翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon FSx for Lustre のパフォーマンス
この章では、ファイルシステムのパフォーマンスを最大化するための重要なヒントや推奨事項など、Amazon FSx for Lustre のパフォーマンスに関するトピックを提供します。
トピック
概要
Amazon FSx for Lustre は、一般的な高性能ファイルシステムである Lustre をベースに構築されており、ファイルシステムのサイズに応じて直線的に増加するスケールアウトパフォーマンスを提供します。Lustre ファイルシステムは複数のファイルサーバーとディスクをまたいで水平にスケールします。このスケーリングにより、各クライアントは各ディスクに保存されているデータに直接アクセスして、従来のファイルシステムに存在するボトルネックの多くを取り除くことができます。Amazon FSx for Lustre は、Lustre のスケーラブルなアーキテクチャに基づいて構築され、多数のクライアントで高いレベルのパフォーマンスをサポートします。
FSx for Lustre のファイルシステム用のしくみ
各 FSx for Lustre ファイルシステムは、クライアントが通信するファイルサーバと、データを格納する各ファイルサーバに接続されたディスクのセットで設定されます。各ファイルサーバは、高速のインメモリキャッシュを使用して、最も頻繁にアクセスされるデータのパフォーマンスを向上させます。ストレージクラスに応じて、ファイルサーバーをオプションの SSD 読み取りキャッシュでプロビジョニングできます。クライアントがメモリ内キャッシュまたは SSD キャッシュに格納されているデータにアクセスする場合、ファイルサーバーはディスクから読み取る必要がないため、レイテンシーが減少し、ドライブ可能なスループットの合計量が増加します。次の図表は、書き込み操作、ディスクから実行される読み取り操作、およびインメモリまたは SSD キャッシュから実行される読み取り操作のパスを示しています。
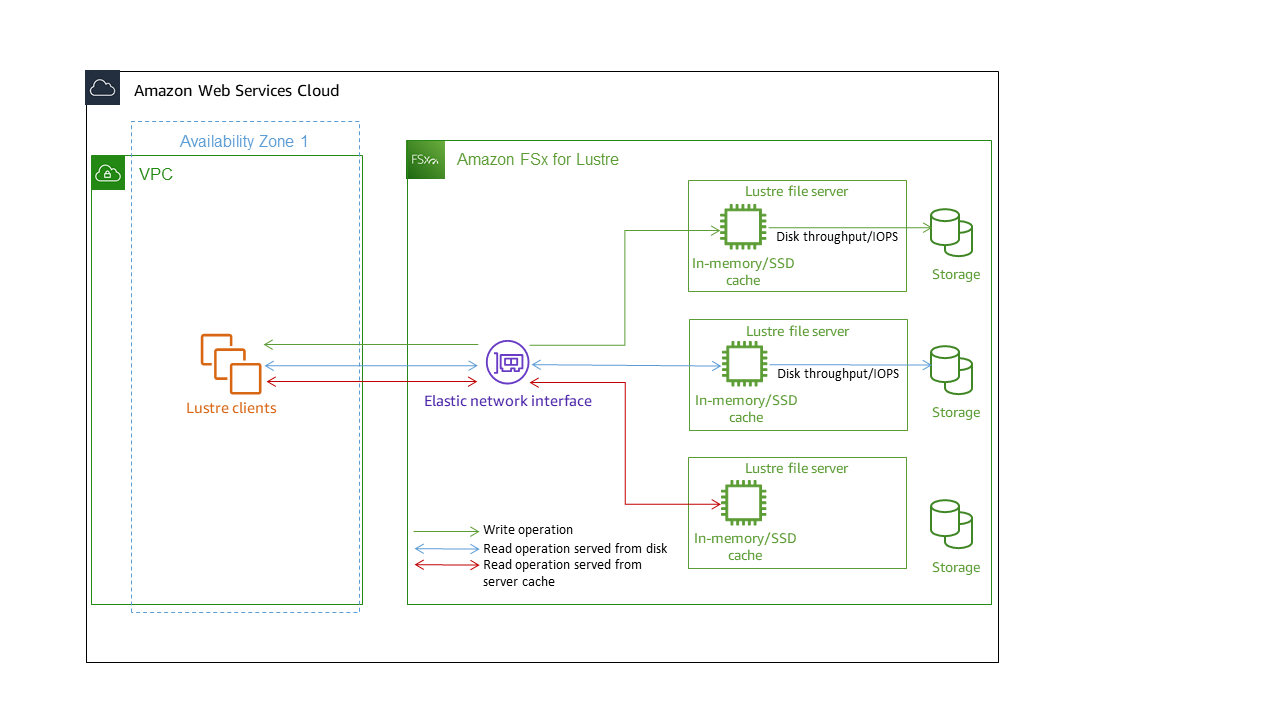
ファイルサーバーのインメモリまたは SSD キャッシュに保存されているデータを読み取る場合、ファイルシステムのパフォーマンスはネットワークスループットによって決まります。ファイルシステムにデータを書き込むとき、またはインメモリキャッシュに保存されていないデータを読み取る場合、ファイルシステムのパフォーマンスは、ネットワークスループットとディスクスループットの低い方によって決まります。
SSD および HDD ストレージクラスのネットワークスループット、ディスクスループット、IOPS 特性の詳細については、SSD および HDD ストレージクラスのパフォーマンス特性「」および「」を参照してくださいIntelligent-Tiering ストレージクラスのパフォーマンス特性。
ファイルシステムのメタデータパフォーマンス
ファイルシステムメタデータ IO オペレーション (IOPS) は、1 秒あたりに作成、一覧表示、読み取り、削除できるファイルとディレクトリの数を決定します。
永続的な 2 ファイルシステムでは、ストレージ容量から独立してメタデータ IOPS をプロビジョニングし、ファイルシステムで IOPS クライアントインスタンスが駆動しているメタデータの数とタイプをより詳細に可視化できます。SSD ファイルシステムでは、プロビジョニングしたストレージ容量に基づいてメタデータ IOPS が自動的にプロビジョニングされます。自動モードは Intelligent-Tiering ファイルシステムではサポートされていません。
FSx for Lustre Persistent 2 ファイルシステムでは、プロビジョニングするメタデータ IOPS の数とメタデータオペレーションのタイプによって、ファイルシステムがサポートできるメタデータオペレーションのレートが決まります。プロビジョニングするメタデータ IOPS のレベルによって、ファイルシステムのメタデータディスクにプロビジョニングされる IOPS の数が決まります。
| 操作タイプ | プロビジョニングされたメタデータ IOPS ごとに 1 秒あたりに駆動できるオペレーション |
|---|---|
|
ファイルの作成、開く、閉じる |
2 |
|
ファイルの削除 |
1 |
|
ディレクトリの作成、名前の変更 |
0.1 |
|
ディレクトリの削除 |
0.2 |
SSD ファイルシステムの場合、自動モードを使用してメタデータ IOPS をプロビジョニングすることを選択できます。自動モードでは、Amazon FSx は、次の表に従ってファイルシステムのストレージ容量に基づいてメタデータ IOPS を自動的にプロビジョニングします。
| ファイルシステムのストレージ容量 | 自動モードでのメタデータ IOPS を含む |
|---|---|
|
1200 GiB |
1500 |
|
2400 GiB |
3000 |
|
4800~9600 GiB |
6000 |
|
12000~45600 GiB |
12000 |
|
48,000 GiB 以上 |
24000 GiB あたり 12000 IOPS |
ユーザープロビジョニングモードでは、オプションでプロビジョニングするメタデータ IOPS の数を指定できます。有効な値は次のとおりです。
SSD ファイルシステムの場合、有効な値は
1500、、30006000、12000、および12000最大 の倍数です192000。Intelligent-Tiering ファイルシステムの場合、有効な値は
6000と です12000。
メタデータ IOPS を設定する方法については、「」を参照してくださいメタデータパフォーマンスの管理。ファイルシステムのデフォルトのメタデータ IOPS 数を超えてプロビジョニングされたメタデータ IOPS に対して料金が発生することに注意してください。
個々のクライアントインスタンスへのスループット
スループット容量が 10 GBps を超えるファイルシステムを作成する場合は、Elastic Fabric Adapter (EFA) を有効にして、クライアントインスタンスあたりのスループットを最適化することをお勧めします。クライアントインスタンスあたりのスループットをさらに最適化するために、EFA 対応ファイルシステムは、EFA 対応 NVIDIA GPU ベースのクライアントインスタンス用の GPUDirect Storage と ENA Express 対応クライアントインスタンス用の ENA Express もサポートしています。
単一のクライアントインスタンスに駆動できるスループットは、選択したファイルシステムタイプとクライアントインスタンスのネットワークインターフェイスによって異なります。
| ファイルシステムのタイプ | クライアントインスタンスのネットワークインターフェイス | クライアントあたりの最大スループット、Gbps |
|---|---|---|
|
EFA 非対応 |
いずれか |
100 Gbps* |
|
EFA 対応 |
ENA |
100 Gbps* |
|
EFA 対応 |
ENA Express |
100 Gbps |
|
EFA 対応 |
EFA |
700 Gbps |
|
EFA 対応 |
GDS を使用した EFA |
1200 Gbps |
注記
* 個々のクライアントインスタンスと個々の FSx for Lustre オブジェクトストレージサーバー間のトラフィックは 5 Gbps に制限されています。FSx for Lustre ファイルシステムを支えるオブジェクトストレージサーバーの数ファイルシステムの IP アドレスについては、「」を参照してください。
ファイルシステムストレージレイアウト
Lustre のすべてのファイルデータは、オブジェクトストレージターゲット (OST) と呼ばれるストレージボリュームに格納されます。すべてのファイルメタデータ (ファイル名、タイムスタンプ、アクセス許可などを含む) は、メタデータターゲット (MDT) と呼ばれるストレージボリュームに保存されます。Amazon FSx for Lustre ファイルシステムは、1 つ以上の MDT と複数の OST で設定されます。Amazon FSx for Lustre は、ストレージ容量とスループットと IOPS 負荷のバランスをとるために、ファイルシステムを設定する OST にファイルデータを分散します。
ファイルシステムを設定する MDT および OST のストレージ使用状況を表示するには、ファイルシステムがマウントされているクライアントから次のコマンドを実行します。
lfs df -hmount/path
このコマンドの出力は以下のようになります。
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
ファイルシステム内のデータのストライピング
ファイルストライピングにより、ファイルシステムのスループットパフォーマンスを最適化できます。Amazon FSx for Lustre は、データがすべてのストレージサーバーから確実に提供されるように、OST 間で自動的にファイルを分散します。複数の OST にまたがるファイルのストライピング方法を設定することで、同じ概念をファイルレベルで適用できます。
ストライピングとは、ファイルを複数のチャンクに分割して、異なる OST に格納できることを意味します。ファイルが複数の OST にストライプされると、ファイルへの読み取りまたは書き込みリクエストがそれらの OST にまたがって分散され、アプリケーションがそれを介して処理できる総スループットまたは IOPS が向上します。
Amazon FSx for Lustre ファイルシステムのデフォルトのレイアウトを次に示します。
2020 年 12 月 18 日より前に作成されたファイルシステムでは、デフォルトのレイアウトでストライプカウントが 1 に指定されています。つまり、異なるレイアウトを指定しない限り、標準の Linux ツールを使用して Amazon FSx for Lustre で作成された各ファイルは 1 つのディスクに格納されます。
2020 年 12 月 18 日以降に作成されたファイルシステムのデフォルトレイアウトは、プログレッシブファイルレイアウトであり、サイズが 1 GiB 未満のファイルは 1 つのストライプに保存され、大きいファイルにはストライプカウント 5 が割り当てられます。
2023 年 8 月 25 日以降に作成されたファイルシステムのデフォルトレイアウトは、プログレッシブファイルのレイアウト で説明されている 4 コンポーネントのプログレッシブファイルレイアウトです。
すべてのファイルシステムでは、作成日に関係なく、Amazon S3 からインポートされたファイルはデフォルトのレイアウトを使用せずに、ファイルシステムの
ImportedFileChunkSizeパラメータにあるレイアウトを使用します。ImportedFileChunkSizeより大きい S3 インポートされたファイルは、(FileSize / ImportedFileChunksize) + 1のストライプカウントで複数の OST に格納されます。ImportedFileChunkSizeのデフォルト値は 1 GiB です。
lfs getstripe コマンドを使用してファイルまたはディレクトリのレイアウト設定を表示できます。
lfs getstripepath/to/filename
このコマンドは、ファイルのストライプカウント、ストライプサイズ、およびストライプオフセットを報告します。ストライプカウントは、ファイルがストライプされている OST の数です。ストライプサイズは、OST に保存されている連続データの量です。ストライプオフセットは、ファイルがストライプされる最初の OST のインデックスです。
ストライピング設定の変更
ファイルのレイアウトパラメータは、ファイルが最初に作成されたときに設定されます。lfs setstripe コマンドを使用すると、指定したレイアウトで新しい空のファイルを作成します。
lfs setstripefilename--stripe-countnumber_of_OSTs
lfs setstripe コマンドは、新しいファイルのレイアウトにのみ影響します。これを使用して、ファイルを作成する前にファイルのレイアウトを指定します。ディレクトリのレイアウトを定義することもできます。ディレクトリに設定されると、そのレイアウトはそのディレクトリに追加されたすべての新しいファイルに適用されますが、既存のファイルには適用されません。作成した新しいサブディレクトリも新しいレイアウトを継承し、そのサブディレクトリ内に作成した新しいファイルまたはディレクトリに適用されます。
既存のファイルのレイアウトを変更するには、lfs migrate コマンドを使用します。このコマンドは、必要に応じてファイルをコピーし、コマンドで指定したレイアウトに従ってコンテンツを配信します。例えば、ファイルに追加されたファイルやサイズが増加しても、ストライプカウントは変更されないため、ファイルのレイアウトを変更するにはそれらを移行する必要があります。または、lfs setstripe コマンドを使用して、レイアウトを指定し、元のコンテンツを新しいファイルにコピーし、新しいファイルの名前を変更して元のファイルと置き換えます。
デフォルトのレイアウト設定がワークロードに最適ではない場合があります。例えば、数十個の OST と多数のマルチギガバイトファイルがあるファイルシステムでは、デフォルトのストライプカウント値である 5 OST を超えるファイルをストライピングすることで、パフォーマンスが向上します。ストライプカウントの少ない大きなファイルを作成すると、I/O パフォーマンスのボトルネックが発生し、OST がいっぱいになる可能性もあります。この場合、ファイルのストライプカウントが多いディレクトリを作成できます。
大きなファイル (特にサイズが 1 ギガバイトを超えるファイル) のストライプレイアウトを設定することは、次の理由で重要です。
大きなファイルの読み取りと書き込み時に、複数の OST とその関連サーバーが IOPS、ネットワーク帯域幅、および CPU リソースを提供できるようにすることで、スループットが向上します。
OST の小さなサブセットが全体的なワークロードパフォーマンスを制限するホットスポットになる可能性を低減します。
1 つの大きなファイルが OST を埋め尽くし、ディスクフルエラーを引き起こす可能性を防ぎます。
すべてのユースケースに単一の最適なレイアウト設定はありません。ファイルレイアウトに関する詳細なガイダンスについては、「Lustre.org ドキュメント」の「ファイルレイアウト (ストライピング) と空き領域の管理
ストライプのレイアウトは、大きなファイル、特にファイルのサイズが数百メガバイト以上のユースケースで最も重要です。このため、新しいファイルシステムのデフォルトのレイアウトでは、サイズが 1 GiB を超えるファイルに対してストライプカウント 5 が割り当てられます。
ストライプカウントは、大きなファイルをサポートするシステム用に調整する必要があるレイアウトパラメータです。ストライプカウントは、ストライプファイルのチャンクを保持する OST ボリュームの数を指定します。例えば、ストライプ数が 2、ストライプサイズが 1 MiB の場合、Lustre はファイルの代替の 1 MiB チャンクを 2 つの OST のそれぞれに書き込みます。
有効なストライプカウントは、実際の OST ボリュームの数と指定したストライプカウント値のうち小さい方です。特別なストライプカウント値の
-1を使用できます。これは、ストライプをすべての OST ボリュームに配置する必要があることを示します。特定の操作では、ファイルが小さすぎてすべての OST ボリュームの容量を消費できない場合でも、Lustre はレイアウト内のすべての OST へのネットワークラウンドトリップを必要とするため、小さなファイルに対して大きなストライプカウントを設定することは最適ではありません。
プログレッシブファイルレイアウト (PFL) を設定して、ファイルのレイアウトをサイズに応じて変更することができます。PFL 設定では、各ファイルに対して明示的に設定しなくても、大小のファイルを組み合わせたファイルシステムの管理を簡素化できます。詳細については、「プログレッシブファイルのレイアウト」を参照してください。
ストライプサイズは、デフォルトで 1 MiB です。ストライプオフセットを設定すると、特殊な状況では便利ですが、通常は指定しないままにしておき、デフォルトを使用するのが最善です。
プログレッシブファイルのレイアウト
ディレクトリのプログレッシブファイルレイアウト (PFL) 設定を指定して、小さなファイルと大きなファイルに対して異なるストライプ設定を指定してから、それを入力できます。例えば、データが新しいファイルシステムに書き込まれる前に、最上位ディレクトリに PFL を設定できます。
PFL 設定を指定するには、lfs setstripe コマンドで -E オプションを使用して、以下のコマンドのように、異なるサイズのファイルのレイアウトコンポーネントを指定します。
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
このコマンドは、4 つのレイアウトコンポーネントを設定します。
最初のコンポーネント (
-E 100M -c 1) は、最大 100 MiB のファイルのストライプカウント値 1 を示します。2 番目のコンポーネント (
-E 10G -c 8) は、サイズが 10 GiB までのファイルのストライプカウントを 8 であることを示します。3 番目のコンポーネント (
-E 100G -c 16) は、サイズが 100 GiB までのファイルのストライプカウントを 16 であることを示します。4 番目の要素 (
-E -1 -c 32) は、100 GiB を超えるファイルのストライプカウントが 32 であることを示しています。
重要
PFL レイアウトで作成されたファイルにデータを追加すると、そのレイアウトコンポーネントがすべて入力されます。例えば、上記の 4 コンポーネントコマンドで、1 MiB のファイルを作成し、その末尾にデータを追加すると、ファイルのレイアウトが展開され、ストライプカウントが -1 になります。これは、システム内のすべての OST を指します。これは、データがすべての OST に書き込まれるという意味ではありませんが、ファイル長の読み取りなどのオペレーションは、すべての OST に並行してリクエストを送信し、ファイルシステムに大きなネットワークロードを追加します。
したがって、その後にデータを追加できる小またはミディアムの長さのファイルのストライプカウントを制限するように注意してください。通常、ログファイルは新しいレコードを追加することで増加するため、Amazon FSx for Lustre では、親ディレクトリで指定されたデフォルトのストライプ設定に関係なく、追加モードで作成されたファイルに、デフォルトのストライプカウント 1 が割り当てられます。
2023 年 8 月 25 日以降に作成された Amazon FSx for Lustre ファイルシステムのデフォルトの PFL 設定は、次のコマンドを実行して設定します。
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
中~大規模ファイルへの同時アクセスが多いワークロードを持つお客様は、前述の 4 つのコンポーネントのレイアウト例で示したように、ファイルサイズが小さい場合はストライプカウントが多いレイアウトを使用し、ファイルサイズが最大の場合はすべての OST にまたがるストライピングのレイアウトを使用することでメリットが得られます。
パフォーマンスと使用状況のモニタリング
Amazon FSx for Lustre は 1 分ごとに、各ディスク (MDT および OST) の使用状況メトリクスを Amazon CloudWatch に発行します。
ファイルシステムの総使用状況の詳細を表示するには、各メトリクスの Sum 統計を調べます。例えば、DataReadBytes 統計は、ファイルシステム内のすべての OST で見られる総読み取りスループットを報告します。同様に、FreeDataStorageCapacity 統計は、ファイルシステム内のファイルデータに使用可能なストレージ容量の合計を報告します。
ファイルシステムのパフォーマンスのモニタリングの詳細については、「Amazon FSx for Lustre ファイルシステムのモニタリング」を参照してください。
