翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ディザスタリカバリと Amazon DocumentDB グローバルクラスターについて
トピック
グローバルクラスターを使用すると、リージョンの障害などの災害から迅速に復旧できます。災害からの復旧は、通常、RTO と RPO (目標復旧時点) の値を使用して測定します。
-
目標復旧時間 (RTO)– 災害後にシステムが稼働状態に戻るまでにかかる時間。つまり、RTO はダウンタイムを測定します。グローバルクラスターの場合、RTO は分単位です。
-
目標復旧時点 (RPO) – 損失する可能性があるデータの量 (時間単位)。グローバルクラスターの場合、目標復旧時点 (RPO) は通常、秒単位で測定されます。
-
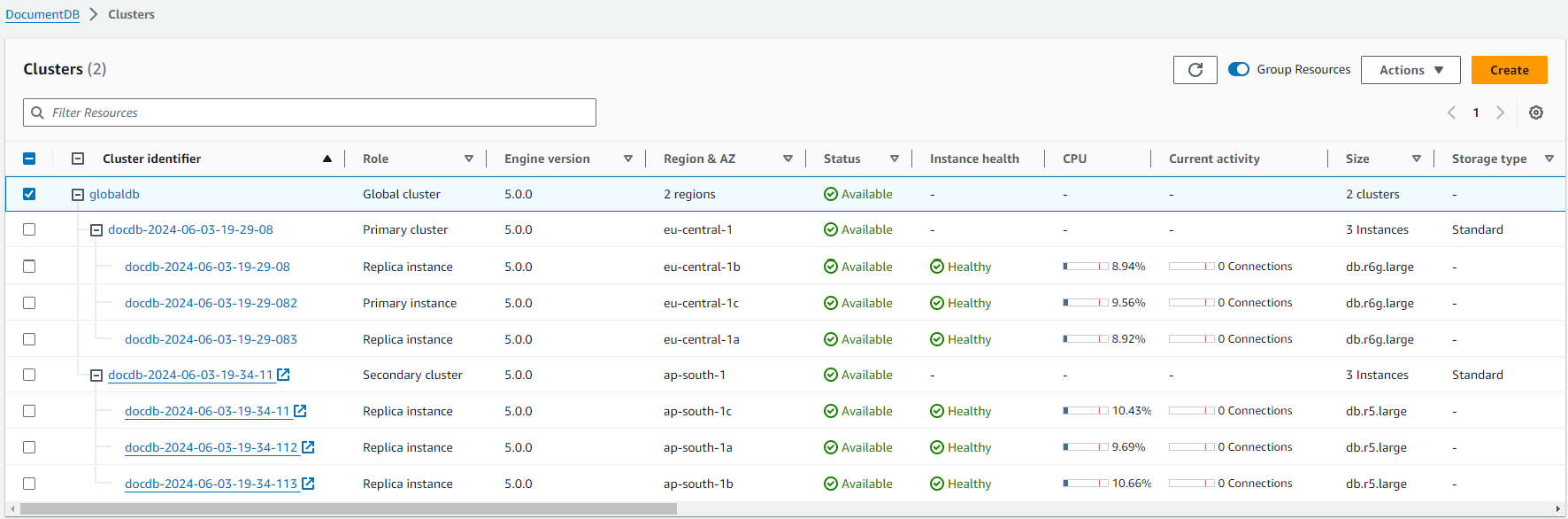
予期しない停止から復旧するには、グローバルクラスター内のセカンダリの 1 つのクロスリージョンフェイルオーバーを実行できます。グローバルクラスターに複数のセカンダリリージョンがある場合、プライマリとして昇格させたいすべてのセカンダリリージョンをデタッチしてください。次に、これらのセカンダリリージョンの 1 つを新しいプライマリ AWS リージョンに昇格させます。最後に、他の各セカンダリリージョンに新しいクラスターを作成し、それらのクラスターをグローバルクラスターにアタッチします。
Amazon DocumentDB グローバルクラスターのマネージドフェイルオーバーの実行
このアプローチは、真の地域災害やサービスレベルの全面的な停止が発生した場合でも事業を継続できるようにするためのものです。
マネージドフェイルオーバー中、プライマリクラスターは選択したセカンダリリージョンにフェイルオーバーされ、お使いの Amazon DocumentDB グローバルクラスターの既存のレプリケーショントポロジが維持されます。選択したセカンダリクラスターは、読み取り専用ノードの 1 つを完全な読み取り状態に昇格します。このステップにより、クラスターがプライマリクラスターのロールを引き受けることができます。クラスターが新しいロールを引き受ける間、データベースは短時間使用できなくなります。古いプライマリクラスターから選択したセカンダリクラスターにレプリケートされなかったデータは、このセカンダリクラスターが新しいプライマリクラスターになると失われます。古いプライマリボリュームは、新しいプライマリと同期する前にスナップショットを取得するべく、レプリケートされていないデータがスナップショットに保持されるように最善を尽くします。
注記
マネージドクロスリージョンクラスターフェイルオーバーは、プライマリクラスターとすべてのセカンダリクラスターに同じエンジンバージョンがある場合にのみ、Amazon DocumentDB グローバルクラスターで実行できます。ご使用のエンジンバージョンに互換性がない場合は、Amazon DocumentDB グローバルクラスターの手動フェイルオーバーの実行 の手順に従ってフェイルオーバーを手動で実行できます。
リージョンのエンジンバージョンが一致しない場合、フェイルオーバーはブロックされます。保留中のアップグレードを確認して適用し、すべてのリージョンのエンジンバージョンが一致し、グローバルクラスターフェイルオーバーがブロック解除されていることを確認してください。詳細については、「グローバルクラスターのスイッチオーバーまたはフェイルオーバーのブロック解除」を参照してください。
データの損失を最小限に抑えるため、この機能を使用する前に次のことを行うことをお勧めします。
各アプリケーションをオフラインにして、Amazon DocumentDB グローバルクラスターのプライマリクラスターへの書き込みが送信されないようにします。
すべての Amazon DocumentDB セカンダリクラスターのラグタイムをチェックします。レプリケーションの遅延が最も少ないセカンダリリージョンを選択すると、現在障害が発生しているプライマリリージョンでのデータ損失を最小限に抑えることができます。Amazon CloudWatch 上で
GlobalClusterReplicationLagメトリクスを確認して、グローバルクラスター内のすべての Amazon DocumentDB セカンダリクラスターのラグタイムを確認します。これらのメトリクスは、各セカンダリクラスターへのレプリケーションがプライマリクラスターに対してどの程度遅れているかをミリ秒単位で示します。Amazon DocumentDB 向け CloudWatch メトリクスの詳細については、「Amazon DocumentDB のメトリクス」を参照してください。
マネージドフェイルオーバー中、選択されたセカンダリクラスターは、プライマリとして新しいロールに昇格されます。ただし、プライマリクラスターのさまざまな設定オプションは引き継がれません。構成の不一致は、パフォーマンスの問題、ワークロードの非互換性、およびその他の異常な動作につながる可能性があります。このような問題を回避するには、Amazon DocumentDB グローバルクラスター間の次のような相違点を解消しておくことをお勧めします。
新しいプライマリ向けに Amazon DocumentDB のクラスターパラメータグループを構成する (必要な場合) — Amazon DocumentDB グローバルクラスター内の各クラスターごとに、Amazon DocumentDB クラスターパラメータグループを構成できます。ただし、セカンダリクラスターを昇格してプライマリロールを引き継ぐ場合、セカンダリからのパラメータグループは、プライマリとは異なる設定になっている可能性があります。その場合は、昇格されたセカンダリクラスターのパラメータグループを、プライマリクラスターの設定に適合するように変更してください。この方法の詳細は、「Amazon DocumentDB クラスターパラメータグループを変更する」を参照してください。
各種モニタリングツールやオプションを構成する (Amazon CloudWatch Events やアラームなど) - グローバルクラスターに必要なログ機能、アラームなどを使用して、昇格されたクラスターの設定を行います。パラメータグループと同様に、フェイルオーバープロセス中にこれらの機能の設定がプライマリから継承されることはありません。レプリケーションラグなどの一部の CloudWatch メトリクスは、セカンダリリージョンのみで使用できます。そのため、フェイルオーバーによってメトリクスの表示方法やアラームの設定方法が変わり、定義済みのダッシュボードを変更する必要が生じる場合があります。Amazon DocumentDB クラスターとモニタリングの詳細については、「Amazon DocumentDB のモニタリング」を参照してください。
通常、選択したセカンダリクラスターは 1 分以内にプライマリロールを引き受けます。新しいプライマリリージョンのライターノードが使用可能になり次第、アプリケーションをそのライターノードに接続してワークロードを再開できます。Amazon DocumentDB が新しいプライマリクラスターを昇格させると、追加のセカンダリリージョンクラスターはすべて自動的にリビルドされます。
Amazon DocumentDB グローバルクラスターは非同期レプリケーションを使用するため、レプリケーションラグはセカンダリリージョンごとに異なる場合があります。これに対し Amazon DocumentDB は、これらのセカンダリリージョンを、新しいプライマリリージョンクラスターとまったく同じポイントインタイムデータを持つようにリビルドします。ストレージボリュームのサイズとリージョン間の距離によっては、再構築タスクが完了するまでに数分から数時間かかることがあります。セカンダリージョンのクラスターが新しいプライマリリージョンからの再構築を完了すると、読み取りアクセスが可能になります。新しいプライマリライターが昇格して使用可能になると、新しいプライマリリージョンのクラスターが、Amazon DocumentDB グローバルクラスターの読み取りおよび書き込みオペレーションを処理できるようになります。
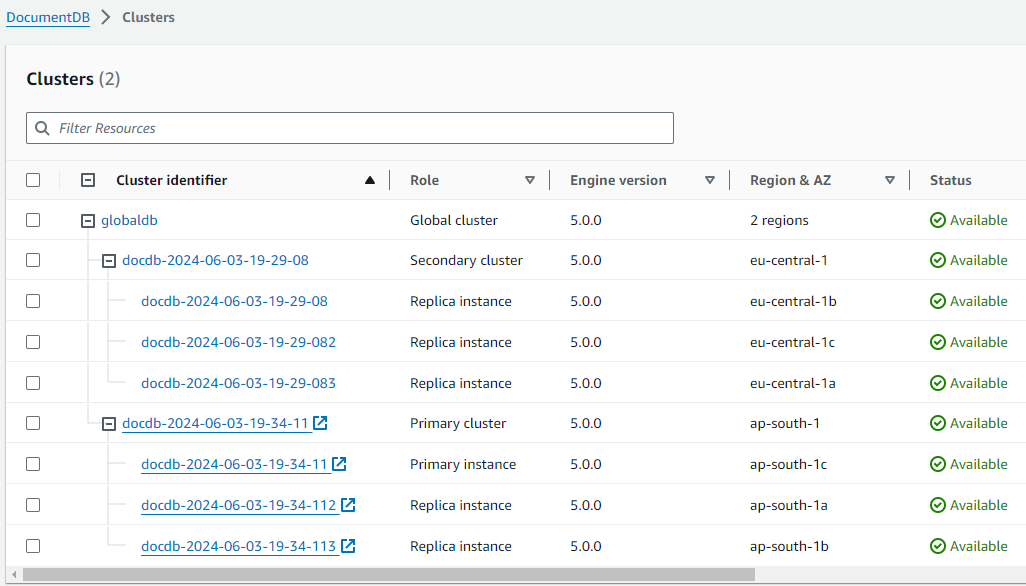
グローバルクラスターの元のトポロジを復元するために、Amazon DocumentDB は古いプライマリリージョンの可用性を監視します。そのリージョンが再び正常な状態になり利用可能になるとすぐに、Amazon DocumentDB はそのリージョンをセカンダリリージョンとしてグローバルクラスターに自動的に追加します。古いプライマリリージョンに新しいストレージボリュームを作成する前に、Amazon DocumentDB は障害発生時の古いストレージボリュームのスナップショットを取得しようとします。これにより、欠落しているデータを回復することができます。このオペレーションが成功すると、Amazon DocumentDB は「rds:docdb-unplanned-global-failover-name-of-old-primary-DB-cluster-timestamp」という名前のスナップショットを AWS Management Consoleのスナップショットセクションに格納します。このスナップショットは、DescribeDBClusterSnapshots API オペレーションによって返される情報にもリストアップされます。
注記
古いストレージボリュームのスナップショットは、古い主クラスターに設定されたバックアップ保持期間の対象となるシステムスナップショットです。このスナップショットを保存期間外に保存するには、スナップショットをコピーして手動スナップショットとして保存できます。価格などのスナップショットのコピーの詳細については、「クラスタースナップショットのコピー」を参照してください。
元のトポロジを復元できたら、ビジネスとワークロードにとって最も都合のよいタイミングでスイッチオーバーオペレーションを実行することで、グローバルクラスターを元のプライマリリージョンにフェイルバックします。これを行うには、「Amazon DocumentDB グローバルクラスターのスイッチオーバーの実行」の手順を実行します。
Amazon DocumentDB グローバルクラスターは、 AWS Management Console、、 AWS CLIまたは Amazon DocumentDB API を使用してフェイルオーバーできます。
Amazon DocumentDB グローバルクラスターの手動フェイルオーバーの実行
1 つの 内のクラスター全体が使用 AWS リージョン できなくなった場合は、グローバルクラスター内の別のクラスターを昇格させて読み取り/書き込み機能を持つことができます。
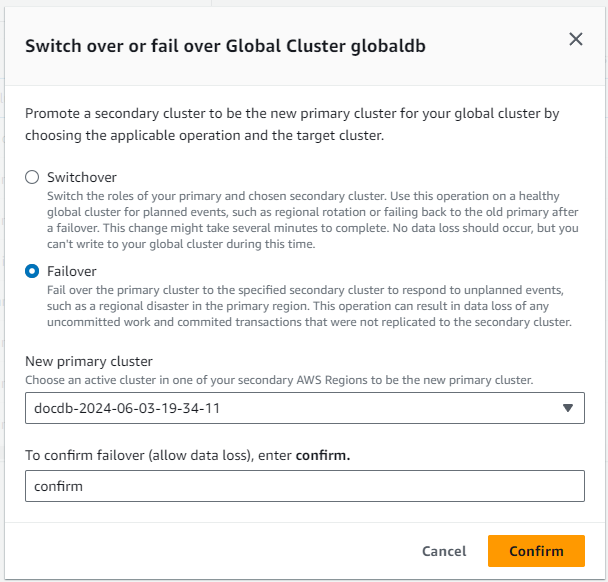
別の AWS リージョン にあるクラスターがプライマリクラスターとしてより適格であると判断される場合は、グローバルクラスターフェイルオーバー機能を手動で起動することができます。たとえば、特定のセカンダリクラスターの容量を増やして、プライマリクラスターに昇格させることもできます。または、 間のアクティビティのバランスが AWS リージョン 変化する可能性があるため、プライマリクラスターを別のクラスターに切り替えると、書き込みオペレーションのレイテンシーが低下する AWS リージョン 可能性があります。
次の手順では、Amazon DocumentDB グローバルクラスターのセカンダリクラスターの 1 つを昇格させる方法を説明します。
セカンダリクラスターを昇格させるには
-
停止 AWS リージョン した のプライマリクラスターへの DML ステートメントやその他の書き込みオペレーションの発行を停止します。
-
新しいプライマリクラスター AWS リージョン として使用するセカンダリからクラスターを特定します。グローバルクラスター AWS リージョン に 2 つ (またはそれ以上) のセカンダリがある場合は、ラグタイムが最も短いセカンダリクラスターを選択します。
-
選択したセカンダリクラスターをグローバルクラスターからデタッチします。
グローバルクラスターからセカンダリクラスターを削除すると、プライマリからこのセカンダリへのレプリケーションが直ちに停止され、完全な読み取り/書き込み機能を備えたスタンドアロンのプロビジョニングクラスターへと昇格されます。停止しているリージョン内のプライマリクラスターに関連付けられたその他のセカンダリクラスターは引き続き利用可能で、アプリケーションからの呼び出しを受け付けることができます。また、リソースを使用することになります。グローバルクラスターを再作成するため、スプリットブレインなどの問題を回避するために、以下のステップで新しいグローバルクラスターを作成する前に、他のセカンダリクラスターを削除します。
アタッチ解除の詳細なステップについては、Amazon DocumentDB グローバルクラスターからのクラスターの削除 を参照してください。
-
このクラスターは、次のステップでリージョンを追加すると、新しいグローバルクラスターのプライマリクラスターになります。
-
クラスター AWS リージョン に を追加します。これを行うと、プライマリからセカンダリへのレプリケーションプロセスがスタートされます。
-
必要に応じて追加 AWS リージョン し、アプリケーションをサポートするために必要なトポロジを再作成します。グローバルクラスター内 (スプリットブレインの問題) のクラスター間のデータの不整合を避けるために、これらの変更を行う前、最中、および後に、アプリケーションの書き込みが正しいクラスターに送信されていることを確認してください。
-
停止状態が解決されて元の AWS リージョン をプライマリクラスターとして再度割り当てる準備が完了したら、同じステップを逆に実行します。
-
グローバルクラスターからセカンダリクラスターの 1 つを削除します。これにより、読み取り/書き込みトラフィックを提供できるようになります。
-
元の AWS リージョンのプライマリクラスターにすべての書き込みトラフィックをリダイレクトします。
-
を追加して AWS リージョン 、以前 AWS リージョン と同じ に 1 つ以上のセカンダリクラスターを設定します。
Amazon DocumentDB グローバルクラスターは AWS SDKs を使用して管理できるため、ディザスタリカバリとビジネス継続性計画のユースケースのグローバルクラスターフェイルオーバープロセスを自動化するソリューションを作成できます。そのようなソリューションの 1 つは、Apache 2.0 ライセンスに基づいてお客様に提供されており、こちら
Amazon DocumentDB グローバルクラスターのスイッチオーバーの実行
スイッチオーバーを使用すると、プライマリクラスターのリージョンを定期的に変更できます。この機能は、運用メンテナンス、その他の計画された運用手順など、管理されたシナリオを対象としています。
スイッチオーバーを使用する一般的なユースケースは 3 つあります。
特定の業界に課せられる「リージョナルローテーション」要件向け。たとえば、金融サービス規制では、ディザスタリカバリ手順が定期的に実施されるように、Tier-0 システムを別の地域に数か月間切り替えることが求められる場合があります。
マルチリージョンの「follow-the-sun」アプリケーション向け。たとえば、ある企業が、さまざまなタイムゾーンの営業時間に基づいて、さまざまなリージョンで低レイテンシーの書き込みを提供したいとします。
データ損失ゼロの方法として、フェイルオーバー後に元のプライマリリージョンにフェイルバックします。
注記
スイッチオーバーは、正常な Amazon DocumentDB グローバルクラスターでの使用向けに設計された機能です。予期しないシステム停止から回復するには、Amazon DocumentDB グローバルクラスターの手動フェイルオーバーの実行 の該当する手順に従ってください。
スイッチオーバーを実行するには、すべてのセカンダリリージョンがプライマリとまったく同じエンジンバージョンを実行している必要があります。リージョンのエンジンバージョンが一致しない場合、スイッチオーバーはブロックされます。保留中のアップグレードを確認して適用し、すべてのリージョンのエンジンバージョンが一致し、グローバルクラスターのスイッチオーバーがブロック解除されていることを確認してください。詳細については、「グローバルクラスターのスイッチオーバーまたはフェイルオーバーのブロック解除」を参照してください。
スイッチオーバー中、Amazon DocumentDB は、グローバルクラスターの既存のレプリケーショントポロジを維持しながら、プライマリクラスターを選択されたセカンダリリージョンにスイッチオーバーします。なお、Amazon DocumentDB は、すべてのセカンダリリージョンクラスターがプライマリリージョンクラスターと完全に同期されるまで待ってからスイッチオーバープロセスを開始します。次に、プライマリリージョンの DB クラスターは読み取り専用になり、選択したセカンダリ DB クラスターは、読み取り専用ノードの 1 つを、フルライターステータスに昇格させます。このノードをライターに昇格させると、そのセカンダリクラスターがプライマリクラスターの役割を引き受けることができます。プロセスの開始時にはすべてのセカンダリクラスターがプライマリと完全に同期されているため、新しいプライマリはデータを失うことなく Amazon DocumentDB グローバルクラスターのオペレーションを継続できます。プライマリクラスターと選択したセカンダリクラスターが新しいロールを引き受ける間、短時間データベースが使用できなくなります。
アプリケーションの可用性を最適化するには、この機能を使用する前に、次の操作を行うことをお勧めします。
この操作は、ピーク時以外の、プライマリクラスターへの書き込みが最小限である時間帯に実行してください。
各アプリケーションをオフラインにして、Amazon DocumentDB グローバルクラスターのプライマリクラスターへの書き込みが送信されないようにします。
Amazon CloudWatch 上で
GlobalClusterReplicationLagメトリクスを確認して、グローバルクラスター内のすべての Amazon DocumentDB セカンダリクラスターのラグタイムを確認します。このメトリクスは、セカンダリクラスターへのレプリケーションがプライマリクラスターに対してどのくらい遅れているかをミリ秒単位でを示します。この値は、Amazon DocumentDB がスイッチオーバーを完了するのにかかる時間と完全に比例します。したがって、遅延値が大きいほど、スイッチオーバーにかかる時間は長くなります。Amazon DocumentDB 向け CloudWatch メトリクスの詳細については、「Amazon DocumentDB のメトリクス」を参照してください。
スイッチオーバー中、選択したセカンダリ DB クラスターは、プライマリとして新しいロールに昇格されます。ただし、プライマリ DB クラスターのさまざまな設定オプションは継承されません。構成の不一致は、パフォーマンスの問題、ワークロードの非互換性、およびその他の異常な動作につながる可能性があります。このような問題を回避するには、Amazon DocumentDB グローバルクラスター間の次のような相違点を解消しておくことをお勧めします。
新しいプライマリ向けに Amazon DocumentDB のクラスターパラメータグループを構成する (必要な場合) — Amazon DocumentDB グローバルクラスター内の各クラスターごとに、Amazon DocumentDB クラスターパラメータグループを構成できます。つまり、セカンダリ DB クラスターを昇格してプライマリロールを引き継ぐ場合、セカンダリからのパラメータグループは、プライマリとは異なる設定になることがあります。その場合は、プロモートされたセカンダリ DB クラスターのパラメータグループを、プライマリクラスターの設定に適合するように変更します。この方法については、「Amazon DocumentDB クラスターパラメータグループの管理」を参照してください。
各種モニタリングツールやオプションを構成する (Amazon CloudWatch Events やアラームなど) - グローバルクラスターに必要なログ機能、アラームなどを使用して、昇格されたクラスターの設定を行います。パラメータグループと同様に、スイッチオーバープロセス中にこれらの機能の設定がプライマリから継承されることはありません。レプリケーションラグなどの一部の CloudWatch メトリクスは、プライマリリージョンのみで使用できます。そのため、スイッチオーバーによってメトリクスの表示方法やアラームの設定方法が変わり、定義済みのダッシュボードを変更する必要が生じる場合があります。詳細については、「Amazon DocumentDB のモニタリング」を参照してください。
注記
通常、ロールスイッチオーバーには数分かかることがあります。
スイッチオーバープロセスが完了すると、昇格された Amazon DocumentDB クラスターはグローバルクラスターへの書き込みオペレーションを処理できるようになります。
AWS Management Console または を使用してAmazon DocumentDB グローバルクラスターを切り替えることができます AWS CLI。

グローバルクラスターのスイッチオーバーまたはフェイルオーバーのブロック解除
グローバルクラスターのすべてのリージョンクラスターが同じエンジンバージョンにない場合、グローバルクラスターのスイッチオーバーとフェイルオーバーはブロックされます。バージョンが一致しない場合、スイッチオーバーまたはフェイルオーバーを呼び出すと、このエラーが表示されることがあります。指定されたターゲット DB クラスターは、ソース DB クラスターとは異なるパッチレベルでエンジンバージョンを実行しています。最新のエンジンバージョンを定期的に適用して、グローバルクラスターを正常な状態に保つために最新の更新を実行することをお勧めします。
このエラーを解決するには、まずすべてのセカンダリリージョンを更新し、次に保留中のメンテナンスアクション項目を適用してプライマリリージョンを同じエンジンバージョンに更新してください。保留中のメンテナンスアクション項目を表示し、問題を修正するために必要な変更を適用するには、次のいずれかのタブの手順を実行します。
