Amazon S3 内の暗号化されたデータセットに基づいてテーブルを作成する
テーブルを作成するときは、データセットが Amazon S3 で暗号化されていることを Athena で指定します。これは、SSE-KMS を使用するときは必要ありません。SSE-S3 と AWS KMS の暗号化の場合、Athena がデータセットの復号とテーブルの作成の方法を判断するので、キー情報は提供しないでください。
テーブルを作成するユーザーを含めて、クエリを実行するユーザーは、このトピックで前述したアクセス許可を持っている必要があります。
重要
EMRFS と共に Amazon EMR を使用して暗号化された Parquet ファイルをアップロードする場合は、fs.s3n.multipart.uploads.enabled を false に設定して、マルチパートアップロードを無効にする必要があります。これを行わないと、Athena は Parquet ファイルの長さを判断できず、HIVE_CANNOT_OPEN_SPLIT エラーが発生します。詳細については、「Amazon EMR 管理ガイド」の「Amazon S3 用のマルチパートアップロードを設定する」を参照してください。
データセットが Amazon S3 で暗号化されていることを指定するには、以下のいずれかの手順を実行します。SSE-KMS を使用する場合、このステップは不要です。
-
次の例のように、CREATE TABLE ステートメントで、
'has_encrypted_data'='true'を指定するTBLPROPERTIES句を使用します。CREATE EXTERNAL TABLE 'my_encrypted_data' ( `n_nationkey` int, `n_name` string, `n_regionkey` int, `n_comment` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' LOCATION 's3://amzn-s3-demo-bucket/folder_with_my_encrypted_data/' TBLPROPERTIES ( 'has_encrypted_data'='true') -
statement.executeQuery()を使用して CREATE TABLE ステートメントを実行するときには、前の例にあるように、JDBC ドライバーを使用してTBLPROPERTIES値を設定します。 -
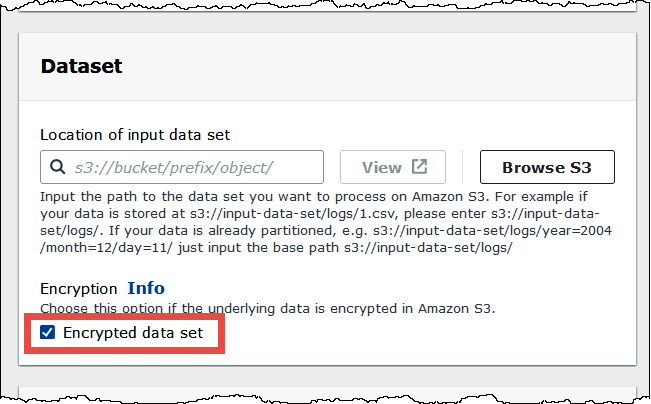
Athena コンソールを使用して、フォームを使用したテーブルの作成およびテーブルの場所の指定を行う場合、[Encrypted data set] (暗号化されたデータセット) のオプションを選択します。
Athena コンソールのテーブルのリストでは、暗号化されたテーブルにはキー型のアイコンが表示されます。
