翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon MQ for RabbitMQ のパフォーマンス最適化と効率のベストプラクティス
Amazon MQ for RabbitMQ ブローカーのパフォーマンスを最適化するには、スループットを最大化し、レイテンシーを最小限に抑え、効率的なリソース使用率を確保します。アプリケーションのパフォーマンスを最適化するには、次のベストプラクティスを実行します。
ステップ 1: メッセージサイズを 1 MB 未満に維持する
最適なパフォーマンスと信頼性を得るには、メッセージを 1 MB (1 MB) 未満にしておくことをお勧めします。
RabbitMQ 3.13 はデフォルトで最大 128 MB のメッセージサイズをサポートしますが、大きなメッセージは、発行をブロックし、ノード間でメッセージをレプリケートしながら高いメモリ負荷を発生させる可能性のある予測不可能なメモリアラームをトリガーする可能性があります。メッセージのサイズが大きすぎると、ブローカーの再起動プロセスや復旧プロセスにも影響し、サービス継続性のリスクが高まり、パフォーマンスが低下する可能性があります。
クレームチェックパターンを使用して大きなペイロードを保存および取得する
大きなメッセージを管理するには、メッセージペイロードを外部ストレージに保存し、RabbitMQ を介してペイロード参照識別子のみを送信することで、クレームチェックパターンを実装できます。コンシューマーはペイロード参照識別子を使用して、大きなメッセージを取得して処理します。
次の図は、Amazon MQ for RabbitMQ と Amazon S3 を使用してクレームチェックパターンを実装する方法を示しています。
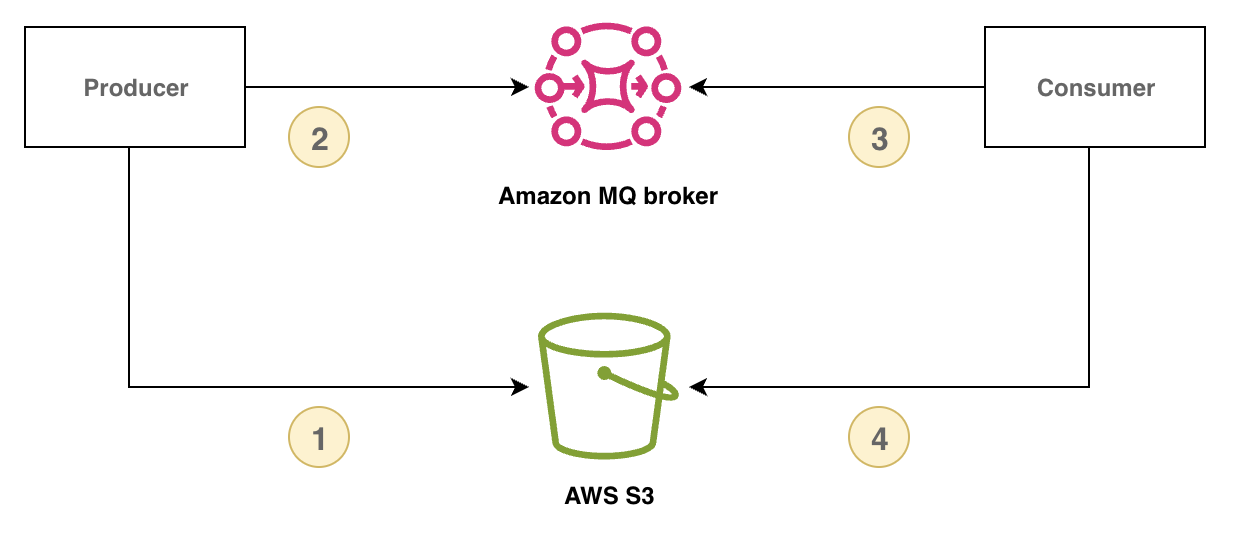
次の例は、Amazon MQ、 AWS SDK for Java 2.x、および Amazon S3 を使用したこのパターンを示しています。
-
まず、Amazon S3 参照識別子を保持する Message クラスを定義します。
class Message { // Other data fields of the message... public String s3Key; public String s3Bucket; } -
Amazon S3 にペイロードを保存し、RabbitMQ を介してリファレンスメッセージを送信するパブリッシャーメソッドを作成します。
public void publishPayload() { // Store the payload in S3. String payload = PAYLOAD; String prefix = S3_KEY_PREFIX; String s3Key = prefix + "/" + UUID.randomUUID(); s3Client.putObject(PutObjectRequest.builder() .bucket(S3_BUCKET).key(s3Key).build(), RequestBody.fromString(payload)); // Send the reference through RabbitMQ. Message message = new Message(); message.s3Key = s3Key; message.s3Bucket = S3_BUCKET; // Assign values to other fields in your message instance. publishMessage(message); } -
Amazon S3 からペイロードを取得し、ペイロードを処理し、Amazon S3 オブジェクトを削除するコンシューマーメソッドを実装します。
public void consumeMessage(Message message) { // Retrieve the payload from S3. String payload = s3Client.getObjectAsBytes(GetObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()) .asUtf8String(); // Process the complete message. processPayload(message, payload); // Delete the S3 object. s3Client.deleteObject(DeleteObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()); }
ステップ 2: basic.consumeと存続期間の長いコンシューマーを使用する
存続期間の長いコンシューマーbasic.consumeで を使用すると、 を使用して個々のメッセージをポーリングするよりも効率的ですbasic.get。詳細については、「個々のメッセージのポーリング
ステップ 3: プリフェッチを設定する
RabbitMQ のプリフェッチ値を使用して、コンシューマーがメッセージを消費する方法を最適化できます。RabbitMQ は、プリフェッチ数をチャネルではなくコンシューマーに適用することによって、AMQP 0-9-1 が提供するチャネルプリフェッチメカニズムを実装します。プリフェッチ値は、特定の時間にコンシューマに送信されるメッセージの数を指定するために使用されます。デフォルトで、RabbitMQ はクライアントアプリケーションに無制限のバッファサイズを設定します。
RabbitMQ コンシューマーにプリフェッチ数を設定するときに考慮する要因にはさまざまなものがあります。まず、コンシューマーの環境と設定を考慮します。コンシューマーは、メッセージが処理されるときにそれらすべてをメモリに保持する必要があるため、高いプリフェッチ値はコンシューマーのパフォーマンスに悪影響を及ぼし、場合によってはコンシューマー全体がクラッシュする原因になることもあります。同様に、RabbitMQ ブローカー自体も、コンシューマー承認を受け取るまで、送信するすべてのメッセージをメモリにキャッシュしておきます。コンシューマに自動承認が設定されておらず、コンシューマによるメッセージの処理に比較的長い時間がかかる場合、高いプリフェッチ値は RabbitMQ サーバーのメモリがすぐになくなる原因になる可能性があります。
上記の考慮事項を踏まえて、大量の未処理または未承認のメッセージが原因で RabbitMQ ブローカー、またはそのコンシューマーでメモリ不足が発生する状況を防ぐため、常にプリフェッチ値を設定することが推奨されます。大量のメッセージを処理するためにブローカーを最適化する必要がある場合は、さまざまなプリフェッチ数を使用してブローカーとコンシューマーをテストし、コンシューマーがメッセージを処理するためにかかる時間と比較して、ネットワークオーバーヘッドがおおむね軽微なものになる値を判断します。
注記
コンシューマーへのメッセージの配信を自動承認するようにクライアントアプリケーションが設定されている場合、プリフェッチ値を設定しても効果はありません。
プリフェッチされたメッセージはすべて、キューから削除されます。
以下の例は、RabbitMQ Java クライアントライブラリを使用した単一のコンシューマーへのプリフェッチ値 10 の設定を示しています。
ConnectionFactory factory = new ConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.basicQos(10, false); QueueingConsumer consumer = new QueueingConsumer(channel); channel.basicConsume("my_queue", false, consumer);
注記
RabbitMQ Java クライアントライブラリでは、global フラグのデフォルト値が false に設定されているので、上記の例は単純に channel.basicQos(10) として記述できます。
ステップ 4: Celery 5.5 以降をクォーラムキューで使用する
分散タスクキューシステムである Python Celery
すべての Celery バージョンの場合
-
をオフに
task_create_missing_queuesしてキューのチャーンを軽減します。 -
次に、 をオフに
worker_enable_remote_controlして、celery@...pidboxキューの動的作成を停止します。これにより、ブローカーのキューチャーンが減少します。worker_enable_remote_control = false -
重要でないメッセージアクティビティをさらに減らすには、Celery アプリケーションを起動するときに
-Eまたは--task-eventsフラグを付けずに、Celery worker-send-task-eventsをオフにします。 -
次のパラメータを使用して Celery アプリケーションを起動します。
celery -A app_name worker --without-heartbeat --without-gossip --without-mingle
Celery バージョン 5.5 以降の場合
-
Celery バージョン 5.5
、クォーラムキューをサポートする最小バージョン、またはそれ以降のバージョンにアップグレードします。使用している Celery のバージョンを確認するには、 を使用します celery --version。クォーラムキューの詳細については、「」を参照してくださいAmazon MQ での RabbitMQ のクォーラムキュー。 -
Celery 5.5 以降にアップグレードした後、
task_default_queue_typeを「クォーラム」に設定します。 -
次に、ブローカートランスポートオプション
で発行確認を有効にする必要もあります。 broker_transport_options = {"confirm_publish": True}
