チュートリアル: AWS Glue で機械学習変換を作成する
このチュートリアルでは、AWS Glue を使用して機械学習 (ML) 変換を作成および管理するためのアクションについてガイドします。このチュートリアルを使用するには、 AWS Glue コンソールを使用してクローラとジョブを追加し、スクリプトを編集する方法をよく理解している必要があります。Amazon Simple Storage Service (Amazon S3) で、ファイルを検索してダウンロードする方法についてもよく理解している必要があります。
次の例では、一致するレコードを見つけるための FindMatches 変換を作成します。また、一致する/一致しないレコードを識別する方法を、この変換にトレーニングして AWS Glue ジョブで使用します。AWS Glue ジョブは、match_id という別の列を追加して新しい Amazon S3 ファイルを作成します。
このチュートリアルで使用されているソースデータは、dblp_acm_records.csv という名前のファイルです。このファイルは、元の DBLP ACM データセットdblp_acm_records.csv ファイルは、BOM (バイトオーダーマーク) なしの UTF-8 形式でエンコードされたカンマ区切り値 (CSV) ファイルです。
2 番目のファイル dblp_acm_labels.csv はサンプルのラベリングファイルです。このファイルには、チュートリアルの一環として変換をトレーニングするために使用する、一致する/一致しないレコードの両方が含まれています。
トピック
ステップ 1: ソースデータをクロールする
まず、ソースである Amazon S3 CSV ファイルをクロールして、対応するメタデータテーブルを Data Catalog に作成します。
重要
CSV ファイルのみのテーブルを作成するようクローラに指示するために、CSV ソースデータを他のファイルとは異なる Amazon S3 フォルダに保存します。
AWS Management Consoleにサインインし、AWS Glue コンソール (https://console.aws.amazon.com/glue/
) を開きます。 -
ナビゲーションペインで、[クローラ]、[クローラの追加] の順に選択します。
-
ウィザードに従って
demo-crawl-dblp-acmというクローラを作成して実行し、出力をデータベースdemo-db-dblp-acmに保存します。ウィザードの実行時に、データベースdemo-db-dblp-acmがまだ存在していない場合は、これを作成します。現在の AWS リージョンでのサンプルデータへの Amazon S3 インクルードパスを選択します。例えば、us-east-1の場合、ソースファイルへの Amazon S3 インクルードパスはs3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csvです。完了すると、クローラによってテーブル
dblp_acm_records_csvが作成され、テーブルの列として、ID、タイトル、作成者、場所、年、およびソースが設定されます。
ステップ 2: 機械学習変換を追加する
次に、demo-crawl-dblp-acm というクローラで作成されたデータソーステーブルのスキーマに基づく機械学習変換を追加します。
-
AWS Glue コンソールにある [データ統合と ETL] のナビゲーションペインで、[データ分類ツール] > [レコードのマッチング] の順に選択し、[変換の追加] を選択します。ウィザードに従って、以下のプロパティを持つ
Find matches変換を作成します。-
[変換の名前] に、「
demo-xform-dblp-acm」と入力します。これは、ソースデータの一致を見つけるために使用する変換の名前です。 -
[IAM role] (IAM ロール) で、Amazon S3 ソースデータ、ラベリングファイル、および AWS Glue API オペレーションへのアクセス許可を持つ IAM ロールを選択します。詳細については、AWS Glue デベロッパーガイドの「Create an IAM Role for AWS Glue」を参照してください。
-
[Data source] (データソース) に、demo-db-dblp-acm というデータベースの dblp_acm_records_csv という名前のテーブルを選択します。
-
[Primary key (プライマリキー)] で、テーブルのプライマリキー列である [ID] を選択します。
-
ウィザードで、[完了] を選択し、[ML 変換] リストに戻ります。
ステップ 3: 機械学習変換をトレーニングする
次に、チュートリアルのサンプルのラベリングファイルを使用して、機械学習変換をトレーニングします。
機械学習変換は、そのステータスが [Ready for use (使用可能)] になるまで、ETL (抽出、変換、ロード) ジョブで使用できません。変換を使用可能にするには、一致するレコードと一致しないレコードのサンプルを提供し、レコードの一致/不一致を見分ける方法について変換をトレーニングする必要があります。変換をトレーニングするには、ラベルファイルを生成して、ラベルを追加し、ラベルファイルをアップロードします。このチュートリアルでは、dblp_acm_labels.csv というサンプルラベリングファイルを使用できます。ラベリングプロセスの詳細については、「ラベリング」を参照してください。
-
AWS Glue コンソールのナビゲーションペインで、[レコードのマッチング] を選択します。
-
demo-xform-dblp-acm変換を選択し、次に [アクション]、[Teach (トレーニング)] の順に選択します。ウィザードに従って、Find matches変換をトレーニングします。 変換のプロパティページで、[I have labels (ラベルがあります)] を選択します。現在の AWS リージョンでサンプルラベリングファイルへの Amazon S3 パスを選択します。例えば、
us-east-1の場合、指定したラベリングファイルを Amazon S3 パスs3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvからアップロードします。この際に、既存のラベルを上書きするオプションを使用します。ラベリングファイルは、AWS Glue コンソールと同じリージョンの Amazon S3 に配置する必要があります。ラベリングファイルをアップロードすると、データソースの処理方法について変換をトレーニングするために使用するラベルを追加または上書きするためのタスクが AWS Glue で開始されます。
ウィザードの最後のページで、[完了] を選択し、[ML 変換] リストに戻ります。
ステップ 4: 機械学習変換の品質を推定する
次に、機械学習変換の品質を推定できます。品質は、どれだけのラベル付けを実施したかに応じて異なります。品質の推定の詳細については、「品質の推定」を参照してください。
-
AWS Glue コンソールにある [データ統合と ETL] のナビゲーションペインで、[データ分類ツール] > [レコードのマッチング] の順に選択します。
-
demo-xform-dblp-acm変換を選択し、[Estimate quality (品質の推定)] タブをクリックします。このタブには、変換の現在の品質の推定 (使用可能な場合) が表示されます。 [Estimate quality (品質の推定)] を選択して、変換の品質を推定するためのタスクを開始します。品質の推定の精度はソースデータのラベル付けに基づきます。
[履歴] タブに移動します。このペインには、変換のタスク実行が一覧表示されます。これには、品質の推定タスクも含まれます。実行の詳細を参照するには、[ログ] を選択します。実行が完了したときの実行ステータスが [成功] になっていることを確認します。
ステップ 5: 機械学習変換でジョブを追加して実行する
このステップでは、機械学習変換を使用して AWS Glue にジョブを追加して実行します。変換 demo-xform-dblp-acm は、[Ready for use (使用可能)] である場合に、ETL ジョブで使用できます。
-
AWS Glue コンソールのナビゲーションペインで、[ジョブ] を選択します。
-
[Add job (ジョブの追加)] を選択し、ウィザードの手順に従い、生成されたスクリプトを使用して ETL Spark ジョブを作成します。変換のプロパティ値として以下を選択します。
-
[名前] で、このチュートリアルのサンプルジョブである demo-etl-dblp-acm を選択します。
-
[IAM role] (IAM ロール) に、Amazon S3 ソースデータ、ラベリングファイル、および AWS Glue API オペレーションへのアクセス許可を持つ IAM ロールを選択します。詳細については、AWS Glue デベロッパーガイドの「Create an IAM Role for AWS Glue」を参照してください。
-
[ETL 言語] で、[Scala] を選択します。これは ETL スクリプトのプログラミング言語です。
-
[スクリプトファイル名] で、[demo-etl-dblp-acm] を選択します。これは Scala スクリプトのファイル名です (ジョブ名と同じです)。
-
[データソース] で、[dblp_acm_records_csv] を選択します。選択したデータソースは、機械学習変換のデータソーススキーマと一致する必要があります。
-
[Transform type (変換タイプ)] で、[Find matching records (一致するレコードの検索)] を選択し、機械学習変換を使用してジョブを作成します。
-
[Remove duplicate records (重複するレコードの削除)] をオフにします。重複するレコードを削除しない理由は、書き込まれる出力レコードに別の
match_idフィールドが追加されるためです。 -
[変換] で、ジョブによって使用される機械学習変換である demo-xform-dblp-acm を選択します。
-
[データターゲットでテーブルを作成する] で、次のプロパティを使用してテーブルを作成することを選択します。
-
[Data store type] (データストアのタイプ) –
Amazon S3 -
[Format] (形式) –
CSV -
[Compression type] (圧縮タイプ) –
None -
[Target path] (ターゲットパス) – ジョブの出力が書き込まれる Amazon S3 パス (現在のコンソールの AWS リージョン)
-
-
-
[ジョブを保存してスクリプトを編集する] を選択して、スクリプトエディタページを表示します。
-
スクリプトを編集し、ターゲットパスへのジョブ出力を単一のパーティションファイルに書き込ませるためのステートメントを追加します。このステートメントは、
FindMatches変換を実行するステートメントの直後に追加します。このステートメントは次のようになります。val single_partition = findmatches1.repartition(1)出力を
.writeDynamicFrame(single_partion)として書き込むには、.writeDynamicFrame(findmatches1)ステートメントを変更する必要があります。 -
スクリプトを編集したら、[保存] を選択します。変更後のスクリプトは次のコードのようになりますが、使用環境向けにカスタマイズされます。
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } [ジョブの実行] を選択してジョブの実行を開始します。ジョブリストでジョブのステータスを確認します。ジョブが完了すると、[ML 変換] の [履歴] タブに、[ETL ジョブ] タイプの新しい [実行 ID] 行が追加されます。
[ジョブ]、[履歴] タブの順に移動します。このペインには、ジョブの実行が一覧表示されます。実行の詳細を参照するには、[ログ] を選択します。実行が完了したときの実行ステータスが [成功] になっていることを確認します。
ステップ 6: Amazon S3 の出力データを確認する
このステップでは、ジョブの追加時に選択した Amazon S3 バケットのジョブ実行の出力を確認します。出力ファイルをローカルマシンにダウンロードして、一致するレコードが識別されていることを確認します。
https://console.aws.amazon.com/s3/
で Amazon S3 コンソールを開きます。 ジョブ
demo-etl-dblp-acmのターゲット出力ファイルをダウンロードします。このファイルをスプレッドシートアプリケーションで開きます (ファイルを正常に開くには、必要に応じてファイル拡張子.csvを追加します)。次の図は、Microsoft Excel で開いた出力の抜粋を示しています。
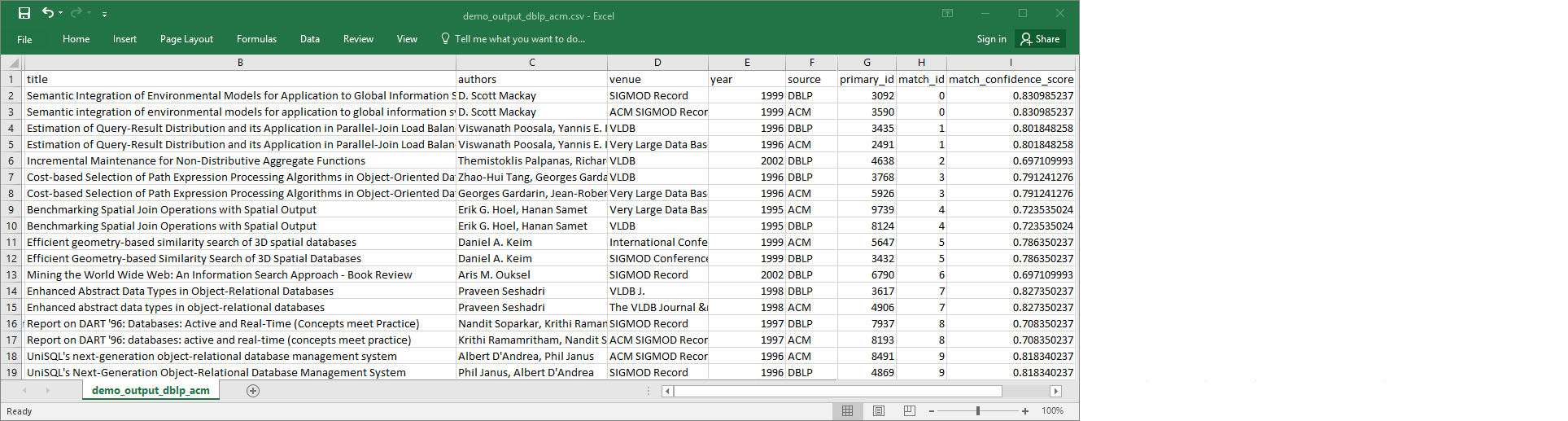
データソースおよびターゲットファイルの両方に 4,911 個のレコードがあります。ただし、
Find matches変換には、出力内の一致するレコードを識別するためにmatch_idという別の列が追加されています。同じmatch_idの行は、一致するレコードと見なされます。match_confidence_scoreは 0~1 の間の数値で、Find matchesによって検出された次の値で一致の品質を推定します。-
出力ファイルを
match_idで並べ替えると、どのレコードが一致しているか簡単にわかります。他の列の値と比較して、Find matches変換の結果が適切であるかどうかを判断します。適切でない場合は、さらにラベルを追加することで、引き続き変換をトレーニングします。ファイルをソートするために別のフィールド (
titleなど) を使用して、同じようなタイトルのレコードが同じmatch_idを持っているかどうかを確認することもできます。
