ジョブエディタの機能
ジョブエディタでは、ジョブの作成と編集のための次の機能が提供されています。
-
ジョブの視覚的な図。各ジョブタスクのノード (データを読み取るデータソースノード、データを修正する変換ノード、データを書き込むデータターゲットノード) が示されます。
ジョブ図では、各ノードのプロパティを表示および設定できます。また、各ノードのスキーマとサンプルデータを表示することもできます。これらの機能により、ジョブを実行することなく、ジョブでデータが正しい方法で変更および変換されていることを確認できます。
-
[Script viewing and editing] (スクリプトの表示と編集) タブ。ジョブ用に生成されたコードを変更できます。
-
[Job details] (ジョブの詳細) タブ。さまざまな設定を行い、AWS Glue ETL ジョブの実行環境をカスタマイズできます。
[Runs] (実行) タブ。現在実行中のジョブや以前実行したジョブの表示、ジョブの実行のステータスの表示、ジョブの実行用のログへのアクセスを行えます。
-
[データ品質] タブでは、データ品質ルールをジョブに適用できます。
-
[Schedules] (スケジュール) タブ。ジョブの開始時間を設定したり、ジョブの実行を定期的に設定できます。
-
バージョン管理タブ。ジョブで使用する Git サービスを設定できます。
ビジュアルジョブエディタでスキーマのプレビューを使用する
ジョブの作成中または編集中に、[Output schema] (出力スキーマ) タブをクリックして、データのスキーマを表示できます。
スキーマを表示するには、ジョブエディタにデータソースへのアクセス許可が必要です。エディタの [Job details] (ジョブの詳細) タブ、またはノードの [Output schema] (出力スキーマ) タブで IAM ロールを指定できます。データソースへのアクセスに必要なすべてのアクセス許可が IAM ロールにある場合は、ノードの [Output schema] (出力スキーマ) タブのスキーマを表示できます。
ビジュアルジョブエディタでデータのプレビューを使用する
データのプレビューを使用することで、ジョブを繰り返し実行することなく、データのサンプルを使用してジョブを作成およびテストできます。データプレビューを使用すると、次を実行できます。
-
IAM ロールをテストして、データソースまたはデータターゲットにアクセスできることを確認します。
-
変換により、意図した方法でデータが変更されていることを確認します。例えば、フィルター変換を使用する場合、フィルターでデータの適切なサブセットが選択されていることを確認できます。
-
データを確認する。データセットに複数のタイプの値を持つ列が含まれている場合、データのプレビューには、これらの列のタプルのリストが表示されます。各タプルには、データ型とその値が含まれています。
注記
データプレビューセッションおよびカスタム SQL またはカスタムコードノードを使用する場合、データプレビューセッションはデータセット全体に SQL またはコードブロックをそのまま実行します。
ジョブの作成中または編集中に、[Data preview] タブをクリックして、データのサンプルを表示できます。ジョブでロールが既に設定されている場合、またはアカウントでデフォルトの IAM ロールが設定されている場合、新しいデータプレビューセッションが自動的に開始されます。ロールが事前に設定されていない場合は、ロールを選択してセッションを開始できます。
![スクリーンショットは、ノードの [Data preview] (データのプレビュー) タブを示しています。](images/data-preview-stop-start.png)
注記
データプレビューセッション用に選択したロールは、ジョブにも使用されます。
情報アイコンをクリックすると、セッションのステータスと進行状況、およびセッションの詳細を確認できます。
セッションの準備が完了すると、AWS Glue Studio は選択したノードのためにデータをロードします。進捗に伴う [完了率 (%)] を表示できます。
![スクリーンショットは、開始されたノードの [データのプレビュー] タブを示しています。](images/data-preview-progress.png)
ビジュアルジョブを作成する際に、[出力スキーマ] タブで [セッションからスキーマを推測] を切り替えると、AWS Glue Studio は選択したノードのスキーマを自動的に更新します。
![スクリーンショットは、開始されたノードの [データのプレビュー] タブを示しています。](images/data-preview-output-schema.png)
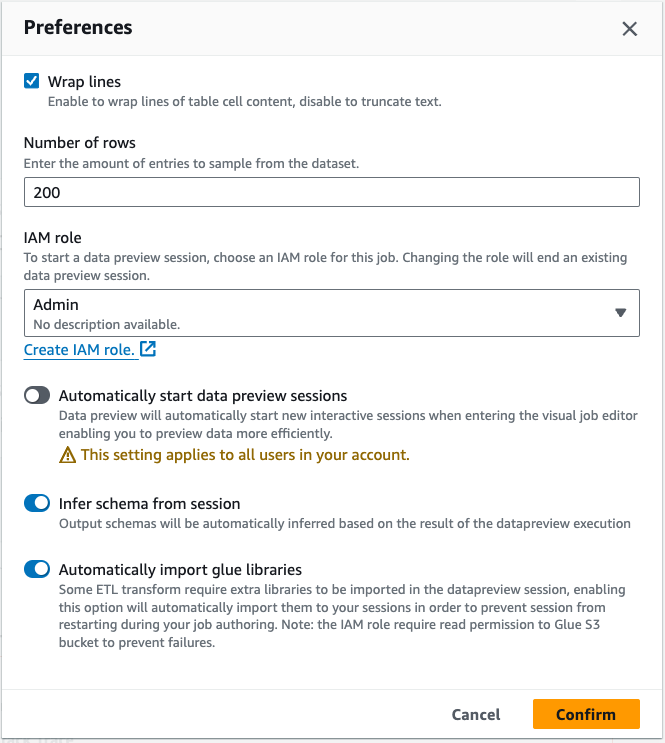
データプレビューの設定を行うには:
設定アイコン (歯車の記号) を選択して、データのプレビューの設定を行えます。これらの設定は、ジョブ図のすべてのノードに適用されます。次のようにできます。
-
テキストを 1 行から次の行に折り返す場合に選択します。デフォルトでは、このオプションは有効になっています
-
行数を変更する (デフォルトは 200)
-
IAM ロールを選択するか、または、必要であれば新しいロールを作成
-
ジョブの作成時に新しいセッションを自動的に開始することを選択します。これにより、ジョブの作成時に新しいインタラクティブセッションがプロビジョニングされます。この設定はアカウントレベルで適用されます。一度設定すると、ジョブの編集時にアカウント内のすべてのユーザーに適用されます。
-
スキーマを自動的に推論する場合に選択します。出力スキーマは、選択したノードのために自動的に推論されます
-
AWS Glue ライブラリを自動的にインポートする場合に選択します。これは、セッションの再起動を必要とする新しい変換を追加する際に、データプレビューが新しいセッションを再起動するのを防ぐため、有益です。
追加機能には次の機能が含まれます。
-
[Previewing x of y fields] (X/Y フィールドのプレビュー) ボタンをクリックして、プレビューする列 (フィールド) を選択できます。デフォルトの設定を使用してデータをプレビューすると、ジョブエディタにはデータセットの最初の 5 列が表示されます。これを、[show all] (すべて表示) または [none] (なし) (非推奨) に変更できます。
-
データのプレビューウィンドウは、水平方向と垂直方向の両方にスクロールします。
-
最大化ボタンを使用して、[Data preview] タブをジョブグラフ画面全体に展開し、データおよびデータ構造をより詳しく表示できます。同様に、最小化ボタンを使用して [Data preview] タブを最小化します。ハンドルペインをつかんで上にドラッグして [Data preview] タブを展開することもできます。

-
[セッションの終了] を使用してデータプレビューを停止します。セッションを停止すると、新しい IAM ロールを選択し、新しいセッションを自動的に開始したり、スキーマを推測したり、AWS Glue ライブラリをインポートしたりするための追加設定 (オン/オフなど) を設定して、セッションを再開できます。
データのプレビューを使用する際の制限事項
データのプレビューを使用する際、次の制約または制限事項が発生する場合があります。
-
初めて [Data preview] (データのプレビュー) タブを選択する際、IAM ロールを選択する必要があります。このロールには、そのデータおよびデータのプレビューの作成に必要なその他のリソースへのアクセス許可が必要です。
-
IAM ロールを指定した後、データを表示できるようになるまでには時間がかかります。データが 1 GB 未満のデータセットの場合、最大で 1 分かかることがあります。大きなデータセットがある場合は、パーティションを使用してロード時間を改善する必要があります。Amazon S3 からデータを直接ロードすると、パフォーマンスが最も良くなります。
-
非常に大きなデータセットがあり、データのプレビュー用のデータのクエリに 15 分以上かかる場合、リクエストはタイムアウトします。データプレビューには 30 分の IDLE タイムアウトがあります。これを軽減するために、データセットのサイズを小さくして、データプレビューを使用できます。
-
デフォルトでは、[Data preview] タブには最初の 50 列が表示されます。列にデータの値がない場合は、表示するデータはありませんというメッセージが表示されます。サンプリングされる行数を増やすか、別の列を選択してデータの値を表示できます。
-
現在、データのプレビューは、ストリーミングデータソースまたはカスタムコネクタを使用するデータソースではサポートされていません。
-
1 つのノードでのエラーは、ジョブ全体に影響します。いずれかのノードでデータのプレビューのエラーがある場合、エラーは修正されるまですべてのノードに表示されます。
-
ジョブのデータソースを変更する場合、そのデータソースの子ノードは、新しいスキーマに合わせて更新する必要があります。例えば、列を変更する ApplyMapping ノードがあり、その列が代替データソースに存在しない場合、ApplyMapping 変換ノードを更新する必要があります。
-
SQL クエリ変換ノードの [Data preview] (データのプレビュー) タブを表示する際に SQL クエリで誤ったフィールド名が使用されている場合、[Data preview] (データのプレビュー)タブにエラーが表示されます。
スクリプトコードの生成
ビジュアルエディタを使用してジョブを作成する場合、ETL コードが自動的に生成されます。AWS Glue Studio は機能的で完全なジョブスクリプトを作成し、Amazon S3 の場所に保存します。
AWS Glue Studio によって生成されるコードには 2 つの形式があります。: オリジナルバージョン、またはクラシックバージョン、およびより新しいストリームラインされたバージョンです。デフォルトでは、新しいコードジェネレーターがジョブスクリプトの作成に使用されます。ジョブスクリプトは、[Generate classic script]トグルボタンを選択することにより、[Script]タブ上のクラシックコードジェネレーターを使用して生成できます。
生成されたコードの新しいバージョンでは、いくつかの違いを含みます。:
-
大きなコメントブロックは、もうスクリプトに追加されなくなりました。
-
コード内の出力のデータ構造は、ビジュアルエディタで指定したノード名を使用します。クラススクリプトでは、出力のデータ構造は単に
DataSource0,DataSource1,Transform0,Transform1,DataSink0,DataSink1などと名前が付けられます。 -
長いコマンドは複数の行に分割されるため、ページ全体をスクロールしてコマンド全体を表示する必要がなくなります。
AWS Glue Studio 中の新機能には新しいバージョンのコード生成が必要で、クラシックコードスクリプトでは動作しません。これらのジョブを実行しようとすると、これらのジョブを更新するように求められます。
