Loading and analyzing data in Amazon FinSpace
Important
Amazon FinSpace Dataset Browser will be discontinued on November 29,
2024. Starting November 29, 2023, FinSpace will no longer accept the creation of new Dataset Browser
environments. Customers using Amazon FinSpace with Managed Kdb Insights
Before you proceed with this section, we recommend that you begin by reading Adding and managing data in Amazon FinSpace.
Use the following procedure to
-
Add sample data, create dataset, and data view using a CSV file. You can upload a CSV file of up to 2 GB directly from the FinSpace web application to add data.
-
Analyze the data view in Amazon FinSpace notebook.
Note
In order to perform these steps, you must be a member of a permission group with the necessary permissions - Create Datasets, Manage Clusters, Access Notebooks.
Add data, create dataset, and data view
To add data
Sign in to the FinSpace web application. For more information, see Signing in to the Amazon FinSpace web application.
-
On the left navigation bar of the home page, choose Add Data.
-
On the next page, drag and drop the Industrial production total index.csv
file on the page or choose Browse Files to select a new file. On the Add Data page, verify if the derived schema is correct.
If the derived schema is incorrect, choose Edit Derived Schema to edit it.
For example, in this sample file, the inferred data type for the column date is String, change it to Date.
After editing the schema, choose Save Schema.
-
Choose an appropriate permission group that should be associated to the dataset when it gets created. You can add additional permission groups after the dataset creation is complete.
-
Choose Confirm Schema & Upload File.
This action creates a dataset with name Industrial production total index and takes you to the Dataset details page.
Note
For small files of up to 100 megabytes, data view creation takes approximately 2 minutes. For larger files of around 1 gigabyte, expect data view creation to take approximately 3-4 minutes. Views with partitioning and sorting schemes may take longer.
Once the upload of the sample data file is complete, a process is kicked off to create a data view that can be analyzed in a notebook.
The data view card updates to show that the view is ready to be analyzed as it shows a new button with text Analyze in Notebook.
-
Choose Analyze in Notebook to access data in the data view in the integrated notebook environment.
Note
Starting up the FinSpace notebook environment for the first time may take 10-15 minutes. This is a one-time delay.
Analyze the data view in Amazon FinSpace notebook
Before you proceed with this section, we recommend that you begin by reading Working with Amazon FinSpace notebooks.
To analyze the data view in FinSpace notebook
Sign in to the FinSpace web application. For more information, see Signing in to the Amazon FinSpace web application.
Open data view in a notebook. For more information, see Opening the notebook environment.
-
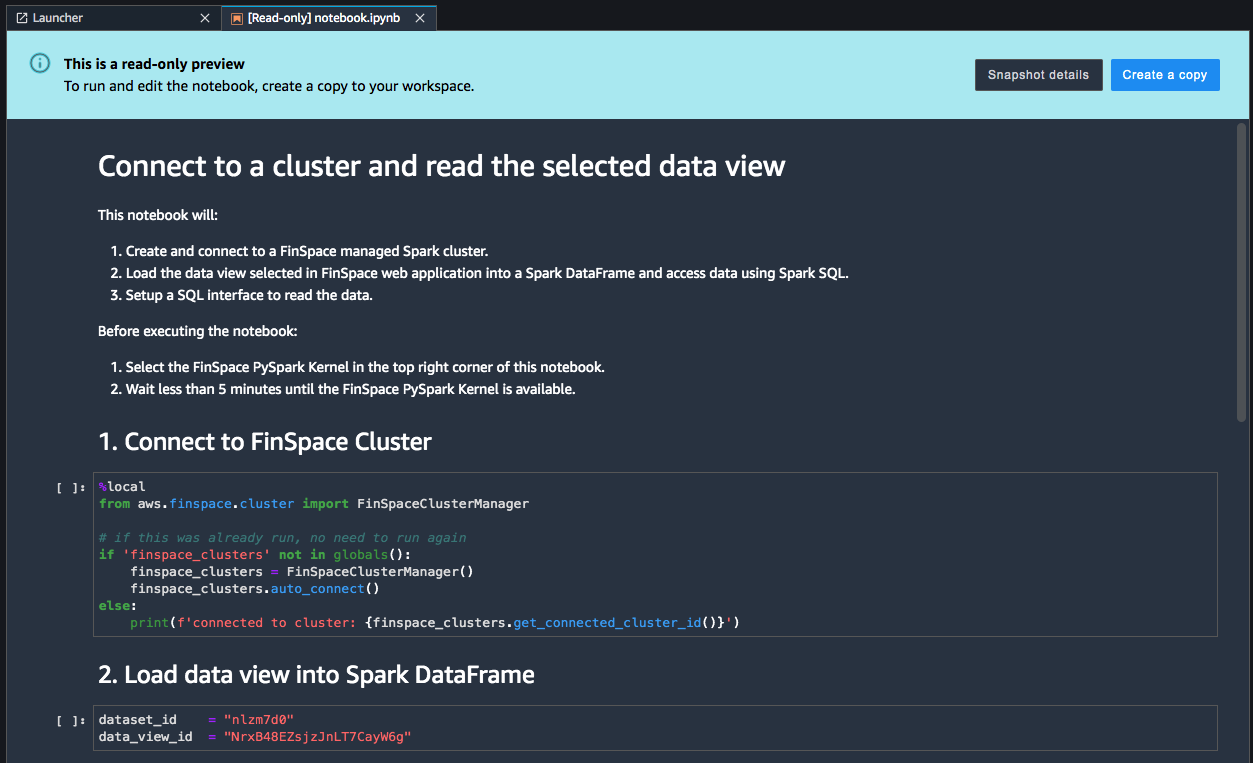
A default notebook in read-only preview is populated with the details of the view. Choose Create a copy. The notebook is created with name notebook.ipynb. The notebook contains code for:
-
Starting a Spark cluster.
-
Loading the data view in a Spark DataFrame.
-
Print the schema and contents of the DataFrame.
Note
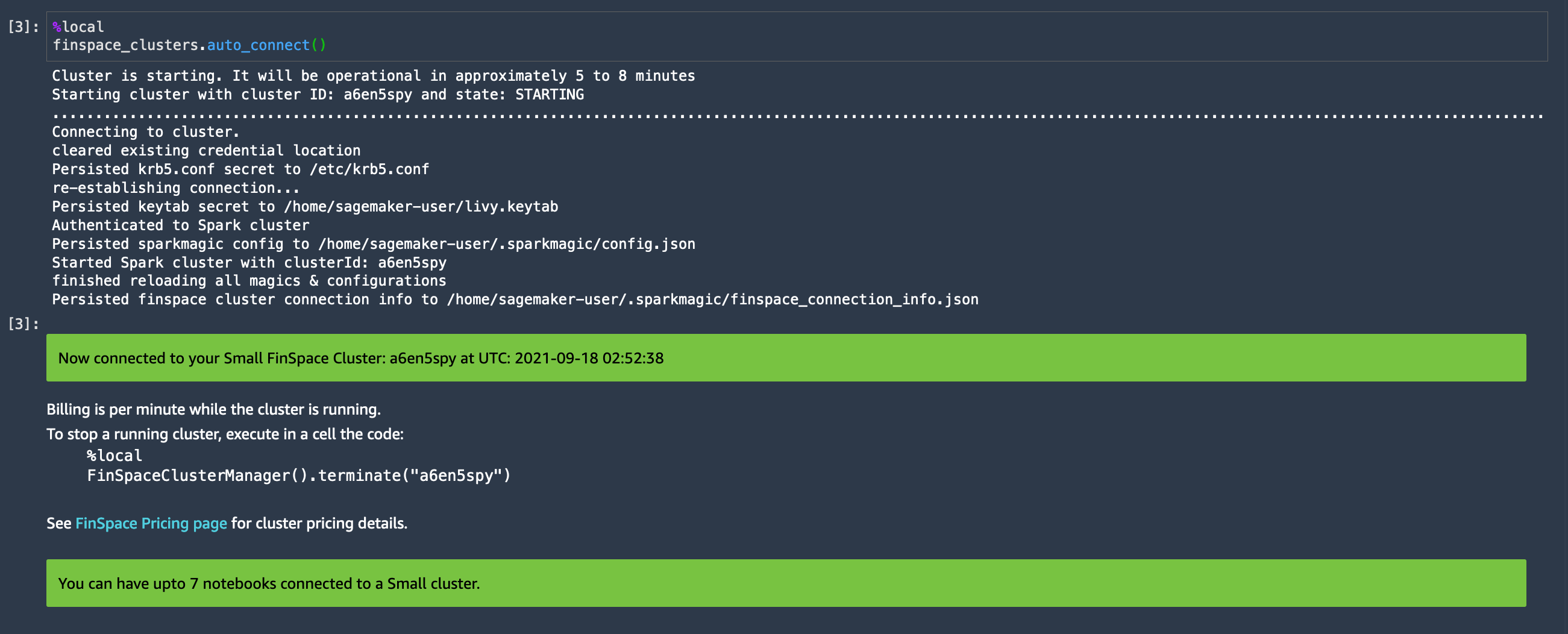
If the kernel is starting for the first time, expect a one-time delay of approximately 5-7 minutes. The FinSpace PySpark kernel and a notebook instance is automatically selected.
-
-
Start the Spark cluster by running the first cell of the notebook. Spark cluster creation takes about 5-8 minutes. If a Spark cluster is already created, then the notebook will detect the cluster and connect to it.
-
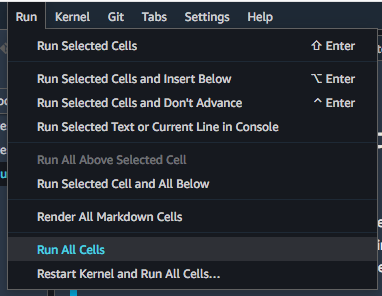
On the top menu bar, choose Run and then choose Run all the cells.
-
The executed code shows the contents of the data view.

