AWS Data Pipeline は新規顧客には利用できなくなりました。の既存のお客様は、通常どおりサービスを AWS Data Pipeline 引き続き使用できます。詳細はこちら
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
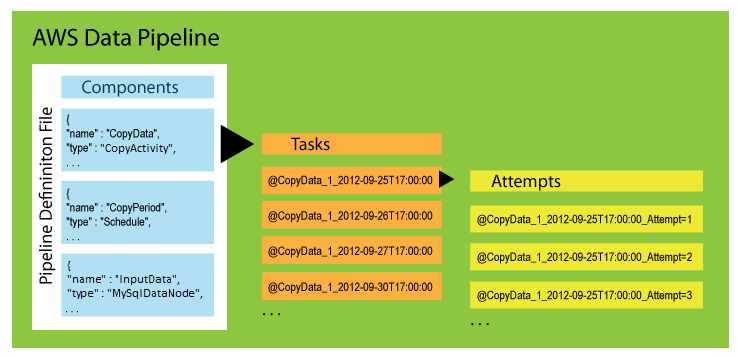
パイプラインのコンポーネント、インスタンス、試行
スケジュールされたパイプラインに関連付けられる項目には 3 つのタイプがあります。
-
パイプラインコンポーネント – パイプラインコンポーネントはパイプラインのビジネスロジックを表し、パイプライン定義のさまざまなセクションによって表されます。パイプラインコンポーネントは、ワークフローのデータソース、アクティビティ、スケジュール、および前提条件を指定します。これらは親コンポーネントからプロパティを継承できます。コンポーネント間の関係は参照によって定義されます。パイプラインコンポーネントは、データ管理のルールを定義します。
-
インスタンス — がパイプライン AWS Data Pipeline を実行すると、パイプラインコンポーネントをコンパイルして一連の実用的なインスタンスを作成します。各インスタンスには、特定のタスクを実行するためのすべての情報が含まれています。インスタンスの完全なセットは、パイプラインの To-Do リストです。 AWS Data Pipeline は、処理するインスタンスをタスクランナーに渡します。
-
試行 – 堅牢なデータ管理を提供するために、 AWS Data Pipeline は失敗したオペレーションを再試行します。この処理は、タスクが最大許容再試行回数に到達するまで続行されます。試行オブジェクトは、さまざまな試行、結果、および失敗の理由(該当する場合)を追跡します。基本的に、カウンターを持つインスタンスです。 AWS Data Pipeline は、Amazon EMR クラスターや EC2 インスタンスなど、以前の試行と同じリソースを使用して再試行を実行します。
注記
失敗したタスクの再実行は耐障害性戦略の重要な部分であり、 AWS Data Pipeline のパイプライン定義では再試行を制御するための条件としきい値を提供します。ただし、 AWS Data Pipeline では指定されたすべての再試行回数に到達するまで失敗がレポートされないため、再試行回数が多すぎると、復旧不可能な障害の検出が遅れる可能性があります。再試行が AWS リソースで実行されている場合、余分な再試行によって追加料金が発生することがあります。そのため、再試行と関連設定を制御するために使用する AWS Data Pipeline デフォルト設定を超えるのが適切なタイミングを慎重に検討してください。