DPU の容量計画のモニタリング
AWS Glue でジョブメトリクスを使用すると、AWS Glue ジョブをスケールアウトするために使用できるデータ処理単位 (DPU) の数を予測できます。
注記
このページは AWS Glue バージョン 0.9 および 1.0 にのみ適用できます。AWS Glue 以降のバージョンには、容量計画時に追加の考慮事項を導入するコスト削減機能が含まれています。
プロファイルされたコード
次のスクリプトは、428 個の gzip で圧縮された JSON ファイルを含む Amazon Simple Storage Service (Amazon S3) パーティションを読み取ります。このスクリプトは、マッピングを適用してフィールド名を変更し、Apache Parquet 形式に変換して Amazon S3 に書き込みます。デフォルトに従って 10 個の DPU をプロビジョニングし、このジョブを実行します。
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [input_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [(map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet")
AWS Glue コンソールでプロファイルされたメトリクスを可視化する
ジョブの実行 1: このジョブの実行では、プロビジョニングが不足している DPU がクラスターにあるかどうかを調べる方法を示します。AWS Glue でのジョブ実行機能は、アクティブに実行されているエグゼキュターの合計数、完了したステージの数、必要なエグゼキュターの最大数を表示します。
必要なエグゼキュターの最大数は、実行中のタスクと保留中のタスクの合計数を加算し、エグゼキュターごとのタスクで除算することによって算出されます。この結果は、現在の負荷に対応するために必要なエグゼキュターの合計数の尺度となります。
一方、アクティブに実行されているエグゼキュターの数は、アクティブな Apache Spark タスクで実行されているエグゼキュターの数を測定します。ジョブが進行するにつれて、必要なエグゼキュターの最大数は変化し、保留中のタスクキューが減るため通常はジョブの終わりに向かって減少します。
次のグラフの横方向の赤色の線は、割り当てられたエグゼキュターの最大数を示しています。これは、ジョブに割り当てる DPU の数によって異なります。この場合、ジョブの実行に対して 10 個の DPU を割り当てます。1 つの DPU が管理用に予約されています。9 個の DPU はそれぞれ 2 つのエグゼキュターを実行し、1 つのエグゼキュターは Spark ドライバー用に予約されています。Spark ドライバーはプライマリアプリケーション内で実行されます。そのため、割り当てられるエグゼキュターの最大数は、2*9 - 1 = 17 です。

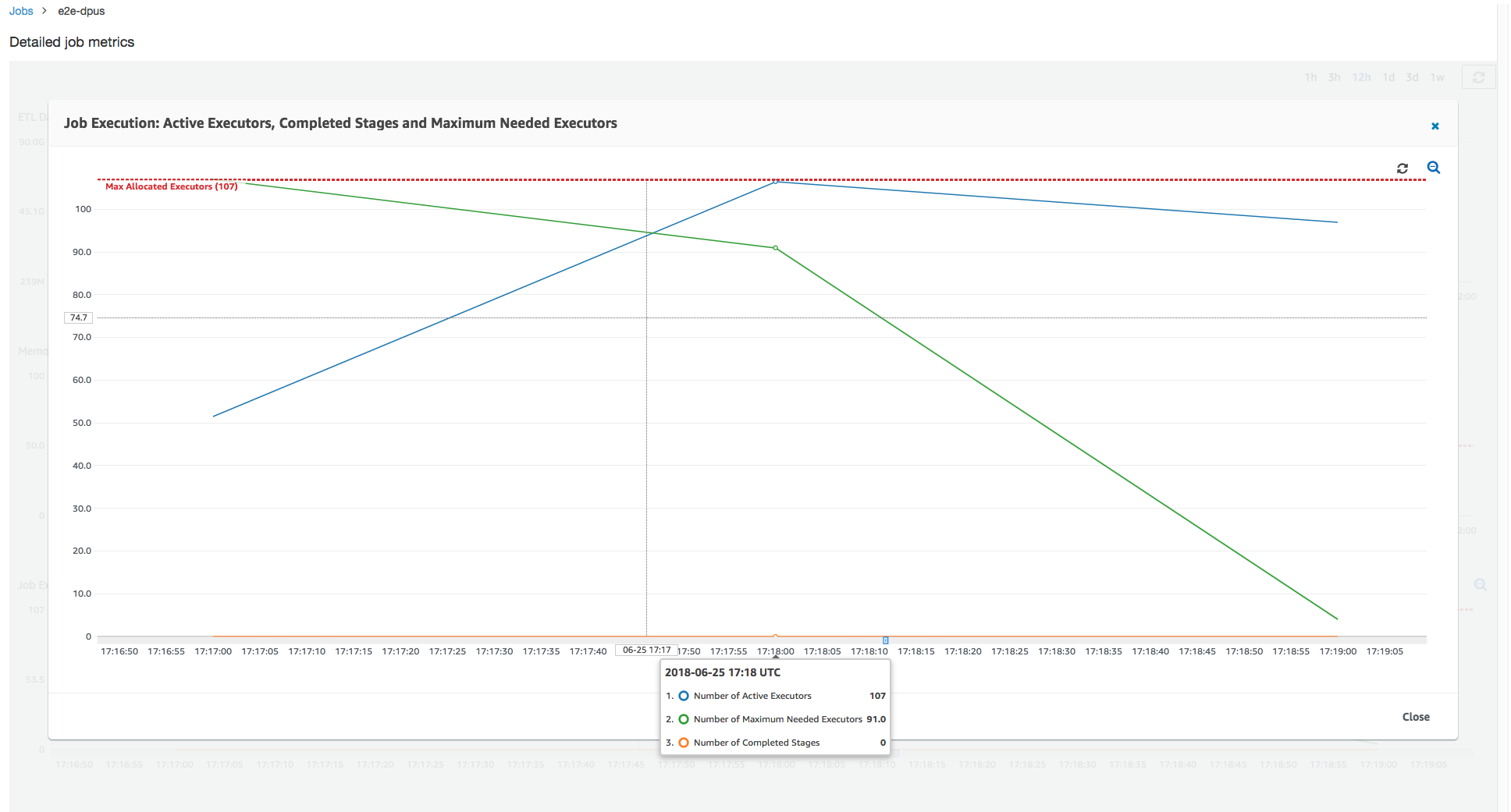
グラフが示すとおり、必要なエグゼキュターの最大数はジョブの開始時に 107 から始まりますが、アクティブなエグゼキュターの数は 17 のままです。これは、10 個の DPU を持つ割り当てられるエグゼキュターの最大数と同じです。必要なエグゼキュターの最大数と割り当てられるエグゼキュターの最大数の比率 (Spark ドライバーでは両方に 1 を加算) から、プロビジョニングが不足している係数が 108/18 = 6 倍であるとわかります。6 (プロビジョニング率未満) *9 (現在の DPU 容量 -1) +1 DPU = 55 個の DPU をプロビジョニングしてジョブをスケールアウトし、最大限の並列処理で実行することで処理時間を短縮することができます。
AWS Glue コンソールは、詳細なジョブメトリクスを、元の割り当てられるエグゼキュターの最大数を表す静的な線として表示します。コンソールは、メトリクスのジョブ定義からから割り当てられるエグゼキュターの最大数を計算します。対照的に、詳細なジョブ実行メトリクスについては、コンソールはジョブ実行設定から割り当てられるエグゼキュターの最大数、特にジョブ実行に割り当てられた DPU を計算します。個々のジョブ実行のメトリクスを表示するには、ジョブ実行を選択して、[実行メトリクスの表示] を選択します。
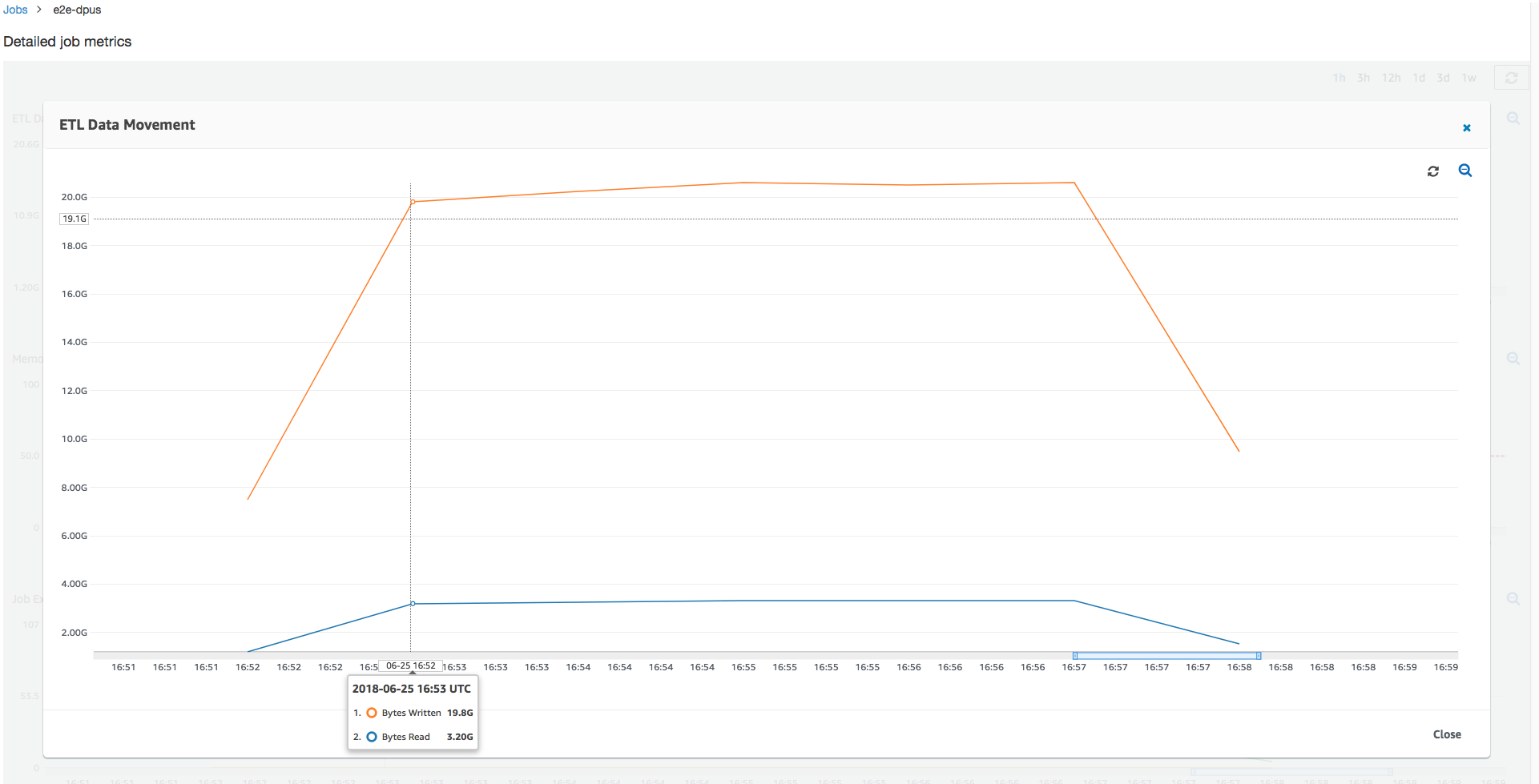
読み取りおよび書き込みされた Amazon S3 バイトを見ると、ジョブが Amazon S3 からのデータをストリーミングして並列に書き出すことに 6 分すべてを消費していることがわかります。割り当てられた DPU 上のすべてのコアは、Amazon S3 に対して読み取りと書き込みを行います。必要なエグゼキュターの最大数 107 は、入力 Amazon S3 パス内のファイル数 428 とも整合しています。各エグゼキュターは、4 つの Spark タスクを起動し、4 つの入力ファイルを処理します (gzip で圧縮された JSON)。
最適な DPU 容量を決定する
前のジョブの実行の結果に基づいて、割り当てられる DPU の合計数を 55 に増やし、ジョブがどのように実行されるかを確認できます。ジョブは 3 分未満で完了します。以前に必要な時間の半分です。この場合、実行時間の短いジョブであるため、ジョブのスケールアウトは直線的ではありません。存続期間の長いタスクまたは多数のタスクを持つジョブ (必要なエグゼキュターの最大数が大きい) は、直線的に近い DPU スケールアウトのパフォーマンス向上から恩恵を受けます。
上の図に示すように、アクティブなエグゼキュターの合計数が最大割り当て数 107 個のエグゼキュターに到達します。同様に、必要なエグゼキュターの最大数が割り当てられるエグゼキュターの最大数を上回ることはありません。必要なエグゼキュターの最大数は、アクティブに実行されているタスクと保留中のタスクの数から計算されるため、アクティブなエグゼキュターの数よりも小さい可能性があります。これは、短期間部分的または完全にアイドル状態になり、まだ停止されていないエグゼキュターが存在する可能性があるためです。
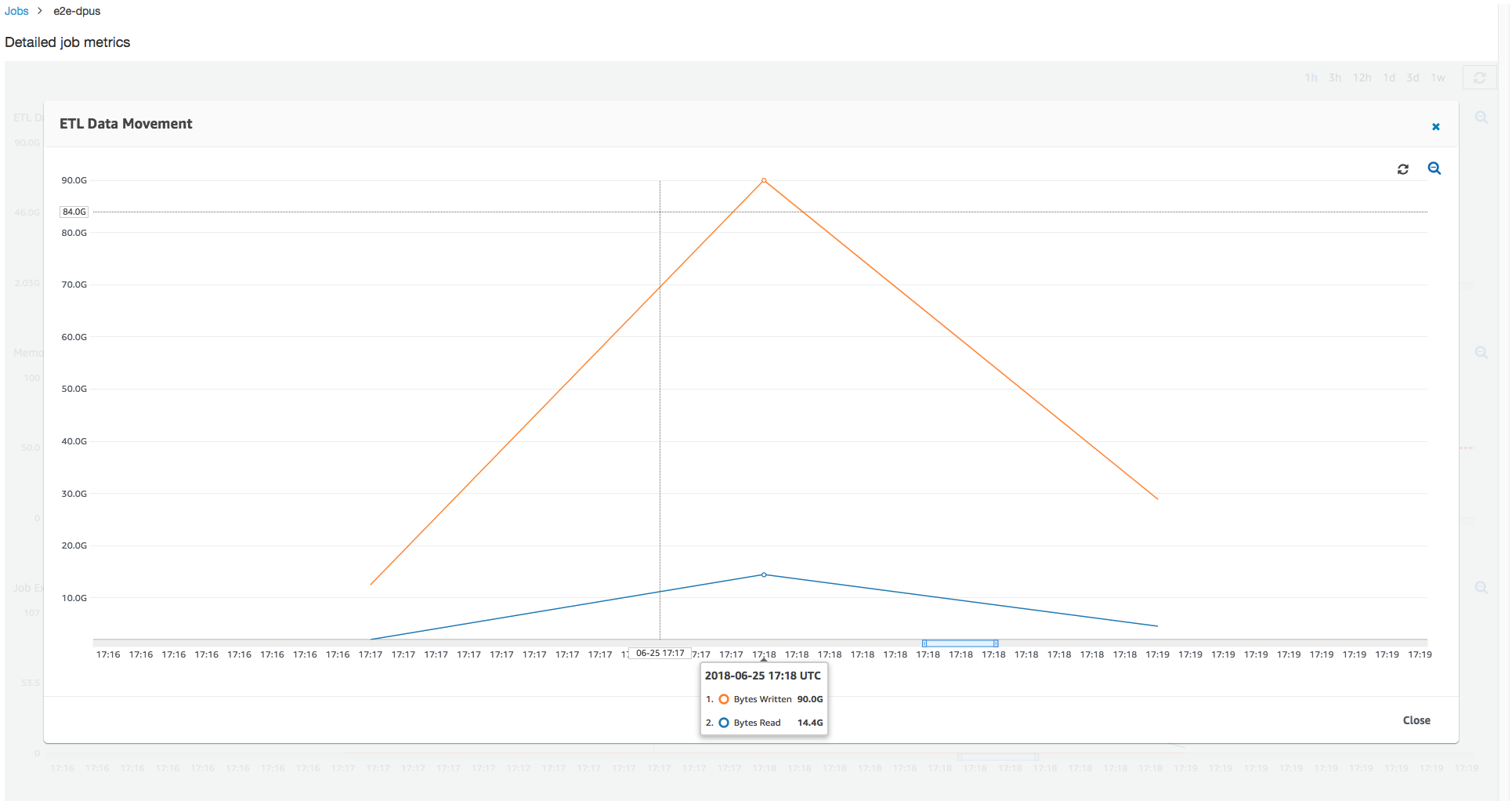
このジョブの実行では、Amazon S3 から並列で読み取りと書き込みをするために 6 倍のエグゼキュターが使用されます。その結果、このジョブの実行では、読み取りと書き込みの両方に使用される Amazon S3 帯域幅が多くなり、早く完了します。
過度にプロビジョニングされた DPU を識別する
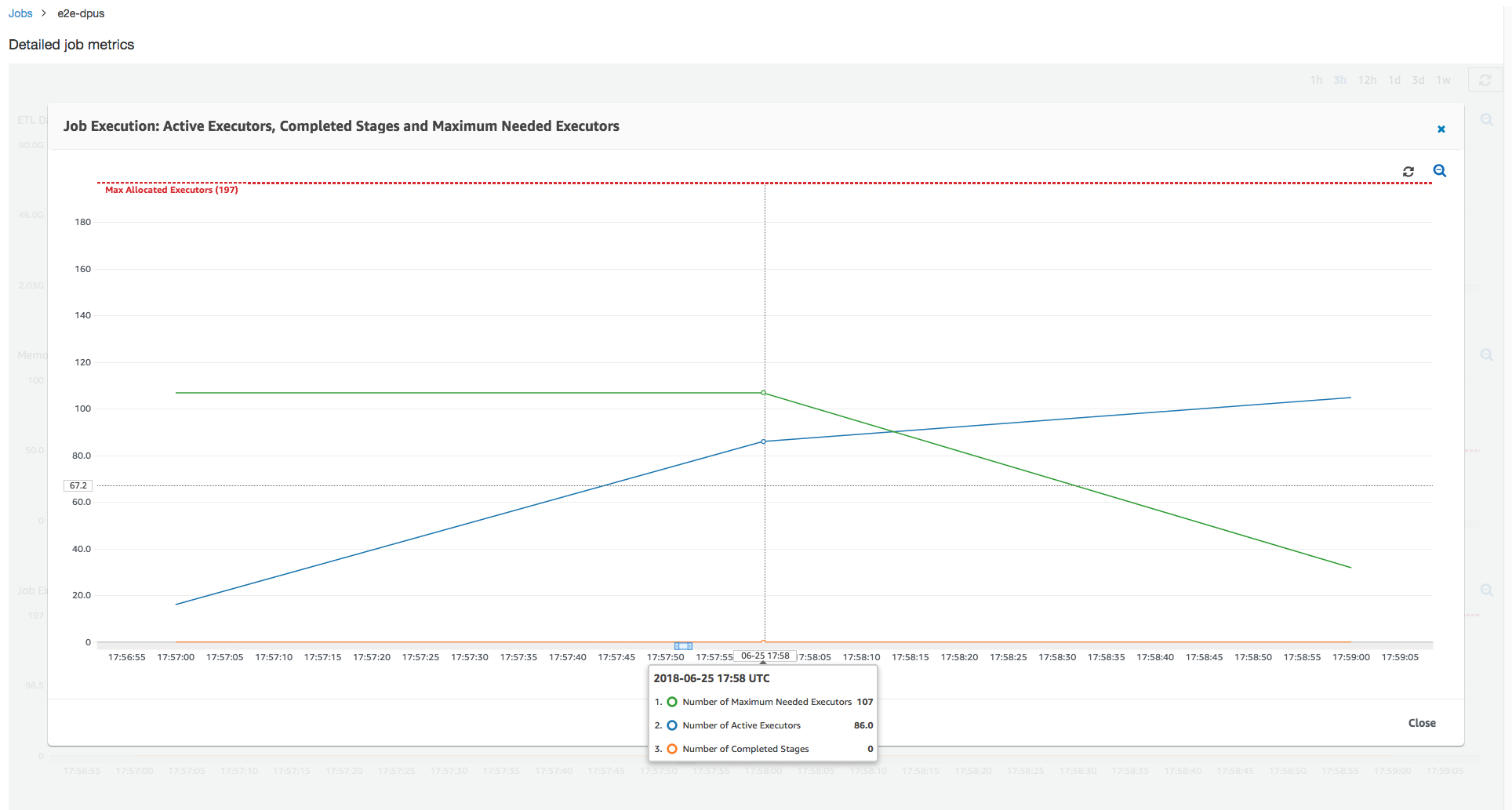
次に、100 個の DPU (99 * 2 = 198 個のエグゼキュター) でジョブをスケールアウトするとこれ以上スケールアウトしなくてよくなるかどうかを調べることができます。次のグラフが示すように、ジョブが完了するまでまだ 3 分かかります。同様に、ジョブは 107 個を超えてスケールアウトしないため (55 DPU 構成)、残りの 91 個のエグゼキュターは過剰にプロビジョニングされてまったく使用されません。必要なエグゼキュターの最大数からわかるように、これは DPU の数を増やしても必ずパフォーマンスが向上するわけではないことを示しています。
時間の差を比較する
次の表に示す 3 つのジョブが実行は、10 個の DPU、55 個の DPU、100 個の DPU のジョブの実行時間をまとめています。最初のジョブの実行をモニタリングすることで確立した推定値を使用して、ジョブの実行時間を向上させることができる DPU 容量を調べることができます。
| ジョブ ID | DPU の数 | 実行時間 |
|---|---|---|
| jr_c894524c8ef5048a4d9..。 | 10 | 6 分。 |
| jr_1a466cf2575e7ffe6856..。 | 55 | 3 分。 |
| jr_34fa1ed4c6aa9ff0a814..。 | 100 | 3 分。 |
