クローラーを使用したデータカタログへの入力
AWS Glue クローラー を使用して、AWS Glue Data Catalog にデータベースとテーブルを入力できます。これは、AWS Glue ユーザーが最もよく使用する基本的な方法です。クローラーは 1 回の実行で複数のデータストアをクロールできます。完了すると、クローラーはデータカタログで 1 つ以上のテーブルを作成または更新します。AWS Glue で定義した抽出、変換、ロード (ETL) ジョブは、これらのデータカタログテーブルをソースおよびターゲットとして使用します。ETL ジョブは、ソースおよびターゲットのデータカタログテーブルで指定されているデータストアに対して読み取りと書き込みを行います。
ワークフロー
次のワークフロー図は、AWS Glue クローラーがデータストアや他の要素とやり取りしてデータカタログに入力する方法を示しています。
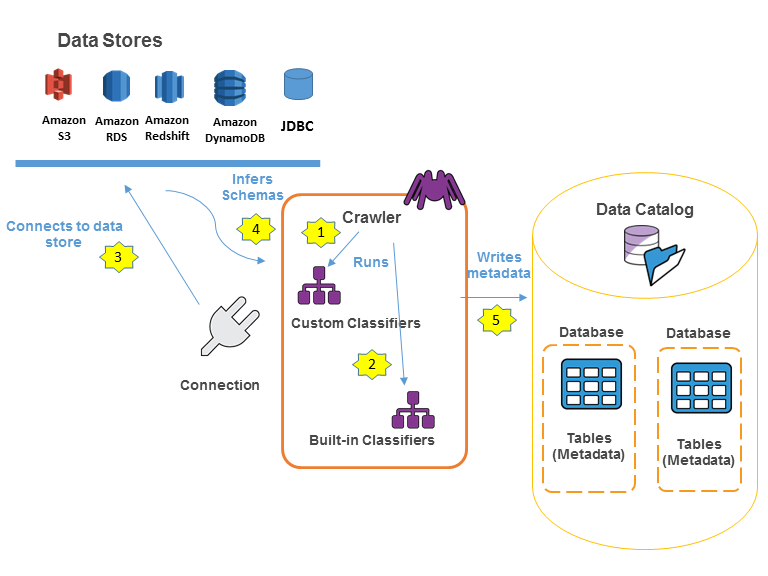
クローラーが AWS Glue Data Catalog に入力する一般的なワークフローを以下に示します。
-
クローラーが選択した任意のカスタム分類子を実行し、データの形式とスキーマを推論します。カスタム分類子のコードを提供すると、指定した順序で実行されます。
データの構造を正常に認識した最初のカスタム分類子がスキーマを作成するために使用されます。リスト内の下位のカスタム分類子はスキップされます。
-
カスタム分類子と一致するデータのスキーマがない場合は、組み込み分類子がデータのスキーマを認識します。組み込み分類子の例に、JSON を認識する分類子があります。
-
クローラーがデータストアに接続します。一部のデータストアでは、クローラーがアクセスするために接続プロパティを必要とします。
-
データの推測されたスキーマが作成されます。
-
クローラーはデータカタログにメタデータを書き込みます。テーブル定義にはデータストア内のデータに関するメタデータが含まれています。テーブルは、Data Catalog でテーブルのコンテナとなるデータベースに書き込まれます。テーブルの属性には分類が含まれます。これは、テーブルのスキーマを推測した分類子により作成されるラベルです。
トピック
クローラーの仕組み
クローラーを実行すると、クローラーは以下のアクションを使用してデータストアを調査します。
-
ローデータの形式、スキーマ、および関連プロパティを確認するためにデータを分類する – カスタム分類子を作成して分類の結果を設定できます。
-
データをテーブルまたはパーティションにグループ化する – データはクローラーのヒューリスティックに基づいてグループ化されます。
-
メタデータをデータカタログに書き込む – クローラーでテーブルやパーティションを追加、更新、削除する方法を設定できます。
クローラーを定義する場合、データの形式を評価してスキーマを推測する分類子を 1 つ以上選択します。クローラーを実行すると、リストで最初にデータストアの認識に成功した分類子を使用してテーブルのスキーマが作成されます。組み込み分類子を使用するか、独自に定義することができます。カスタム分類子は、クローラーを定義する前に別のオペレーションで定義します。AWS Glue には、JSON、CSV、Apache Avro などの形式の共通ファイルからスキーマを推論するための組み込み分類子が用意されています。AWS Glue の組み込み分類子の最新のリストについては、「組み込み分類子」を参照してください。
クローラーで作成するメタデータテーブルは、クローラーの定義時にデータベースに含まれます。クローラーがデータベースを指定しない場合、テーブルはデフォルトのデータベースに配置されます。さらに、各テーブルには、最初にデータストアの認識に成功した分類子により入力された分類子の列があります。
クロールするファイルが圧縮されている場合、クローラーはダウンロードして処理する必要があります。クローラーを実行すると、ファイルを調査して形式と圧縮タイプを判定し、これらのプロパティをデータカタログに書き込みます。一部のファイル形式 (Apache Parquet など) では、ファイルの書き込み時にファイルの一部を圧縮できます。これらのファイルでは、圧縮されたデータはファイルの内部コンポーネントであり、AWS Glue はテーブルをデータカタログ内に書き込むときに compressionType プロパティに値を入力しません。一方、ファイル全体を圧縮アルゴリズム (gzip など) で圧縮する場合は、テーブルをデータカタログ内に書き込むときに compressionType プロパティが事前設定されます。
クローラーは、作成するテーブルの名前を生成します。AWS Glue Data Catalogに保存されるテーブルの名前は、以下のルールに従います。
-
英数字とアンダースコア (
_) のみを使用できます。 -
カスタムプレフィックスは 64 文字より長くすることはできません。
-
名前の長さは最大 128 文字までです。クローラーは、生成した名前が制限内に収まるように切り捨てます。
-
重複するテーブル名が発生した場合、クローラーは名前にハッシュ文字列のサフィックスを追加します。
クローラーが複数回実行される場合 (おそらくスケジュールに基づいて)、データストア内の新規または変更されたファイルやテーブルが検索されます。クローラーの出力には、前回の実行以降に検索された、新しいテーブルとパーティションが含まれています。
クローラーは、どのようにパーティションを作成するタイミングを判断していますか?
AWS Glue クローラーは、Amazon S3 データをスキャンしてバケット内に複数のフォルダを検出すると、フォルダ構造のテーブルのルート、およびどのフォルダがテーブルのパーティションであるかを確認します。テーブルの名前は Amazon S3 プレフィックスまたはフォルダ名に基づいています。クロールするフォルダレベルを指すインクルードパスを指定します。フォルダレベルの大半のスキーマが類似している場合、クローラーはテーブルを別個に作成せずに、テーブルのパーティションを作成します。クローラーで別個のテーブルを作成するには、クローラーを定義するときに各テーブルのルートフォルダを別個のデータストアとして追加します。
例えば、次の Amazon S3 フォルダ構造を想定します。
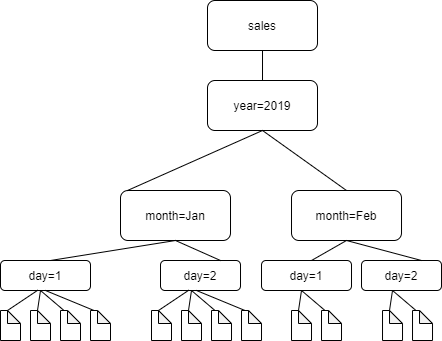
4 つの最下位レベルのフォルダへのパスは次のとおりです。
S3://sales/year=2019/month=Jan/day=1 S3://sales/year=2019/month=Jan/day=2 S3://sales/year=2019/month=Feb/day=1 S3://sales/year=2019/month=Feb/day=2
クローラーターゲットが Sales に設定されており、day=n フォルダ内のすべてのファイルが同じ形式 (暗号化されていない JSON など) で、同じか非常によく似たスキーマを持っているとします。クローラーは、パーティションキー year、month、および day で、4 つのパーティションを持つ単一のテーブルを作成します。
次の例では、次の Amazon S3 構造を想定します。
s3://bucket01/folder1/table1/partition1/file.txt s3://bucket01/folder1/table1/partition2/file.txt s3://bucket01/folder1/table1/partition3/file.txt s3://bucket01/folder1/table2/partition4/file.txt s3://bucket01/folder1/table2/partition5/file.txt
table1 と table2 のファイルのスキーマが類似しており、クローラーにインクルードパス s3://bucket01/folder1/ で定義されているデータストアが 1 つの場合、クローラーは 2 つのパーティションキー列を持つ 1 つのテーブルを作成します。最初のパーティションキー列には table1 および table2 が含まれ、2 番目のパーティションキー列には、table1 パーティションに対して partition1 から partition3 まで、および table2 パーティションに対して partition4 と partition5 が含まれます。2 つの個別のテーブルを作成するには、2 つのデータストアを持つクローラーを定義します。この例では、最初のインクルードパスを s3://bucket01/folder1/table1/ として定義し、2 番目を s3://bucket01/folder1/table2 として定義します。
注記
Amazon Athenaの場合、各テーブルは Amazon S3 プレフィックス (すべてのオブジェクトを含む) に対応します。オブジェクト別にスキーマが異なる場合、Athena では同じプレフィックス内の異なるオブジェクトを別個のテーブルとして認識しません。これは、クローラーで同じ Amazon S3 プレフィックスから複数のテーブルを作成する場合に発生することがあります。そのため、Athena のクエリで結果が何も返されない場合があります。Athena でテーブルを適切に認識してクエリを実行するには、Amazon S3 フォルダ構造内の異なるテーブルスキーマごとに別個のインクルードパスを持つクローラーを作成します。詳細については、「Athena で AWS Glue を使用するときのベストプラクティス」およびこちらの「AWS ナレッジセンターの記事
