翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon EMR on EKS のご利用開始にあたって
このトピックを参照し、仮想クラスターに Spark アプリケーションをデプロイすることで、EKS での Amazon EMR を使い始めるのに役立ちます。これには、正しいアクセス許可を設定し、ジョブを開始する手順が含まれています。開始する前に、「Amazon EMR on EKS のセットアップ」の手順を完了しておくようにしてください。これにより、仮想クラスターを作成する前に AWS CLI のセットアップなどのツールを取得できます。開始時に役立つ他のテンプレートについては、GitHub の「EMR Containers Best Practices Guide
セットアップ手順の次の情報が必要になります。
-
Amazon EMR に登録された Amazon EKS クラスターおよび Kubernetes 名前空間の仮想クラスター ID
重要
EKS クラスターを作成する際は、m5.xlarge をインスタンスタイプとして使用するか、CPU とメモリがそれよりも高いその他のインスタンスタイプを使用してください。CPU またはメモリが m5.xlarge よりも低いインスタンスタイプを使用すると、クラスターで使用可能なリソースが不足することによるジョブの失敗につながる可能性があります。
-
ジョブの実行に使用する IAM ロールの名前
-
Amazon EMR リリースのリリースラベル (たとえば、
emr-6.4.0-latestなど) -
ロギングおよびモニタリングの送信先ターゲット:
-
Amazon CloudWatch ロググループ名とログストリームのプレフィックス
-
イベントログとコンテナログを保存する Amazon S3 の場所
-
重要
Amazon EMR on EKS ジョブでは、モニタリングとログの送信先ターゲットとして Amazon CloudWatch と Amazon S3 を使用します。これらの送信先に送信されるジョブログを表示することで、ジョブの進行状況をモニタリングし、エラーのトラブルシューティングを行うことができます。ログを有効にするには、ジョブの実行の IAM ロールに関連付けられた IAM ポリシーに、ターゲットリソースへのアクセスに必要なアクセス許可が必要です。必要なアクセス許可が IAM ポリシーにない場合は、このサンプルジョブを実行する前に、ジョブ実行ロールの信頼ポリシーを更新する、Configure a job run to use Amazon S3 logs、および Configure a job run to use CloudWatch Logs のステップに従う必要があります。
Spark アプリケーションの実行
次のステップに従って、EKS での Amazon EMR でシンプルな Spark アプリケーションを実行します。Spark Python アプリケーションのアプリケーション entryPoint ファイルは、s3:// にあります。REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.pyREGION は、us-east-1 など、Amazon EMR on EKS 仮想クラスターが存在するリージョンです。
-
次のポリシーステートメントで示すように、必要なアクセス許可があるジョブ実行ロールの IAM ポリシーを更新します。
-
このポリシーの最初のステートメントである
ReadFromLoggingAndInputScriptBucketsは、ListBucketおよびGetObjectsに次の Amazon S3 バケットへのアクセスを許可します。-
REGION.elasticmapreduceentryPointファイルが配置されているバケット。 -
amzn-s3-demo-destination-bucket- 出力データ用に定義するバケット。 -
amzn-s3-demo-logging-bucket‐ ログ記録データ用に定義するバケット。
-
-
このポリシーの 2 番目のステートメントである
WriteToLoggingAndOutputDataBucketsは、出力バケットとログバケットにそれぞれデータを書き込むアクセス許可をジョブに付与します。 -
3 番目のステートメントである
DescribeAndCreateCloudwatchLogStreamは、Amazon CloudWatch Logs を記述して作成するアクセス許可をジョブに付与します。 -
4 番目のステートメントである
WriteToCloudwatchLogsは、my_log_stream_prefixmy_log_group_name
-
-
Spark Python アプリケーションを実行するには、次のコマンドを使用します。置き換え可能なすべての
赤の斜体で示されている値を適切な値に置き換えます。REGIONは、us-east-1など、Amazon EMR on EKS 仮想クラスターが存在するリージョンです。aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.4.0-latest\ --job-driver '{ "sparkSubmitJobDriver": { "entryPoint": "s3://REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.py", "entryPointArguments": ["s3://amzn-s3-demo-destination-bucket/wordcount_output"], "sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'このジョブからの出力データは、
s3://で使用できます。amzn-s3-demo-destination-bucket/wordcount_outputジョブ実行に指定されたパラメータを使用して、JSON ファイルを作成することもできます。次に、JSON ファイルへのパスを指定して
start-job-runコマンドを実行します。詳細については、StartJobRun でジョブ実行を送信する を参照してください。ジョブ実行パラメータの設定について詳しくは、ジョブ実行を構成するためのオプション を参照してください。 -
Spark SQL アプリケーションを実行するには、次のコマンドを使用します。すべての
赤の斜体で示されている値を適切な値に置き換えます。REGIONは、us-east-1など、Amazon EMR on EKS 仮想クラスターが存在するリージョンです。aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.7.0-latest\ --job-driver '{ "sparkSqlJobDriver": { "entryPoint": "s3://query-file.sql", "sparkSqlParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'SQL クエリファイルの例を以下に示します。テーブルのデータが保存される S3 などの外部ファイルストアが必要です。
CREATE DATABASE demo; CREATE EXTERNAL TABLE IF NOT EXISTS demo.amazonreview( marketplace string, customer_id string, review_id string, product_id string, product_parent string, product_title string, star_rating integer, helpful_votes integer, total_votes integer, vine string, verified_purchase string, review_headline string, review_body string, review_date date, year integer) STORED AS PARQUET LOCATION 's3://URI to parquet files'; SELECT count(*) FROM demo.amazonreview; SELECT count(*) FROM demo.amazonreview WHERE star_rating = 3;このジョブの出力は、設定されている
monitoringConfigurationに応じて S3 または CloudWatch のドライバーの stdout ログに表示されます。 -
ジョブ実行に指定されたパラメータを使用して、JSON ファイルを作成することもできます。次に、JSON ファイルへのパスを指定して start-job-run コマンドを実行します。詳細については、「Submit a job run」を参照してください。ジョブ実行パラメータの設定について詳しくは、「Options for configuring a job run」を参照してください。
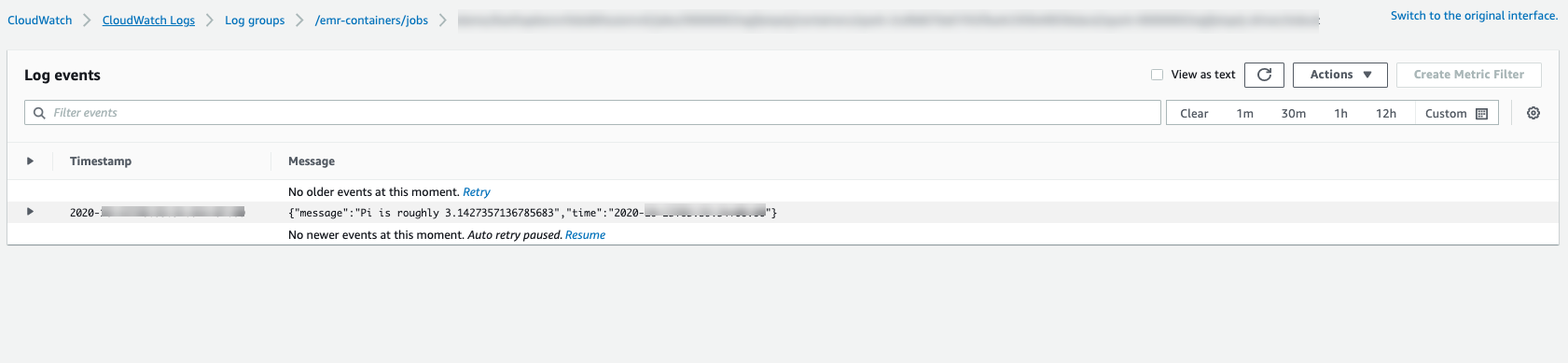
ジョブの進行状況をモニタリングしたり、失敗をデバッグしたりするには、Amazon S3、CloudWatch Logs、またはその両方にアップロードされたログを検査します。Amazon S3 のログパスについては、Configure a job run to use S3 logs を参照してください。CloudWatch Logs については、Configure a job run to use CloudWatch Logs を参照してください。CloudWatch Logs でログを表示するには、以下の手順に従います。
-
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 -
ナビゲーションペインで [ログ] を選択します。次に、[ロググループ] を選択します。
-
Amazon EMR on EKS のロググループを選択したら、アップロードされたログイベントを表示します。
-
重要
ジョブにはデフォルトで再試行ポリシーが設定されています。構成を変更または無効にする方法については、「Using job retry policies」を参照してください。
