Amazon S3 に保存されている Apache ログをクエリする
Amazon Athena を使用して、Simple Storage Service (Amazon S3) アカウントに保存されている Apache HTTP サーバーのログファイル
一般的なログ形式のフィールドには、クライアント IP アドレス、クライアント ID、ユーザー ID、リクエスト受信時のタイムスタンプ、クライアントリクエストのテキスト、サーバステータスコード、およびクライアントに返されたオブジェクトのサイズが含まれます。
以下の例は、Apache の一般的なログ形式を示しています。
198.51.100.7 - Li [10/Oct/2019:13:55:36 -0700] "GET /logo.gif HTTP/1.0" 200 232 198.51.100.14 - Jorge [24/Nov/2019:10:49:52 -0700] "GET /index.html HTTP/1.1" 200 2165 198.51.100.22 - Mateo [27/Dec/2019:11:38:12 -0700] "GET /about.html HTTP/1.1" 200 1287 198.51.100.9 - Nikki [11/Jan/2020:11:40:11 -0700] "GET /image.png HTTP/1.1" 404 230 198.51.100.2 - Ana [15/Feb/2019:10:12:22 -0700] "GET /favicon.ico HTTP/1.1" 404 30 198.51.100.13 - Saanvi [14/Mar/2019:11:40:33 -0700] "GET /intro.html HTTP/1.1" 200 1608 198.51.100.11 - Xiulan [22/Apr/2019:10:51:34 -0700] "GET /group/index.html HTTP/1.1" 200 1344
Athena で Apache ログ用のテーブルを作成する
Amazon S3 に保存されている Apache ログをクエリする前に、Athena のテーブルスキーマを作成して、Athena がログデータを読み取ることができるようにする必要があります Apache ログ用の Athena テーブルを作成するには、Grok SerDe を使用できます。Grok SerDe の使用に関する詳細については、「AWS Glue デベロッパーガイド」の「Grok カスタム分類子の書き込み」を参照してください。
Athena で Apache ウェブサーバーログ用のテーブルを作成する
https://console.aws.amazon.com/athena/
で Athena コンソールを開きます。 -
以下の DDL ステートメントを Athena クエリエディタに貼り付けます。
LOCATION 's3://amzn-s3-demo-bucket/の値を変更して、Amazon S3 内の Apache ログをポイントするようにします。apache-log-folder/'CREATE EXTERNAL TABLE apache_logs ( client_ip string, client_id string, user_id string, request_received_time string, client_request string, server_status string, returned_obj_size string ) ROW FORMAT SERDE 'com.amazonaws.glue.serde.GrokSerDe' WITH SERDEPROPERTIES ( 'input.format'='^%{IPV4:client_ip} %{DATA:client_id} %{USERNAME:user_id} %{GREEDYDATA:request_received_time} %{QUOTEDSTRING:client_request} %{DATA:server_status} %{DATA: returned_obj_size}$' ) STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://amzn-s3-demo-bucket/apache-log-folder/'; -
Athena コンソールでクエリを実行して、
apache_logsテーブルを登録します。クエリが完了すると、Athena からログをクエリできるようになります。
クエリの例
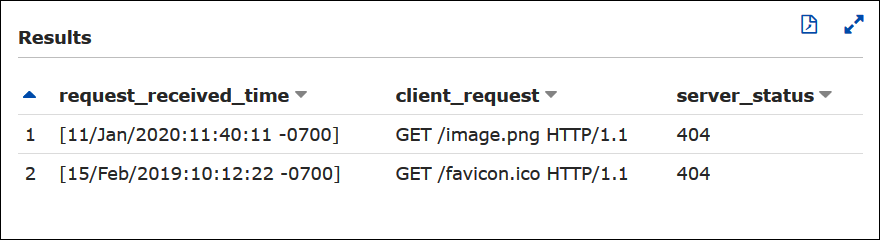
例 – 404 エラーをフィルタリングする
以下のクエリ例は、リクエストの受信時刻、クライアントリクエストのテキスト、およびサーバーステータスコードを apache_logs テーブルから選択します。WHERE 句は、HTTP ステータスコード 404 (ページが見つかりません) をフィルターします。
SELECT request_received_time, client_request, server_status FROM apache_logs WHERE server_status = '404'
以下の画像は、Athena クエリエディタでのクエリの結果を示しています。
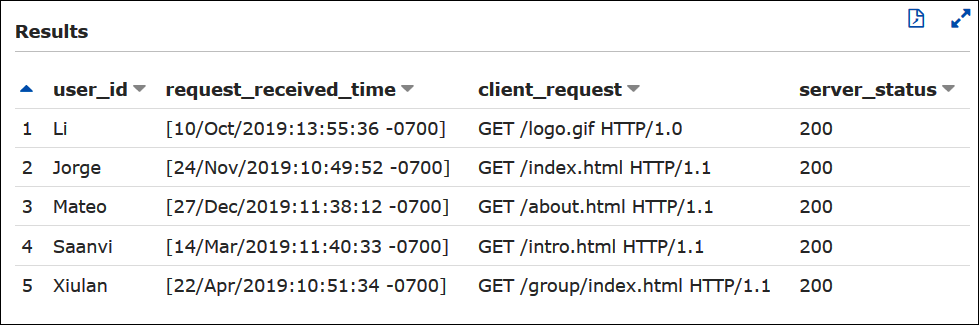
例 – 成功したリクエストをフィルタリングする
以下の例のクエリでは、ユーザー ID、リクエスト受信時刻、クライアントリクエストのテキスト、およびサーバーステータスコードを apache_logs テーブルから選択しています。WHERE 句は、HTTP ステータスコード 200 (成功) をフィルターします。
SELECT user_id, request_received_time, client_request, server_status FROM apache_logs WHERE server_status = '200'
以下の画像は、Athena クエリエディタでのクエリの結果を示しています。
例 – タイムスタンプでフィルタリングする
次の例では、リクエストの受信時間が指定されたタイムスタンプよりも長いレコードをクエリします。
SELECT * FROM apache_logs WHERE request_received_time > 10/Oct/2023:00:00:00
