翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon EMR on EKS と AWS Lake Formation の連携方法
Lake Formation で Amazon EMR on EKS を使用すると、各 Spark ジョブにアクセス許可のレイヤーを適用して、Amazon EMR on EKS がジョブを実行するときに Lake Formation アクセス許可コントロールを適用できます。Amazon EMR on EKS は、Spark リソースプロファイル
以下は、Amazon EMR on EKS が Lake Formation セキュリティポリシーで保護されたデータにアクセスする方法の概要です。
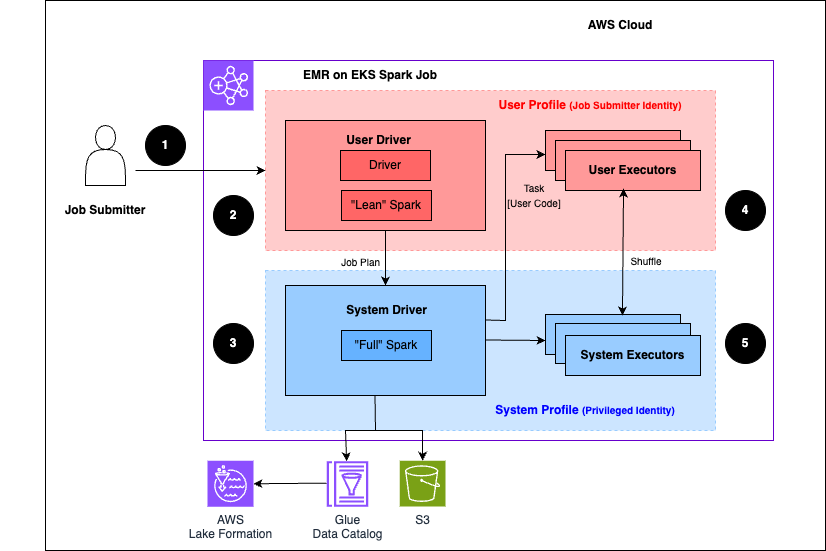
次の手順では、このプロセスについて説明します。
ユーザーは、 AWS Lake Formation 対応の Amazon EMR on EKS 仮想クラスターに Spark ジョブを送信します。
Amazon EMR on EKS サービスはユーザードライバーをセットアップし、ユーザープロファイルでジョブを実行します。ユーザードライバーは、タスクの起動、エグゼキュターのリクエスト、Amazon S3 または Glue データカタログへのアクセスができない Spark のリーンバージョンを実行します。ジョブプランのみを構築します。
Amazon EMR on EKS サービスは、システムドライバーと呼ばれる 2 番目のドライバーをセットアップし、システムプロファイル (特権 ID 付き) で実行します。Amazon EKS は、通信のために 2 つのドライバー間に暗号化された TLS チャネルを設定します。ユーザードライバーは、 チャネルを使用してジョブプランをシステムドライバーに送信します。システムドライバーは、ユーザーが送信したコードを実行しません。完全な Spark を実行し、データアクセスのために Amazon S3 およびデータカタログと通信します。エグゼキュターをリクエストし、ジョブプランを一連の実行ステージにコンパイルします。
Amazon EMR on EKS サービスは、エグゼキュターでステージを実行します。どのステージのユーザーコードも、ユーザープロファイルエグゼキュターでのみ実行されます。
Lake Formation で保護されたデータカタログテーブルからデータを読み取るステージ、またはセキュリティフィルターを適用するステージは、システムエグゼキュターに委任されます。
