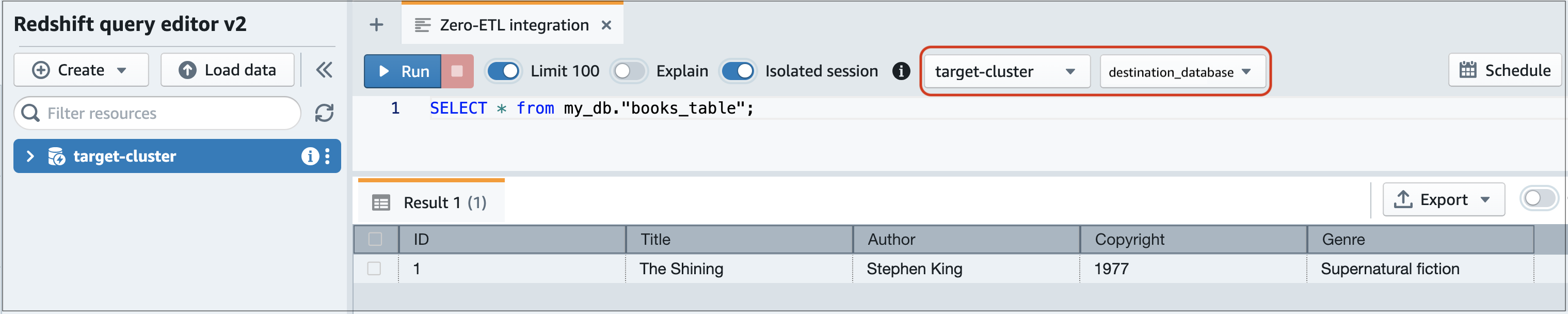
-
my_db -
books_table
-
コマンドラインクライアントを使用してデータをクエリすることもできます。例:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
注記
大文字と小文字を区別するには、スキーマ、テーブル、および列の名前を二重引用符 (" ") で囲みます。詳細については、「enable_case_sensitive_identifier」を参照してください。
データベースのデータタイプの違い
次のAurora MySQL または Aurora PostgreSQL データタイプの対応する Amazon Redshift データタイプへのマッピングを示しています。Amazon Aurora は現在、ゼロ ETL 統合ではこれらのデータ型のみをサポートしています。
ソース DB クラスターのテーブルにサポートされていないデータ型が含まれている場合、そのテーブルは同期されず、Amazon Redshift ターゲットで使用できなくなります。ソースからターゲットへのストリーミングは継続されますが、サポートされていないデータ型のテーブルは使用できません。テーブルを修正して Amazon Redshift で使用できるようにするには、変更内容を手動で元に戻し、ALTER DATABASE...INTEGRATION
REFRESH を実行して統合を更新する必要があります。
Aurora MySQL
| Aurora MySQL データ型 | Amazon Redshift のデータ型 | 説明 | 制限事項 |
|---|---|---|---|
| INT | INTEGER | 符号付き 4 バイト整数 | |
| SMALLINT | SMALLINT | 符号付き 2 バイト整数 | |
| TINYINT | SMALLINT | 符号付き 2 バイト整数 | |
| MEDIUMINT | INTEGER | 符号付き 4 バイト整数 | |
| BIGINT | BIGINT | 符号付き 8 バイト整数 | |
| INT UNSIGNED | BIGINT | 符号付き 8 バイト整数 | |
| TINYINT UNSIGNED | SMALLINT | 符号付き 2 バイト整数 | |
| MEDIUMINT UNSIGNED | INTEGER | 符号付き 4 バイト整数 | |
| BIGINT UNSIGNED | DECIMAL(20,0) | 精度の選択が可能な真数 | |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL(p,s) | 精度の選択が可能な真数 |
精度が 38 より大きく、スケールが 37 より大きい場合、サポートされない |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL(p,s) | 精度の選択が可能な真数 |
精度が 38 より大きく、スケールが 37 より大きい場合、サポートされない |
| FLOAT4/REAL | REAL | 単精度浮動小数点数 | |
| FLOAT4/REAL UNSIGNED | REAL | 単精度浮動小数点数 | |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | 倍精度浮動小数点数 | |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | 倍精度浮動小数点数 | |
| BIT(n) | VARBYTE(8) | 可変長バイナリ値 | |
| BINARY(n) | VARBYTE(n) | 可変長バイナリ値 | |
| VARBINARY (n) | VARBYTE(n) | 可変長バイナリ値 | |
| CHAR(n) | VARCHAR(n) | 可変長文字列値 | |
| VARCHAR(n) | VARCHAR(n) | 可変長文字列値 | |
| TEXT | VARCHAR(65,535) | 最大 65535 バイトの可変長文字列値 | |
| TINYTEXT | VARCHAR(255) | 最大 255 バイトの可変長文字列値 | |
| MEDIUMTEXT | VARCHAR(65,535) | 最大 65535 バイトの可変長文字列値 | |
| LONGTEXT | VARCHAR(65,535) | 最大 65535 バイトの可変長文字列値 | |
| ENUM | VARCHAR(1,020) | 最大 1020 バイトの可変長文字列値 | |
| SET | VARCHAR(1,020) | 最大 1020 バイトの可変長文字列値 | |
| DATE | DATE | カレンダー日付 (年、月、日) | |
| DATETIME | TIMESTAMP | 日付と時刻 (タイムゾーンなし) | |
| TIMESTAMP(p) | TIMESTAMP | 日付と時刻 (タイムゾーンなし) | |
| TIME | VARCHAR(18) | 最大 18 バイトの可変長文字列値 | |
| YEAR | VARCHAR(4) | 最大 4 バイトの可変長文字列値 | |
| JSON | SUPER | 値としての半構造化データまたは文書 |
Aurora PostgreSQL
Aurora PostgreSQL のゼロ ETL 統合は、カスタムデータ型または 拡張機能によって作成されたデータ型をサポートしていません。
重要
Aurora PostgreSQL の Amazon Redshift とのゼロ ETL 統合はプレビューリリースです。ドキュメントと機能はどちらも変更されることがあります。この機能については、テスト環境のみで使用でき、本番環境では使用できません。プレビューの利用規約については、「AWS のサービス条件
| Aurora PostgreSQL データ型 | Amazon Redshift のデータ型 | 説明 | 制限事項 |
|---|---|---|---|
| bigint | BIGINT | 符号付き 8 バイト整数 | |
| bigserial | BIGINT | 符号付き 8 バイト整数 | |
| bit(n) | VARBYTE(n) | 可変長バイナリ値 | |
| bit varying(n) | VARBYTE(n) | 可変長バイナリ値 | |
| bit | VARBYTE(1,024,000) | 最大 1,024,000 バイトの可変長文字列値 | |
| ブール値 | BOOLEAN | 論理ブール演算型 (true/false) | |
| bytea | VARBYTE(1,024,000) | 最大 1,024,000 バイトの可変長文字列値 | |
| character(n) | CHAR(n) | 固定長のキャラクタ文字列 | |
| character varying(n) | VARCHAR(65,535) | 可変長文字列値 | |
| date | DATE | カレンダー日付 (年、月、日) |
|
| double precision | DOUBLE PRECISION | 倍精度浮動小数点数 | サポートされていない非正規化値 |
| integer | INTEGER | 符号付き 4 バイト整数 | |
| money | DECIMAL(20,3) | 通貨額 | |
| numeric(p,s) | DECIMAL(p,s) | 可変長文字列値 |
|
| real | REAL | 単精度浮動小数点数 | |
| smallint | SMALLINT | 符号付き 2 バイト整数 | |
| smallserial | SMALLINT | 符号付き 2 バイト整数 | |
| シリアル | INTEGER | 符号付き 4 バイト整数 | |
| text | VARCHAR(65,535) | 最大 65,535 バイトの可変長文字列値 | |
| time [ (p) ] [ without time zone ] | VARCHAR(19) | 最大 19 バイトの可変長文字列値 | Infinity および -Infinity 値はサポートされていません |
| time [(p)] with time zone | VARCHAR(22) | 最大 22 バイトの可変長文字列値 |
|
| timestamp [(p)] [without timezone] | TIMESTAMP | 日付と時刻 (タイムゾーンなし) |
|
| timestamp [(p)] with time zone | TIMESTAMPTZ | 日付と時刻 (タイムゾーンあり) |
|
