AWS Data Pipeline は、新規顧客には利用できなくなりました。の既存のお客様 AWS Data Pipeline は、通常どおりサービスを引き続き使用できます。詳細はこちら
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Data Pipelineマネージドリソースの Task Runner
リソースが によって起動および管理されると AWS Data Pipeline、ウェブサービスは、そのリソースに Task Runner を自動的にインストールして、パイプライン内のタスクを処理します。アクティビティオブジェクトの runsOnフィールドに計算リソース (Amazon EC2インスタンスまたは Amazon EMRクラスター) を指定します。 AWS Data Pipeline
は、このリソースを起動するときに、そのリソースにTask Runnerをインストールし、runsOnフィールドがそのリソースに設定されている、すべてのアクティビティオブジェクトを処理するよう設定します。がリソース AWS Data Pipeline を終了すると、Task Runner ログはシャットダウンする前に Amazon S3 の場所に発行されます。
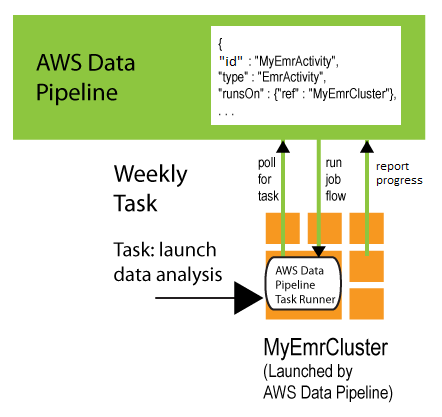
たとえば、パイプラインでEmrActivityを使用するばあいは、runsOnフィールドでEmrClusterリソースを指定します。がそのアクティビティ AWS Data Pipeline を処理すると、Amazon EMRクラスターを起動し、Task Runner をマスターノードにインストールします。次に、このTask Runnerは、runsOnフィールドがそのEmrClusterオブジェクトに設定されている、アクティビティのタスクを処理します。次のパイプライン定義の抜粋は、2つのオブジェクト間のこの関係を示します。
{ "id" : "MyEmrActivity", "name" : "Work to perform on my data", "type" : "EmrActivity", "runsOn" : {"ref" : "MyEmrCluster"}, "preStepCommand" : "scp remoteFiles localFiles", "step" : "s3://myBucket/myPath/myStep.jar,firstArg,secondArg", "step" : "s3://myBucket/myPath/myOtherStep.jar,anotherArg", "postStepCommand" : "scp localFiles remoteFiles", "input" : {"ref" : "MyS3Input"}, "output" : {"ref" : "MyS3Output"} }, { "id" : "MyEmrCluster", "name" : "EMR cluster to perform the work", "type" : "EmrCluster", "hadoopVersion" : "0.20", "keypair" : "myKeyPair", "masterInstanceType" : "m1.xlarge", "coreInstanceType" : "m1.small", "coreInstanceCount" : "10", "taskInstanceType" : "m1.small", "taskInstanceCount": "10", "bootstrapAction" : "s3://elasticmapreduce/libs/ba/configure-hadoop,arg1,arg2,arg3", "bootstrapAction" : "s3://elasticmapreduce/libs/ba/configure-other-stuff,arg1,arg2" }
このアクティビティの実行の詳細および例については、「EmrActivity」を参照してください。
パイプラインに複数の AWS Data Pipelineマネージドリソースがある場合、Task Runner は各リソースにインストールされ、それらはすべて処理するタスク AWS Data Pipeline をポーリングします。
