翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
を使用した Amazon EFS ファイルシステムのバックアップ AWS Data Pipeline
このトピックでは AWS Data Pipeline、EFS EFSの使用に関する情報を提供します。
注記
AWS Backup は、EFS ファイルシステム向けの推奨されるバックアップおよび復元ソリューションです。詳細については、「Amazon EFS ファイルシステムのバックアップ」を参照してください。
では AWS Data Pipeline、 AWS Data Pipeline サービスを使用してデータパイプラインを作成します。このパイプラインは、Amazon EFS ファイルシステム (実稼働ファイルシステムと呼ばれる) から別の Amazon EFS ファイルシステム (バックアップ ファイルシステムと呼ばれる) へデータをコピーします。
AWS Data Pipeline は、以下を実装するテンプレートで構成されています。
-
定義したスケジュール (時間単位、日単位、週単位、月単位など) に基づく自動バックアップ。
-
最も古いバックアップが、保持するバックアップの数に基づいて最新のバックアップに置き換えられる、バックアップの自動ローテーション。
-
あるバックアップから次のバックアップへの変更のみをバックアップする、rsync を使用したより迅速なバックアップ。
-
ハードリンクを使用したバックアップの効率的なストレージ。ハードリンクは、ファイルシステム内のファイルに名前を関連付けるディレクトリエントリです。ハードリンクを設定することにより、バックアップからバックアップに変更された内容だけを保存しながら、任意のバックアップからデータを完全に復元することができます。
バックアップソリューションを設定したら、このチュートリアルではバックアップにアクセスしてデータを復元する方法を示します。このバックアップソリューションは、 でホストされているスクリプトの実行に依存するため GitHub、 GitHub 可用性に影響されます。この依存関係を解消し、 Amazon S3 バケットでスクリプトをホストする場合は、Amazon S3 バケットでの rsync スクリプトのホスティング を参照してください。
重要
このソリューションでは、ファイルシステム AWS リージョン と同じ AWS Data Pipeline で を使用する必要があります。米国東部(オハイオ)では AWS Data Pipeline がサポートされていないため、このソリューションはその AWS リージョン では機能しません。このソリューションを使用してファイルシステムをバックアップする場合は、サポートされている他の のいずれかでファイルシステムを使用することをお勧めします AWS リージョン。
トピック
を使用した Amazon EFS バックアップのパフォーマンス AWS Data Pipeline
データのバックアップと復元を実行する場合、ファイルシステムのパフォーマンスは、ベースラインとバーストスループット容量を含む Amazon EFS パフォーマンス の影響を受けます。バックアップソリューションで使用されるスループットは、ファイルシステム全体のスループットに対してカウントされます。次の表は、バックアップウィンドウが15分であると仮定した場合に、このソリューションで動作する Amazon EFS ファイルシステムと Amazon EC2 インスタンスのサイズに関するレコメンデーションを示しています。
| EFS サイズ (平均ファイル サイズ 30 MB) | 毎日の変更ボリューム | 残りのバースト時間 | バックアップ エージェントの最小数 |
|---|---|---|---|
| 256 GB | 25 GB 未満 | 6.75 | 1 - m3.medium |
| 512 GB | 50 GB 未満 | 7.75 | 1 - m3.large |
| 1.0 TB | 75 GB 未満 | 11.75 | 2 - m3.large* |
| 1.5 TB | 125 GB 未満 | 11.75 | 2 - m3.xlarge* |
| 2.0 TB | 175 GB 未満 | 11.75 | 3 - m3.large* |
| 3.0 TB | 250 GB 未満 | 11.75 | 4 - m3.xlarge* |
* これらの見積もりは、1 TB 以上の EFS ファイルシステムに保存されたデータが、バックアップを複数のバックアップノードに分散できるように構成されていることを前提としています。複数ノードのサンプルスクリプトは、EFS ファイルシステムの第 1 レベルディレクトリの内容に基づいて、ノード間でバックアップの負荷を分割します。
たとえば、2 つのバックアップノードがある場合、1 つのノードは第 1 レベルのディレクトリにあるすべての偶数のファイルとディレクトリをバックアップします。奇数のノードは奇数のファイルとディレクトリについて同じ処理を行います。別の例では、Amazon EFS ファイルシステム内の 6 つのディレクトリと 4 つのバックアップノードを使用して、最初のノードが 1 番目と 5 番目のディレクトリをバックアップします。2 番目のノードが 2 番目と 6 番目のディレクトリをバックアップし、3 番目と 4 番目のノードが 3 番目と 4 番目のディレクトリをそれぞれバックアップします。
AWS Data Pipelineを使用した Amazon EFS のバックアップに関する考慮事項
AWS Data Pipelineを使用して Amazon EFS バックアップ ソリューションを実装するかどうかを決定するときは、次の点を考慮してください。
-
EFS バックアップへのこのアプローチには、多くの AWS リソースが含まれます。このソリューションでは、次のものを作成する必要があります。
-
1 つの実稼働ファイルシステムと、実稼働ファイルシステムの完全なコピーを含む 1 つのバックアップ ファイルシステムです。システムには、バックアップのローテーション期間におけるデータの増分変更も含まれます。
-
ライフサイクルが によって管理され AWS Data Pipeline、復元とスケジュールされたバックアップを実行する Amazon EC2 インスタンス。
-
データのバックアップ AWS Data Pipeline が定期的にスケジュールされているもの。
-
バックアップを復元 AWS Data Pipeline するための 。
このソリューションが実装されると、これらのサービスのアカウントへの課金が行われます。詳細については、Amazon EFS
、 Amazon EC2 、および AWS Data Pipeline の料金ページを参照してください。 -
-
このソリューションはオフラインでのバックアップソリューションではありません。完全に一貫性のある完全なバックアップを確保するには、ファイルシステムへのファイル書き込みを一時停止するか、バックアップの実行中にファイルシステムをマウント解除します。スケジュールされたダウンタイムまたは休止時間中にすべてのバックアップを実行することをお勧めします。
での Amazon EFS バックアップの前提 AWS Data Pipeline
このチュートリアルでは、いくつかの前提条件があり、次のようにサンプル値を宣言しています。
-
始める前に、このチュートリアルでは、開始方法 をすでに完了していることを前提としています。
-
「開始方法」の演習を完了したら、バックアップするファイルシステムの 2 つのセキュリティグループ、VPC サブネット、およびファイルシステム マウントターゲットがあります。このチュートリアルの残りの部分では、次のサンプル値を使用します。
-
このチュートリアルでバックアップするファイルシステムの ID は、
fs-12345678です。 -
マウントターゲットに関連付けられているファイルシステムのセキュリティグループは
efs-mt-sg (sg-1111111a)とします。 -
Amazon EC2 インスタンスが実稼働 EFS マウントポイントに接続する機能を許可するセキュリティグループは
efs-ec2-sg (sg-1111111b)とします。 -
VPC サブネットの ID の値は
subnet-abcd1234です。 -
バックアップするファイルシステムのソースファイルシステムのマウントターゲットの IP アドレスは
10.0.1.32:/とします。 -
この例では、実稼働ファイルシステムは、平均 30 MB のサイズのメディアファイルを提供するコンテンツ管理システムであることを想定しています。
-
前出の前提および例は、次の初期設定の図表に反映されています。
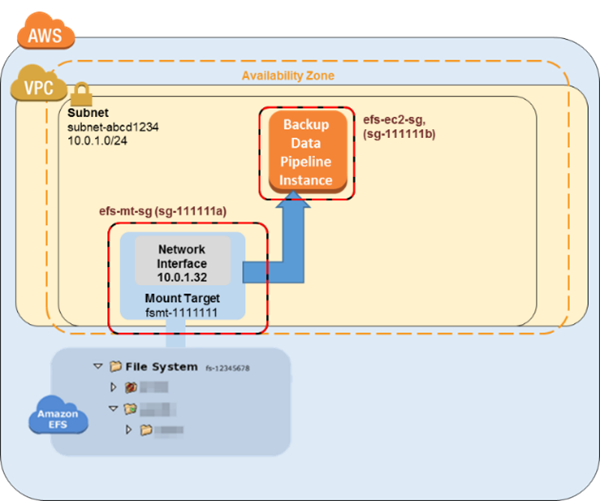
で Amazon EFS ファイルシステムをバックアップする方法 AWS Data Pipeline
このセクションのステップに従って、 AWS Data Pipelineを使用して Amazon EFS ファイルシステムをバックアップまたは復元します。
トピック
ステップ 1: バックアップ Amazon EFS ファイルシステムの作成
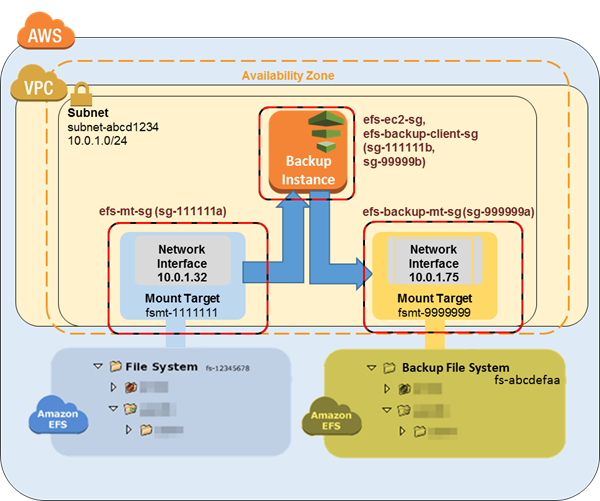
このチュートリアルでは、別々のセキュリティグループ、ファイルシステム、およびマウントポイントを作成して、データソースからバックアップを分離します。この最初のステップでは、これらのリソースを作成します。
-
まず、2 つのセキュリティグループを作成します。バックアップマウントターゲットのセキュリティグループの例は
efs-backup-mt-sg (sg-9999999a)です。マウントターゲットにアクセスする EC2 インスタンスのセキュリティグループ例はefs-backup-ec2-sg (sg-9999999b)です。これらのセキュリティグループをバックアップする EFS ボリュームと同じ VPC に作成することに注意します。この例では、subnet-abcd1234サブネットに関連付けられている VPC です。セキュリティグループの作成方法の詳細については、「セキュリティグループの作成」を参照してください。 -
次に、バックアップ Amazon EFS ファイルシステムを作成します。この例では、ファイルシステム ID は
fs-abcdefaaです。ファイルシステムの作成の詳細については、「Amazon EFS ファイルシステムの作成」を参照してください。 -
最後に、EFS バックアップファイルシステムのマウントポイントを作成し、
10.0.1.75:/の値を持つようにします。マウントターゲットの作成についての詳細は、マウントターゲットの作成とセキュリティグループの作成と管理 を参照してください。
この最初のステップを完了した後、設定は以下の図表の例のようになります。
ステップ 2: バックアップ用の AWS Data Pipeline テンプレートをダウンロードする
AWS Data Pipeline は、指定された間隔で異なる AWS コンピューティングサービスとストレージサービス間でデータを確実に処理および移動するのに役立ちます。 AWS Data Pipeline コンソールを使用して、テンプレートと呼ばれる事前設定済みのパイプライン定義を作成できます。これらのテンプレートを使用すると、 AWS Data Pipeline すぐに の使用を開始できます。このチュートリアルでは、バックアップパイプラインの設定プロセスを簡単にするためのテンプレートが提供されています。
このテンプレートを実装すると、実稼働ファイルシステムからバックアップ ファイルシステムにデータをバックアップするために指定したスケジュールで、単一の Amazon EC2 インスタンスを起動するデータ パイプラインが作成されます。このテンプレートには多くのプレースホルダー値があります。これらのプレースホルダーの一致する値は、 AWS Data Pipeline コンソールの Parameters セクションで指定します。バックアップの AWS Data Pipeline テンプレートを 1-Node-EFSBackupDataPipeline .json
注記
また、このテンプレートは、バックアップコマンドを実行するスクリプトを参照して実行します。パイプラインを作成する前にスクリプトをダウンロードして、そのスクリプトの内容を確認することができます。スクリプトを確認するには、 から efs-backup.sh
ステップ 3: バックアップのためのデータ パイプラインを作成する
データパイプラインを作成するには、次の手順を実行します。
Amazon EFS バックアップのためのデータパイプラインを作成するには
-
https://console.aws.amazon.com/datapipeline/
で AWS Data Pipeline コンソールを開きます。 重要
Amazon EFS ファイルシステム AWS リージョン と同じ で作業していることを確認してください。
-
[Create new pipeline] (新しいパイプラインの作成) を選択します。
-
[Name (名前)] の値および必要に応じて [Description (説明)] の値を追加します。
-
[Source (ソース)] で、[Import a definition (定義のインポート)] を選択してから、[Load local file (ローカルファイルのロード)] を選択します。
-
ファイルエクスプローラーで、ステップ 2: バックアップ用の AWS Data Pipeline テンプレートをダウンロードする で保存したテンプレートに移動し、[Open (開く)] を選択します。
-
[Parameters (パラメータ)] で、バックアップおよび実稼働 EFS ファイルシステムの両方の詳細を提供します。
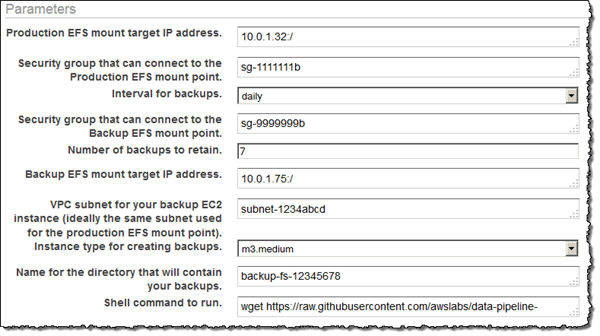
-
[Schedule (スケジュール)] でオプションを設定し、Amazon EFS バックアップのスケジュールを定義します。この例のバックアップは 1 日に 1 回実行され、バックアップは 1 週間保持されます。バックアップが 7 日を経過したら、次に古いバックアップに置き換えられます。
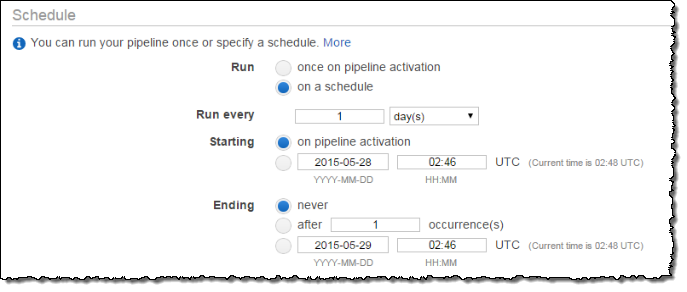
注記
オフピークの時間帯に発生するランタイムを指定することをお勧めします。
-
(オプション) パイプラインログの保存、カスタム IAM ロールの設定、またはパイプラインを説明するタグの追加に Amazon S3 の場所を指定します。
-
パイプラインを設定したら、[Activate (アクティブ化)] を選択します。
Amazon EFS バックアップ データ パイプラインを設定してアクティブ化しました。の詳細については AWS Data Pipeline、「 AWS Data Pipeline デベロッパーガイド」を参照してください。この段階では、今すぐテストとしてバックアップを実行するか、または、スケジュールされた時刻にバックアップが実行されるまで待つことができます。
ステップ 4: Amazon EFS バックアップにアクセスする
Amazon EFS バックアップが作成され、アクティブ化され、定義したスケジュールで実行されています。このステップでは、EFS バックアップにアクセスする方法の概要を説明します。バックアップは以下の形式で作成した EFS バックアップファイルシステムに保存されています。
backup-efs-mount-target:/efs-backup-id/[backup interval].[0-backup retention]-->
サンプルシナリオの値を使用すると、ファイルシステムのバックアップは 10.1.0.75:/fs-12345678/daily.[0-6] に配置されます。daily.0 が最新のバックアップで daily.6 は 7 つのローテーションバックアップの中で最も古いものです。
バックアップへアクセスすることで、実稼働ファイルシステムにデータを復元できます。ファイルシステム全体を復元するか、または個々のファイルを復元するかを選択できます。
ステップ 4.1: Amazon EFS バックアップ全体の復元
Amazon EFS ファイルシステムのバックアップコピーを復元するには AWS Data Pipeline、「」で設定したものと同様の別の が必要ですステップ 3: バックアップのためのデータ パイプラインを作成する。ただし、この復元パイプラインは、バックアップパイプラインの逆に作動します。通常、これらの復元は自動的に開始するようスケジュールされていません。
バックアップと同じように、復元も復旧時間の目標を満たすように並行して実行できます。データパイプラインを作成する場合、いつ実行するかをスケジュールする必要があることに注意してください。アクティベーションの時に実行することを選択した場合、復元処理をすぐにスタートします。復元をする必要がある場合にのみ、または特定の時間帯に実行することを計画している場合にのみ、復元パイプラインを作成することをお勧めします。
バックアップ EFS と復元 EFS の両方によりバーストキャパシティーが消費されます。パフォーマンスの詳細については、「Amazon EFS パフォーマンス」を参照してください。以下の手順では、復元パイプラインの作成および実装の方法を示します。
EFS データの復元のためにデータパイプラインを作成するには
-
バックアップ EFS ファイルシステムからデータを復元するためのデータパイプラインのテンプレートをダウンロードします。このテンプレートでは、指定されたサイズに基づいて 1 つの Amazon EC2 インスタンスを起動します。これを起動するように指定した場合にのみ起動します。バックアップ用の AWS Data Pipeline テンプレートを 1-Node-EFSRestoreDataPipeline .json
で からダウンロードします GitHub。 注記
また、このテンプレートは、復元コマンドを実行するスクリプトを参照して実行します。パイプラインを作成する前にスクリプトをダウンロードして、そのスクリプトの内容を確認することができます。スクリプトを確認するには、 から efs-restore.sh
をダウンロードします GitHub。 -
https://console.aws.amazon.com/datapipeline/
で AWS Data Pipeline コンソールを開きます。 重要
Amazon EFS ファイルシステムおよび Amazon EC2 AWS リージョン と同じ で作業していることを確認してください。
-
[Create new pipeline] (新しいパイプラインの作成) を選択します。
-
[Name (名前)] の値および必要に応じて [Description (説明)] の値を追加します。
-
[Source (ソース)] で、[Import a definition (定義のインポート)] を選択してから、[Load local file (ローカルファイルのロード)] を選択します。
-
ファイル エクスプローラーで、ステップ 1: バックアップ Amazon EFS ファイルシステムの作成 で保存したテンプレートに移動し、[Open (開く)] を選択します。
-
[Parameters (パラメータ)] で、バックアップおよび実稼働 EFS ファイルシステムの両方の詳細を提供します。
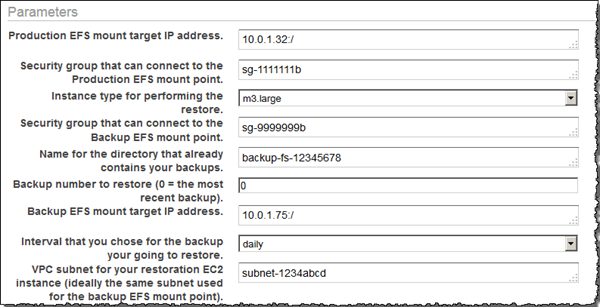
-
通常は必要なときにのみ復元を実行するので、復元を [once on pipeline activation (パイプラインのアクティブ化中に一度)] 実行するようにスケジュールできます。または、オフピーク期間中など、指定した将来の時間に 1 回限り復元を実行するようスケジュールすることもできます。
-
(オプション) パイプラインログの保存、カスタム IAM ロールの設定、またはパイプラインを説明するタグの追加に Amazon S3 の場所を指定します。
-
パイプラインを設定したら、[Activate (アクティブ化)] を選択します。
Amazon EFS 復元データパイプラインを設定してアクティブ化しました。本番稼働用 EFS ファイルシステムにバックアップを復元する必要がある場合は、 AWS Data Pipeline コンソールからアクティブ化するだけです。詳細については、AWS Data Pipeline デベロッパーガイドを参照してください。
ステップ 4.2: Amazon EFS バックアップから個別のファイルを復元する
Amazon EC2 インスタンスを起動して一時的に実稼働およびバックアップ Amazon EFS ファイルシステムの両方をマウントすることで、 ファイルシステムのバックアップからファイルを復元することができます。EC2 インスタンスは、両方の EFS クライアントセキュリティグループ (この例では efs-ec2-sg と efs-backup-clients-sg) のメンバーである必要があります。両方の EFS マウントターゲットをこの復元インスタンスでマウントできます。たとえば、リカバリ EC2 インスタンスで次のマウントポイントを作成できます。ここでは、-o ro オプションを使用して、バックアップ EFS を読み取り専用としてマウントし、バックアップから復元しようとする際、誤ってバックアップが変更されないようにします。
mount -t nfssource-efs-mount-target:/ /mnt/data
mount -t nfs -o robackup-efs-mount-target:/fs-12345678/daily.0 /mnt/backup>
ターゲットをマウントした後、 cp
-p コマンドを使用して、ターミナルで /mnt/backup から /mnt/data の適切な場所にファイルをコピーすることができます。たとえば、次のコマンドを使用して、ホームディレクトリ全体 (ファイルシステムのアクセス許可を含む) を再帰的にコピーできます。
sudo cp -rp /mnt/backup/users/my_home /mnt/data/users/my_home
次のコマンドを実行することで、1 つのファイルを復元できます。
sudo cp -p /mnt/backup/user/my_home/.profile /mnt/data/users/my_home/.profile
警告
個々のデータファイルを手動で復元する場合は、誤ってバックアップ自体を変更しないように注意してください。そうしないと、データが破損する可能性があります。
追加のバックアップリソース
このチュートリアルで説明するバックアップソリューションでは、 の テンプレートを使用します AWS Data Pipeline。ステップ 2: バックアップ用の AWS Data Pipeline テンプレートをダウンロードする および ステップ 4.1: Amazon EFS バックアップ全体の復元 で使用したテンプレートは両方とも単一の Amazon EC2 インスタンスを使用し操作を実行しています。ただし、Amazon EFS ファイルシステムでデータをバックアップまたは復元するために実行できる並列インスタンスの数には、実際の制限はありません。このトピックでは、バックアップソリューションをダウンロードして使用できる複数の EC2 インスタンス用に設定された他の AWS Data Pipeline テンプレートへのリンクを示します。追加のインスタンスを含めるようにテンプレートを変更する方法も示してあります。
追加テンプレートの使用
以下の追加テンプレートは、 からダウンロードできます GitHub。
-
2-Node-EFSBackupPipeline .json
– このテンプレートは、2 つの並列 Amazon EC2 インスタンスを起動して、本番稼働用の Amazon EFS ファイルシステムをバックアップします。 -
2-Node-EFSRestorePipeline .json
– このテンプレートは、2 つの並列 Amazon EC2 インスタンスを起動して、本番稼働用の Amazon EFS ファイルシステムのバックアップを復元します。
バックアップインスタンスの追加
このチュートリアルで使用するバックアップテンプレートにノードを追加できます。ノードを追加するには、2-Node-EFSBackupDataPipeline.json テンプレートの以下のセクションを変更します。
重要
追加のノードを使用している場合、最上位ディレクトリに保存されているファイル名とディレクトリにはスペースを使用できません。そうした場合、それらのファイルとディレクトリではバックアップや復元はされません。トップレベルより少なくとも 1 レベル下のすべてのファイルとサブディレクトリは、バックアップされ、想定どおりに復元されます。
-
作成したい追加のノードごとに追加の EC2Resource を作成します (この例では、4 番目の EC2 インスタンス)。
{ "id": "EC2Resource4", "terminateAfter": "70 Minutes", "instanceType": "#{myInstanceType}", "name": "EC2Resource4", "type": "Ec2Resource", "securityGroupIds" : [ "#{mySrcSecGroupID}","#{myBackupSecGroupID}" ], "subnetId": "#{mySubnetID}", "associatePublicIpAddress": "true" }, -
追加のノード (この場合はアクティビティ
BackupPart4) ごとに追加のデータパイプラインアクティビティを作成し、次のセクションを必ず設定してください。-
以前に作成した EC2Resource を指すように
runsOnリファレンスを更新します (以下の例のEC2Resource4)。 -
最後の 2 つの
scriptArgument値を各ノードが担当するバックアップ部分およびノードの合計数と等しくなるよう増分します。以下の例の"2"および"3"では、係数の論理で、0 から数え始める必要があるため、この例の 4 番目のノードのバックアップ部分は"3"となります。
{ "id": "BackupPart4", "name": "BackupPart4", "runsOn": { "ref": "EC2Resource4" }, "command": "wget https://raw.githubusercontent.com/awslabs/data-pipeline-samples/master/samples/EFSBackup/efs-backup-rsync.sh\nchmod a+x efs-backup-rsync.sh\n./efs-backup-rsync.sh $1 $2 $3 $4 $5 $6 $7", "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "3", "4"], "type": "ShellCommandActivity", "dependsOn": { "ref": "InitBackup" }, "stage": "true" }, -
-
ノード数にすべての既存の
scriptArgument値の最後の値を増分します (この例では"4")。{ "id": "BackupPart1", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "1", "4"], ... }, { "id": "BackupPart2", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "2", "4"], ... }, { "id": "BackupPart3", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myRetainedBackups}","#{myEfsID}", "0", "4"], ... }, -
FinalizeBackupアクティビティを更新し、dependsOnリストに新しいバックアップアクティビティを追加します (この場合はBackupPart4)。{ "id": "FinalizeBackup", "name": "FinalizeBackup", "runsOn": { "ref": "EC2Resource1" }, "command": "wget https://raw.githubusercontent.com/awslabs/data-pipeline-samples/master/samples/EFSBackup/efs-backup-end.sh\nchmod a+x efs-backup-end.sh\n./efs-backup-end.sh $1 $2", "scriptArgument": ["#{myInterval}", "#{myEfsID}"], "type": "ShellCommandActivity", "dependsOn": [ { "ref": "BackupPart1" }, { "ref": "BackupPart2" }, { "ref": "BackupPart3" }, { "ref": "BackupPart4" } ], "stage": "true"
復元インスタンスをさらに追加する
このチュートリアルで使用する復元テンプレートにノードを追加できます。ノードを追加するには、2-Node-EFSRestorePipeline.json テンプレートの以下のセクションを変更します。
-
作成したい追加のノードごとに、追加の EC2Resource を作成します (この例では、3 番目の
EC2Resource3という EC2 インスタンス)。{ "id": "EC2Resource3", "terminateAfter": "70 Minutes", "instanceType": "#{myInstanceType}", "name": "EC2Resource3", "type": "Ec2Resource", "securityGroupIds" : [ "#{mySrcSecGroupID}","#{myBackupSecGroupID}" ], "subnetId": "#{mySubnetID}", "associatePublicIpAddress": "true" }, -
追加のノード (この場合はアクティビティ
RestorePart3) ごとに追加のデータパイプラインアクティビティを作成します。次のセクションを必ず設定してください。-
以前に作成した
EC2Resource(この例ではEC2Resource3) を指すようにrunsOnリファレンスを更新します。 -
最後の 2 つの
scriptArgument値を各ノードが担当するバックアップ部分およびノードの合計数と等しくなるよう増分します。以下の例の"2"および"3"では、係数の論理で、0 から数え始める必要があるため、この例の 4 番目のノードのバックアップ部分は"3"となります。
{ "id": "RestorePart3", "name": "RestorePart3", "runsOn": { "ref": "EC2Resource3" }, "command": "wget https://raw.githubusercontent.com/awslabs/data-pipeline-samples/master/samples/EFSBackup/efs-restore-rsync.sh\nchmod a+x efs-restore-rsync.sh\n./efs-backup-rsync.sh $1 $2 $3 $4 $5 $6 $7", "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myBackup}","#{myEfsID}", "2", "3"], "type": "ShellCommandActivity", "dependsOn": { "ref": "InitBackup" }, "stage": "true" }, -
-
ノード数にすべての既存の
scriptArgument値の最後の値を増分します (この例では"3")。{ "id": "RestorePart1", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myBackup}","#{myEfsID}", "1", "3"], ... }, { "id": "RestorePart2", ... "scriptArgument": ["#{myEfsSource}","#{myEfsBackup}", "#{myInterval}", "#{myBackup}","#{myEfsID}", "0", "3"], ... },
Amazon S3 バケットでの rsync スクリプトのホスティング
このバックアップソリューションは、インターネット上のリポジトリで GitHubホストされている rsync スクリプトの実行に依存します。したがって、このバックアップソリューションはリポジトリが GitHub使用可能であることの対象となります。この要件は、 GitHub リポジトリがこれらのスクリプトを削除するか、 GitHub ウェブサイトがオフラインになった場合、前述のバックアップソリューションが機能しないことを意味します。
この GitHub 依存関係を排除したい場合は、代わりに所有している Amazon S3 バケットでスクリプトをホストすることを選択できます。以下に、自分でスクリプトをホストするために必要なステップを示します。
rsync スクリプトを独自の Amazon S3 バケットでホストするには
-
にサインアップ AWS して管理ユーザーを作成する – をすでにお持ちの場合は AWS アカウント、次のステップに進みます。それ以外の場合は、「セットアップ」を参照してください。
-
Amazon S3 バケットを作成する – rsync スクリプトをホストするバケットがすでにある場合は、次のステップに進みます。それ以外の場合は、Amazon Simple ストレージサービス ユーザーガイドの「バケットを作成する」を参照してください。
-
rsync スクリプトとテンプレートをダウンロードする – EFSBackup フォルダ
内のすべての rsync スクリプトとテンプレートを からダウンロードします GitHub。これらのファイルをダウンロードしたコンピュータの場所をメモしておきます。 -
rsync スクリプトを S3 バケットにアップロードする – S3 バケットにオブジェクトをアップロードする手順については、Amazon Simple ストレージサービス ユーザーガイド にある「バケットへのオブジェクトの追加」を参照してください。
-
アップロードされた rsync スクリプトのアクセス許可を変更し、[Everyone (誰でも)] それらを [Open/Download (開く/ダウンロード)] 出来るようにします。S3 バケットのオブジェクトのアクセス許可を変更する手順については、「Amazon Simple ストレージサービス ユーザーガイド」にある「オブジェクトに対するアクセス許可を編集する」を参照してください。
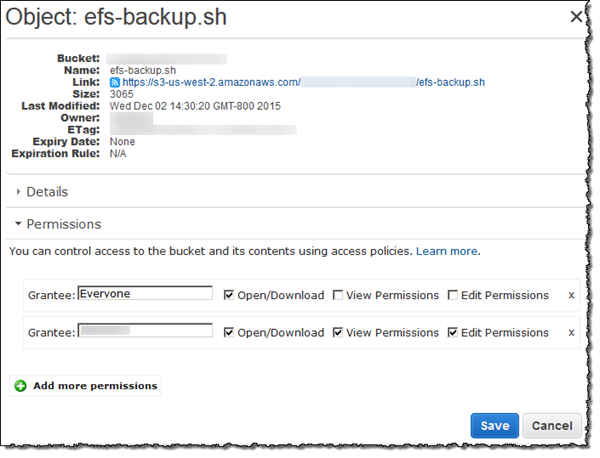
-
テンプレートを更新する –
shellCmdパラメータのwgetステートメントを変更して、スタートアップ スクリプトを置いた Amazon S3 バケットを指すようにします。更新されたテンプレートを保存し、ステップ 3: バックアップのためのデータ パイプラインを作成する の手順を実行するときにそのテンプレートを使用します。注記
Amazon S3 バケットへのアクセスを制限して、このバックアップソリューション AWS Data Pipeline の をアクティブ化する IAM アカウントを含めることをお勧めします。手順については、Amazon Simple ストレージサービス ユーザーガイド の「バケットのアクセス許可の編集」を参照してください。
これで、このバックアップソリューションの rsync スクリプトをホストし、バックアップは GitHub 可用性に依存しなくなりました。
