翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Auto Scaling グループでのインスタンスのヘルスチェック
Amazon EC2 Auto Scaling は、Auto Scaling グループ内のインスタンスのヘルスステータスを継続的にモニタリングして、希望するキャパシティを維持します。
Auto Scaling グループ内のすべてのインスタンスは Healthy ステータスで開始します。インスタンスに異常があるという通知を Amazon EC2 Auto Scaling が受け取らない限り、インスタンスは正常であると見なされます。インスタンスが異常になり、置き換える必要がある場合、さまざまなソースから通知を受け取る可能性があります。こうしたソースには、以下が含まれます。
-
Amazon EC2
-
エラスティックロードバランシング
-
VPC Lattice
-
Amazon EBS
-
定義したカスタムヘルスチェック
Amazon EC2 Auto Scaling が InService インスタンスに異常があると判断した場合、そのインスタンスを新しいインスタンスに置き換えて、グループの希望するキャパシティを維持します。新しいインスタンスは、Auto Scaling グループの現在の設定、およびそれに関連する起動テンプレートまたは起動設定を使用して起動します。
次のフロー図は、Auto Scaling グループで新しいインスタンスを起動するプロセスを示しています。インスタンスを起動することから始まります。起動が成功すると、インスタンスが Auto Scaling グループに追加されます。次に、Amazon EC2 Auto Scaling は、組み込みの Amazon EC2 ステータスチェックを使用してインスタンスのヘルスチェックを実行し、猶予期間後にグループに対して有効にしたオプションのヘルスチェックを実行します。これらのヘルスチェックは継続して定期的に実行されます。ヘルスチェックのいずれかが不合格になると、インスタンスは置き換えられます。
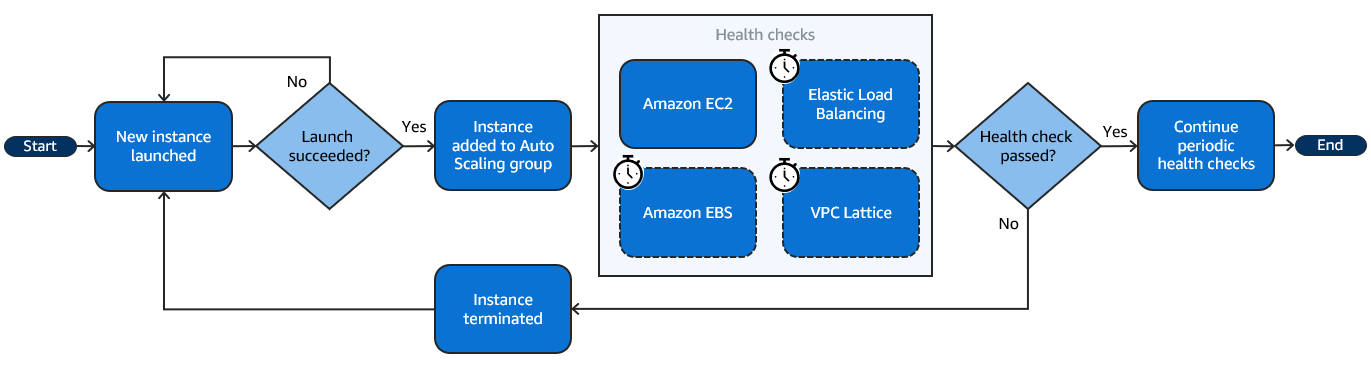
異常なインスタンスは、スポットインスタンスの中断やユーザーによる手動終了など、インスタンスが予期せず終了した場合にも発生することもあります。この場合も、Amazon EC2 Auto Scaling は希望するキャパシティを維持するために、代替インスタンスを自動的に起動します。
内容
