翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Comprehend によるモデルバージョニング
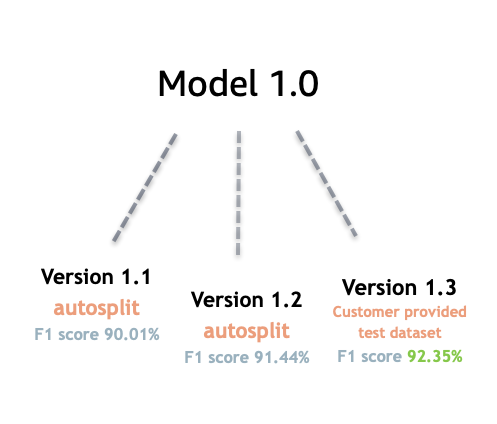
人工知能と機械学習 (AI/ML) は、実験の迅速さがすべてです。Amazon Comprehend では、モデルをトレーニングして構築し、データに関する洞察を得ることができます。モデルのバージョニングを使用すると、提供するデータセットが増えたり変わったりといった、モデルの実行結果に関連するモデリング履歴とスコアを追跡できます。バージョニングは、カスタム分類モデルまたはカスタムエンティティ認識モデルで利用できます。時間の経過と共に変わるバージョンを観察することで、そのバージョンがどの程度成功したか、また、成功状態に至るまでにどのようなパラメータを使用したかの洞察を得ることができます。
既存のカスタム分類子モデルまたはエンティティ認識モデルの新しいバージョンのトレーニングでは、モデルの詳細ページから新しいバージョンを作成するだけで、すべての詳細情報が自動的に入力されます。新しいバージョンには以前のモデルと同じ名前 (VersionID と言う) が付けられますが、作成時には固有のバージョン名を付けることができます。モデルに新しいバージョンを追加すると、モデルの詳細ページから以前のすべてのバージョンとその詳細を 1 つのビューで確認できます。バージョニングでは、トレーニングデータセットに変更を加えたときにモデルのパフォーマンスがどのように変化するかを確認できます。
新しいカスタム分類子バージョン (コンソール) を作成する
-
にサインイン AWS Management Console し、https://console.aws.amazon.com/comprehend/
で Amazon Comprehend コンソールを開きます。 -
左側のメニューから [カスタマイズ] を選択し、[カスタム分類] を選択します。
-
[分類子] の一覧から、新しいバージョンを作成するカスタムモデルの名前を選択します。カスタムモデルの詳細 ページが表示されます。
-
右上の [モデルの新規作成] を選択します。親カスタム分類モデルの詳細があらかじめ入力されている画面が開きます。
-
[バージョン名] で、新しいバージョンに一意の名前を追加します。
-
バージョン詳細で、新しいモデルに関連付ける言語とラベル数を変更できます。
-
[データ仕様] セクションで、新しいバージョンへのデータの提供方法を設定します。以前のモデルのドキュメントと新しいドキュメントを含む完全なデータを必ず提供してください。分類子モード (シングルラベルまたはマルチラベル)、データ形式 (CSV ファイル、拡張マニフェスト)、トレーニングデータセット、テストデータセット (自動分割、またはカスタムテストデータ設定) を変更できます。
-
(オプション) 出力データの S3 上の場所を更新する
-
[アクセス権限] で、IAM ロールを作成するか、既存の IAM ロールを使用します。
-
(オプション) VPC 設定を更新する
-
(オプション) 詳細を追跡しやすいよう、新しいバージョンにタグを追加します。
カスタム分類子の作成については、「カスタム分類子の作成」を参照してください。
カスタムエンティティレコグナイザーの新しいバージョンを作成する (コンソール)
-
にサインイン AWS Management Console し、https://console.aws.amazon.com/comprehend/
で Amazon Comprehend コンソールを開きます。 -
左側のメニューから [カスタマイズ] を選択し、[カスタムエンティティ認識] を選択します。
-
[レコグナイザーモデル] のリストから、新しいバージョンを作成するレコグナイザーの名前を選択します。詳細ページが表示されます。
-
右上の [新バージョンをトレーニング] を選択します。親エンティティレコグナイザーからの詳細があらかじめ入力されている画面が開きます。
-
[バージョン名] で、新しいバージョンに一意の名前を追加します。
-
[カスタムエンティティタイプ] で、1つまたは複数のカスタムラベルを追加し、[タイプを追加] を選択します。レコグナイザーは、このカスタムラベルを使用してデータセット内のエンティティタイプを識別します。指定したアノテーションまたはエンティティリストからカスタムエンティティタイプを選択します。レコグナイザーは、ジョブの実行時に、含まれているすべてのエンティティタイプを使用してデータセット内のエンティティを識別します。複数の単語を使用する場合は各エンティティタイプを大文字にし、アンダースコアで区切る必要があります。最大 25 のタイプを使用できます。
-
(オプション) ジョブの処理中にストレージボリューム内のデータを暗号化する場合は、[レコグナイザーの暗号化] を選択します。
-
トレーニングデータセクションで、アノテーションとデータ形式の詳細 (CSV ファイル、拡張マニフェスト)、シングルラベル、マルチラベル)、データ形式 (CSV、拡張マニフェスト)、トレーニングデータセット、テストデータセット (自動分割またはカスタムテストデータ設定) を指定します。
-
(オプション) 出力データの S3 上の場所を更新する
-
[アクセス権限] で、IAM ロールを作成するか、既存の IAM ロールを使用します。
-
(オプション) VPC 設定を更新する
-
(オプション) 詳細を追跡しやすいよう、新しいバージョンにタグを追加します。
カスタムエンティティレコグナイザーの詳細については、「カスタムエンティティ認識」と「コンソールを使用したカスタムエンティティレコグナイザーの作成」を参照してください。
