翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Kubernetes スケーリング理論
ノードとチャーンレート
多くの場合、Kubernetes のスケーラビリティについて議論するときは、1 つのクラスターに存在するノードの数に関して議論します。興味深いことに、これはスケーラビリティを理解するために最も有用なメトリクスになることはほとんどありません。たとえば、ポッド数が多く固定数の 5,000 個のノードクラスターでは、初期設定後にコントロールプレーンに大きなストレスがかかりません。ただし、1,000 個のノードクラスターを使用し、1 分未満で 10,000 個の短期間のジョブを作成しようとすると、コントロールプレーンに大きな負担がかかります。
単純にノード数を使用してスケーリングを理解すると、誤解を招く可能性があります。特定の期間内に発生する変化率について考えることをお勧めします (Prometheus クエリがデフォルトで通常使用するものであるため、この説明では 5 分間隔で使用しましょう)。変更率の観点から問題をフレーミングすることで、希望する規模を達成するために何を調整すべきかをよりよく理解できる理由を見てみましょう。
1 秒あたりのクエリ数で考える
Kubernetes には、Kubelet、スケジューラ、Kube Controller Manager、API サーバーなど、コンポーネントごとに多数の保護メカニズムがあり、Kubernetes チェーンの次のリンクが圧倒されるのを防ぎます。たとえば、Kubelet には API サーバーへの呼び出しを一定のレートでスロットリングするフラグがあります。これらの保護メカニズムは通常、1 秒あたりに許可されるクエリまたは QPS で表されますが、必ずしも表されません。
これらの QPS 設定を変更するときは、細心の注意が必要です。Kubelet での 1 秒あたりのクエリ数など、1 つのボトルネックを削除すると、他のダウンストリームコンポーネントに影響します。これにより、システムが特定のレートを超える可能性があるため、Kubernetes でワークロードを正常にスケーリングするには、サービスチェーンの各部分を理解してモニタリングすることが重要です。
注記
API サーバーには、API Priority and Fairness が導入された、より複雑なシステムがあります。これについては、別途説明します。
注記
注意点として、一部のメトリクスは適切であるように見えますが、実際には他のメトリクスを測定しています。例として、 は、Kubelet から apiserver へのリクエストの数ではなく、Kubelet のメトリクスサーバーにのみkubelet_http_inflight_requests関連します。これにより、Kubelet の QPS フラグの設定が誤る可能性があります。特定の Kubelet の監査ログに対するクエリは、メトリクスをチェックするより信頼性の高い方法です。
分散コンポーネントのスケーリング
EKS はマネージドサービスであるため、Kubernetes コンポーネントを etcd、Kube Controller Manager、スケジューラ (図の左側) を含む AWS マネージドコンポーネントと、Kubelet、Container Runtime、Networking and Storage ドライバー (図の右側) などの AWS APIs を呼び出すさまざまなオペレーターなどのお客様が設定可能なコンポーネントという 2 つのカテゴリに分割しましょう。API サーバーの優先度と公平性の設定はお客様が設定できるため、AWS が管理している場合でも API サーバーを中間のままにします。
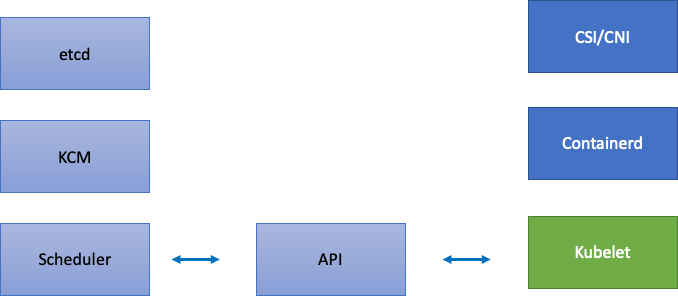
アップストリームとダウンストリームのボトルネック
各サービスをモニタリングするときは、ボトルネックを探すために、双方向のメトリクスを確認することが重要です。これを行う方法については、例として Kubelet を使用します。Kubelet は API サーバーとコンテナランタイムの両方と通信します。いずれかのコンポーネントで問題が発生しているかどうかを検出するには、どのように、何をモニタリングする必要がありますか?
ノードあたりのポッド数
ノードで実行できるポッドの数などのスケーリング番号を見ると、アップストリームが顔の値でサポートするノードごとに 110 個のポッドを取ることができます。
ただし、ワークロードは、アップストリームのスケーラビリティテストでテストされたものよりも複雑である可能性があります。本番環境で実行するポッドの数を確実に処理できるように、Kubelet が Containerd ランタイムに「維持」されていることを確認します。
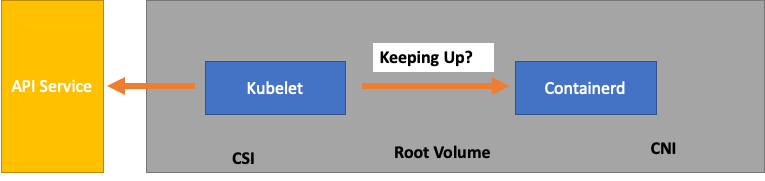
シンプルにするために、Kubelet はコンテナランタイム (この場合は Containerd) からポッドのステータスを取得しています。ステータスの変更が早すぎるポッドが多すぎた場合はどうなりますか? 変更率が高すぎると、〔コンテナランタイムへの] リクエストがタイムアウトする可能性があります。
注記
Kubernetes は常に進化しており、このサブシステムは現在変更中です。https://github.com/kubernetes/enhancements/issues/3386

上記のグラフでは、ポッドライフサイクルイベント生成期間メトリクスのタイムアウト値に達したことを示すフラットな線が表示されています。これを独自のクラスターで表示する場合は、次の PromQL 構文を使用できます。
increase(kubelet_pleg_relist_duration_seconds_bucket{instance="$instance"}[$__rate_interval])
このタイムアウト動作を目撃した場合、ノードが可能な制限を超えてプッシュされたことがわかります。先に進む前に、タイムアウトの原因を修正する必要があります。これは、ノードあたりのポッド数を減らすか、大量の再試行を引き起こしている可能性のあるエラー (解約率に影響する) を探すことで実現できます。重要なポイントは、ノードが割り当てられたポッドの解約率と固定数の使用を処理できるかどうかを、メトリクスが理解する最善の方法です。
メトリクスによるスケーリング
メトリクスを使用してシステムを最適化するという概念は古いものですが、Kubernetes ジャーニーを開始すると見落とされがちです。特定の数値 (ノードあたり 110 個のポッド) に焦点を当てるのではなく、システム内のボトルネックを見つけるのに役立つメトリクスを見つけることに重点を置いています。これらのメトリクスの適切なしきい値を理解することで、システムが最適に構成されているという高い信頼性が得られます。
変更の影響
問題が発生する可能性がある一般的なパターンは、疑わしい最初のメトリクスまたはログエラーに焦点を当てることです。以前に Kubelet がタイムアウトしていたことがわかったら、Kubelet が送信できる 1 秒あたりのレートを増やすなど、ランダムなことを試すことができます。ただし、最初に見つかったエラーの下流にあるすべての全体像を見るのが賢明です。目的とデータに基づいて各変更を行います。
Kubelet のダウンストリームは、Containerd ランタイム (ポッドエラー)、ストレージドライバー (CSI) などの DaemonSets、EC2 API と通信するネットワークドライバー (CNI) などです。
前の Kubelet がランタイムに追いついていない例を続行しましょう。ノードを密に格納してエラーをトリガーできる点がいくつかあります。
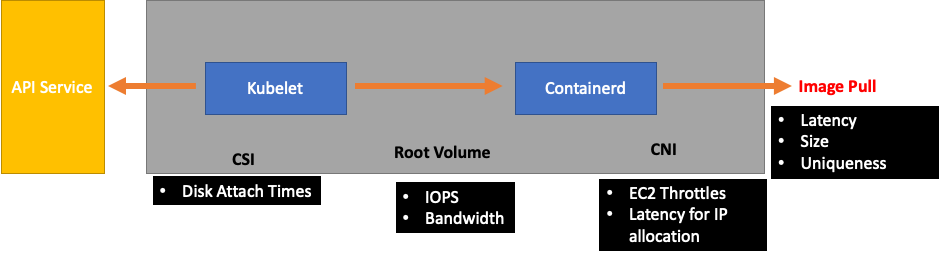
ワークロードに適したノードサイズを設計する場合、これらはeasy-to-overlookシグナルであり、システムに不要な負荷がかかり、スケールとパフォーマンスの両方が制限されている可能性があります。
不要なエラーのコスト
Kubernetes コントローラーは、エラー状態が発生した場合の再試行に優れていますが、これにはコストがかかります。これらの再試行により、Kube Controller Manager などのコンポーネントへの負荷が増加する可能性があります。このようなエラーをモニタリングすることは、スケールテストの重要なテナントです。
エラーが少なくなると、システム内の問題を見つけやすくなります。大規模なオペレーション (アップグレードなど) の前にクラスターにエラーがないことを定期的に確認することで、予期しないイベントが発生したときのトラブルシューティングログを簡素化できます。
ビューの展開
何千ものノードを持つ大規模なクラスターでは、ボトルネックを個別に探したくないと考えています。PromQL では、topk という関数を使用してデータセット内の最大値を見つけることができます。K は必要な項目数を配置する変数です。ここでは、3 つのノードを使用して、クラスター内のすべての Kubelets が飽和しているかどうかを把握します。ここまでレイテンシーを調べてきました。次に、Kubelet がイベントを破棄しているかどうかを見てみましょう。
topk(3, increase(kubelet_pleg_discard_events{}[$__rate_interval]))
このステートメントを破棄します。
-
Grafana 変数を使用して
$__rate_interval、必要な 4 つのサンプルを取得します。これにより、シンプルな変数を使用したモニタリングの複雑なトピックがバイパスされます。 -
topkは上位の結果のみを提供し、数値 3 はそれらの結果を 3 に制限します。これは、クラスター全体のメトリクスに便利な関数です。 -
{}フィルターがないことを に知らせます。通常は、スクレイピングルールのジョブ名を入力しますが、これらの名前は異なるため、空白のままにします。
問題を半分に分割する
システムのボトルネックに対処するために、アップストリームまたはダウンストリームに問題があることを示すメトリクスを見つけるアプローチを取ります。これにより、問題を半分に分割できます。また、メトリクスデータの表示方法の中核となる原則でもあります。
このプロセスを開始するのに適した場所は API サーバーです。クライアントアプリケーションまたはコントロールプレーンに問題があるかどうかを確認できます。
