OOM 例外とジョブの異常のデバッグ
AWS Glue でメモリ不足 (OOM) 例外とジョブの異常をデバッグできます。以下のセクションでは、Apache Spark ドライバーや Spark エグゼキュターのメモリ不足例外をデバッグするためのシナリオについて説明します。
ドライバー OOM 例外のデバッグ
このシナリオでは、Spark ジョブで多数の小さいファイルが Amazon Simple Storage Service (Amazon S3) から読み込まれます。ファイルが Apache Parquet 形式に変換された後、Amazon S3 に書き込まれます。Spark ドライバーのメモリが不足しています。入力 Amazon S3 データの複数の Amazon S3 パーティションに 100 万を超えるファイルがあります。
プロファイルされたコードは次のとおりです。
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path") data.write.format("parquet").save(output_path)
AWS Glue コンソールでプロファイルされたメトリクスを可視化する
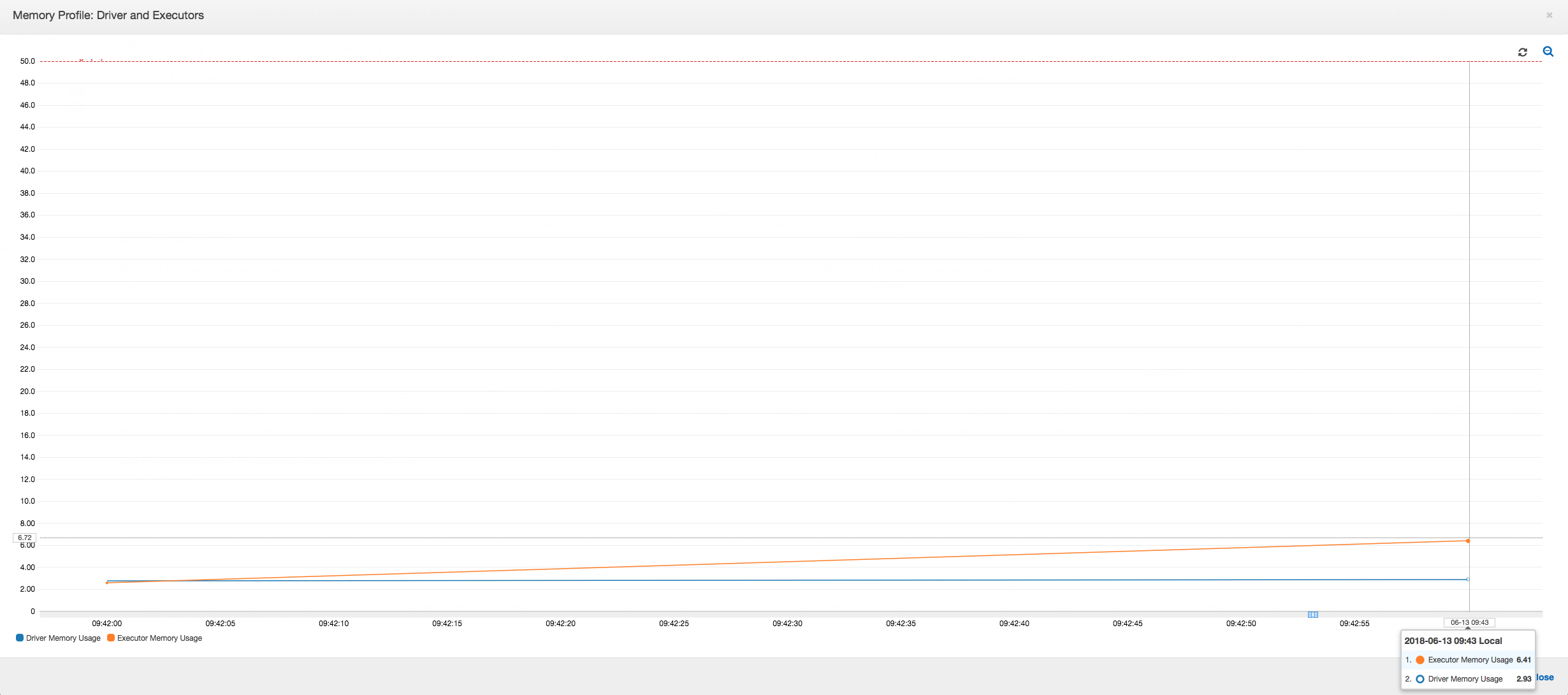
以下のグラフでは、ドライバーとエグゼキュターのメモリ使用率がパーセントで示されています。この使用率は、直近の 1 分間に報告された値を平均した 1 つのデータポイントとしてプロットされます。ジョブのメモリプロファイルでは、ドライバーメモリが安全しきい値である使用率の 50% をすぐに超えることがわかります。一方、すべてのエグゼキュターにおける平均メモリ使用率は、まだ 4% 未満です。これは、この Spark ジョブにおけるドライバー実行に異常があることを明確に示しています。
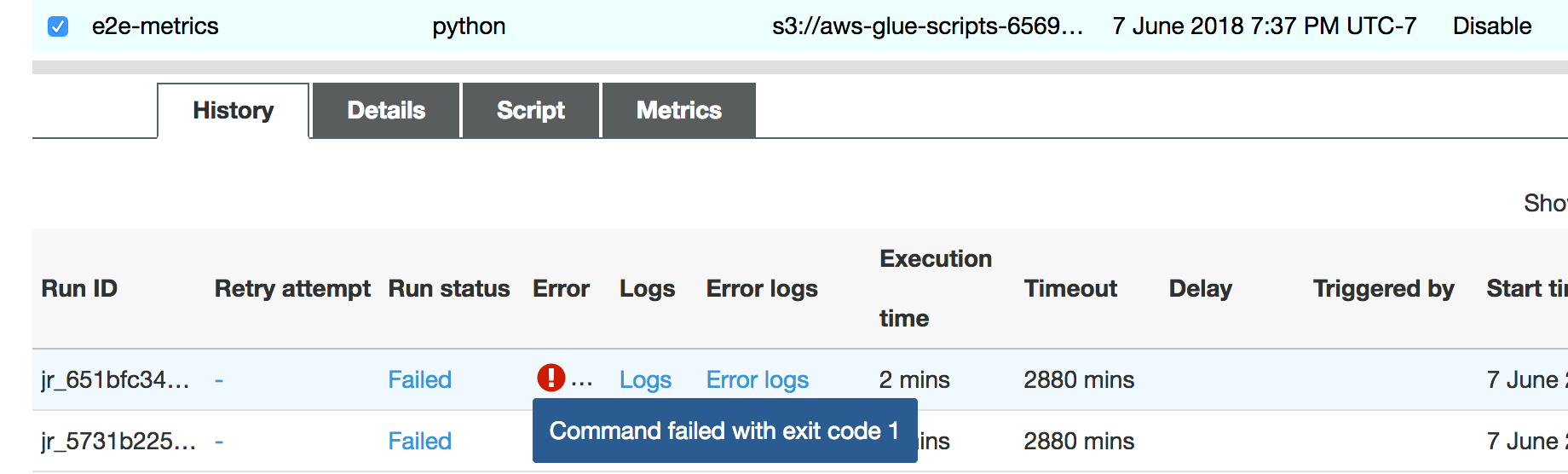
ジョブの実行はすぐに失敗し、AWS Glue コンソールの [History] (履歴) タブにエラー「Command Failed with Exit Code 1」が表示されます。このエラー文字列は、システムエラーのためにジョブが失敗したことを意味します。この場合はドライバーのメモリ不足です。
コンソールの [History] (履歴) タブにある [Error logs] (エラーログ) リンクを選択し、CloudWatch Logs からのドライバー OOM に関する詳細情報を確認します。ジョブのエラーログで「Error」を検索し、それが本当にジョブの失敗の原因となった OOM 例外であることを確認します。
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh -c "kill -9 12039"...
ジョブの [履歴] タブで、[ログ] を選択します。ジョブの開始時における CloudWatch Logs 内のドライバー実行の以下のトレースが表示されます。Spark ドライバーは、すべてのディレクトリのすべてのファイルのリストの取得を試み、InMemoryFileIndex を構築してファイルごとに 1 つのタスクを起動します。この結果、Spark ドライバーは、すべてのタスクを追跡するため、大量の状態をメモリに保持する必要が生じます。また、メモリ内インデックスの多数のファイルの完全なリストを取得するため、ドライバー OOM となります。
グループ化を使用した複数のファイルの処理を修正する
でグループ化AWS Glue機能を使用して、複数のファイルの処理を修正できます。グループ化は、動的なフレームを使用しているときと、入力データセットに多数のファイル (50,000 超) があるときに自動的に有効になります。グループかにより、複数のファイルを 1 つのグループにまとめることができ、タスクは単一のファイルではなくグループ全体を処理できるようになります。その結果、Spark ドライバーがメモリに保存する状態がかなり少なくなり、追跡するタスクが減少します。データセットのグループ化を手動で有効にする方法の詳細については、「大きなグループの入力ファイルの読み取り」を参照してください。
AWS Glue ジョブのメモリプロファイルを確認するには、グループ化を有効にして次のコードをプロファイルします。
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
AWS Glue ジョブプロファイルでは、メモリプロファイルと ETL データ移動を監視できます。
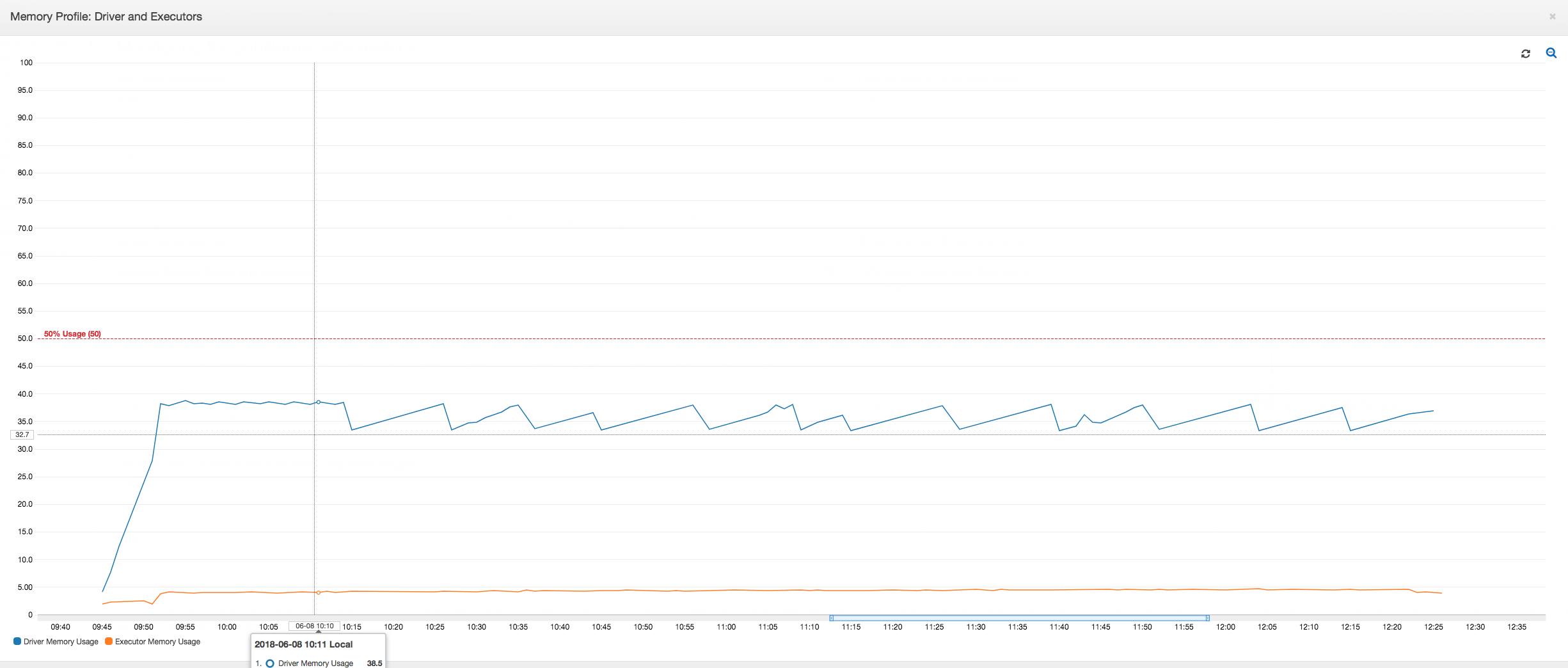
ドライバーは、AWS Glue ジョブの持続期間全体にわたって、メモリ使用率のしきい値である 50% 未満で実行されます。エグゼキュターは、Amazon S3 からデータをストリーミングして処理し、Amazon S3 に書き出します。その結果、消費されるメモリは常に 5% 未満となります。
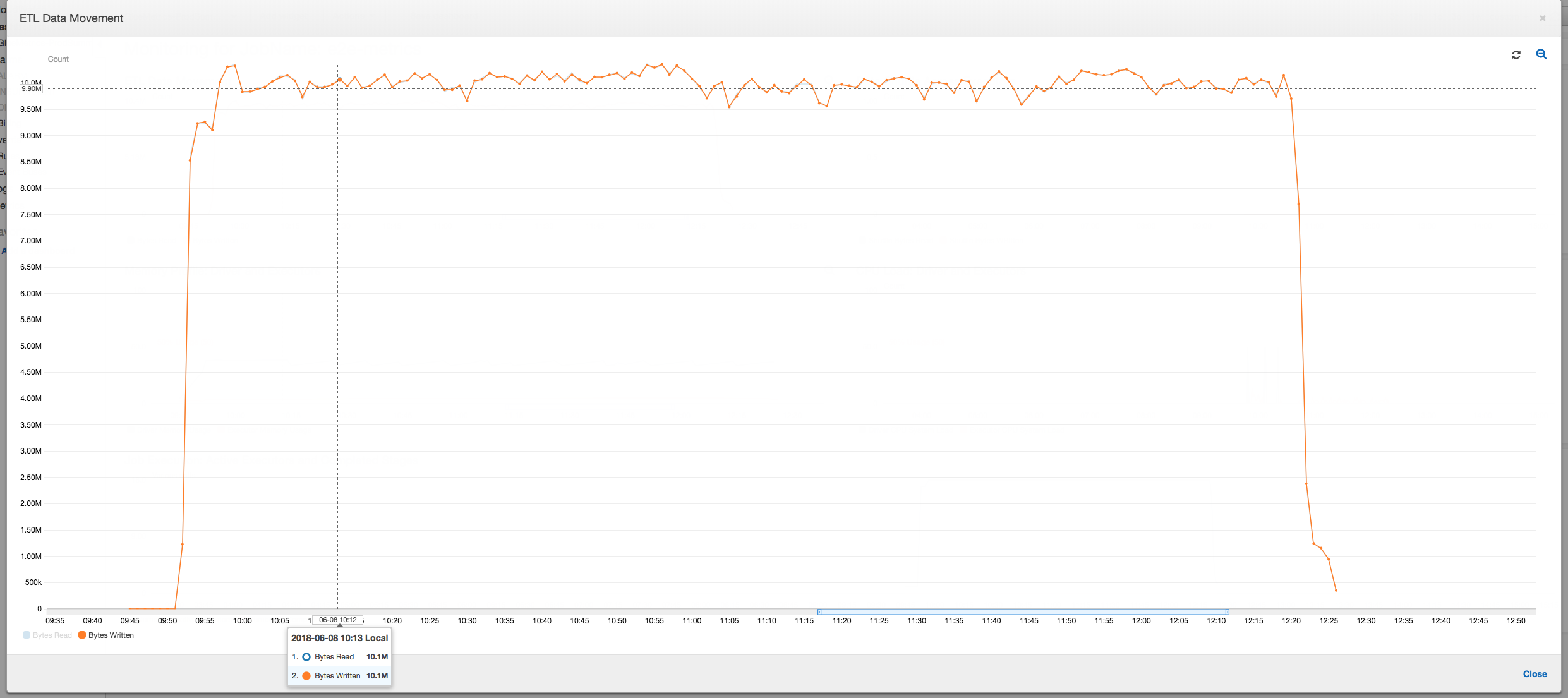
以下のデータ移動プロファイルは、ジョブが進行するにつれてすべてのエグゼキュターにより直近 1 分間に読み取りおよび書き込みされた Amazon S3 バイトの合計数を示しています。データはすべてのエグゼキュターでストリーミングされるため、どちらも同様のパターンに従っています。ジョブは、100 万ファイルすべての処理を 3 時間未満で完了します。
エグゼキュター OOM 例外のデバッグ
このシナリオでは、Apache Spark エグゼキュターで発生する可能性がある OOM 例外をデバッグする方法について説明します。次のコードでは、Spark MySQL リーダーを使用して、約 34 万行の大きなテーブルを Spark データフレームに読み取ります。次に、Parquet 形式で Amazon S3 に書き出します。接続プロパティを用意し、デフォルト Spark 設定を使用してテーブルを読み取ることができます。
val connectionProperties = new Properties() connectionProperties.put("user", user) connectionProperties.put("password", password) connectionProperties.put("Driver", "com.mysql.jdbc.Driver") val sparkSession = glueContext.sparkSession val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties) dfSpark.write.format("parquet").save(output_path)
AWS Glue コンソールでプロファイルされたメトリクスを可視化する
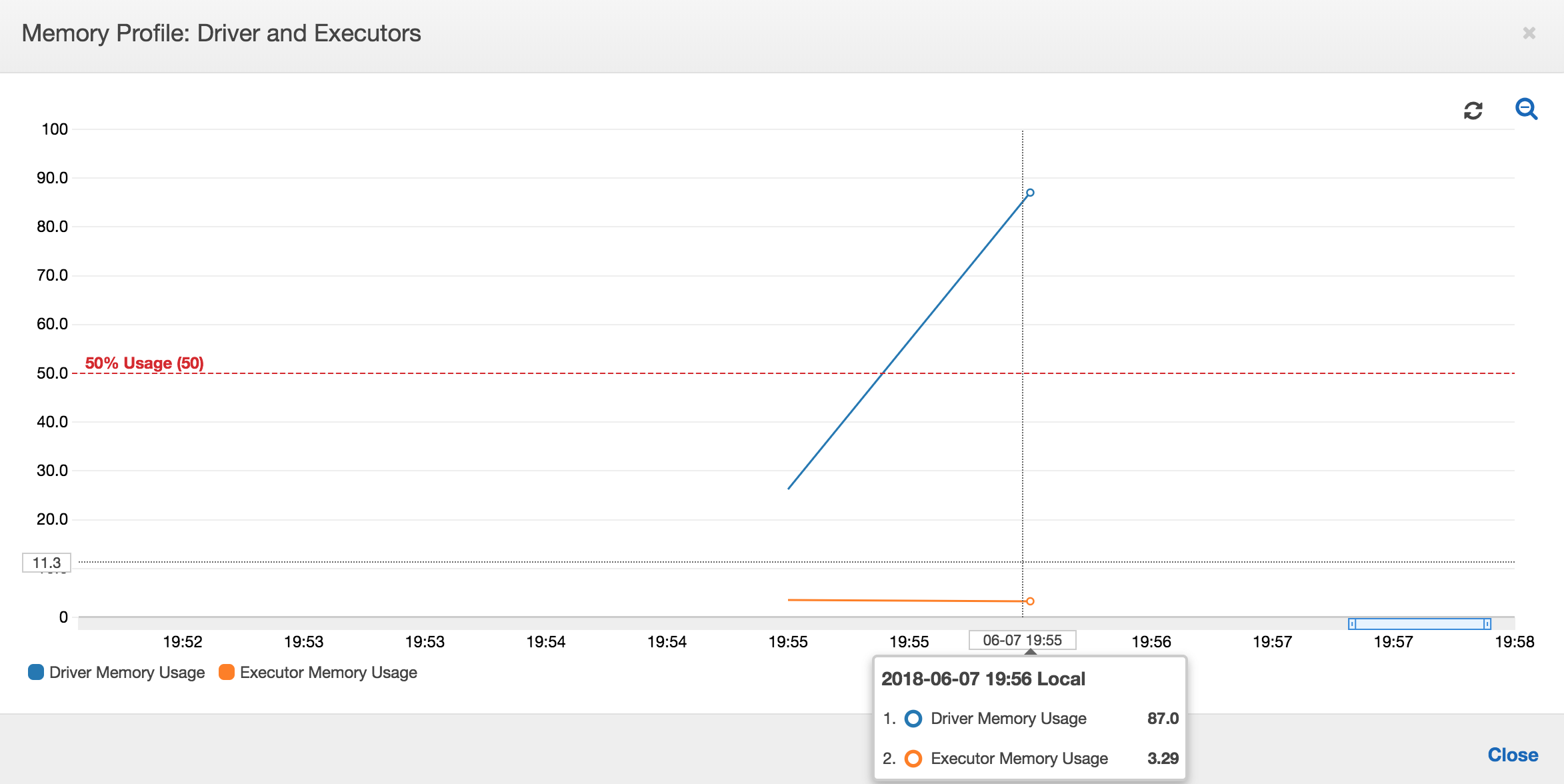
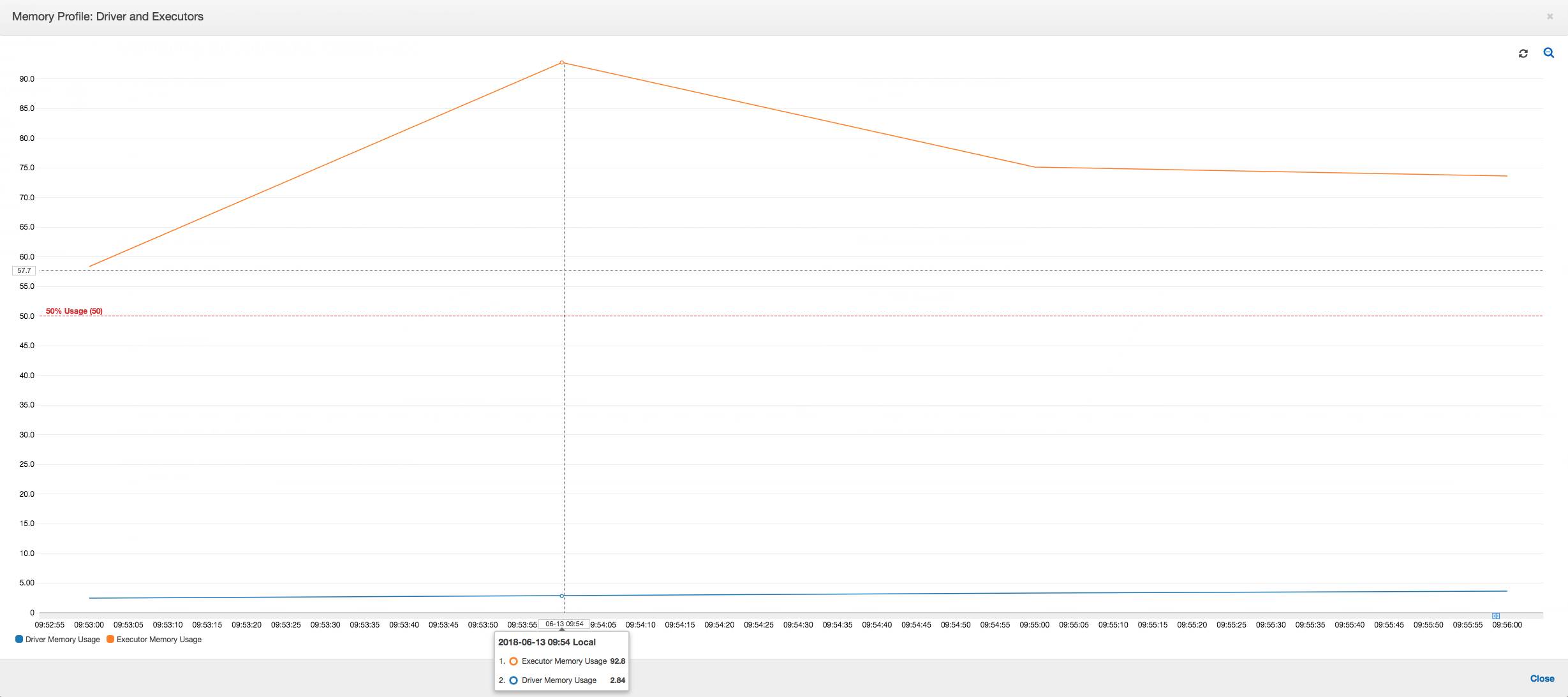
メモリ使用量グラフの傾きが正で 50% を超えた場合、および次のメトリクスが出力される前にジョブが失敗した場合は、メモリ枯渇が原因の候補となります。以下のグラフは、実行してから 1 分以内に、すべてのエグゼキュターにおける平均メモリ使用率がすぐに 50% を超えることを示しています。使用率は最大 92% に上昇し、エグゼキュターを実行するコンテナは Apache Hadoop YARN により停止されます。
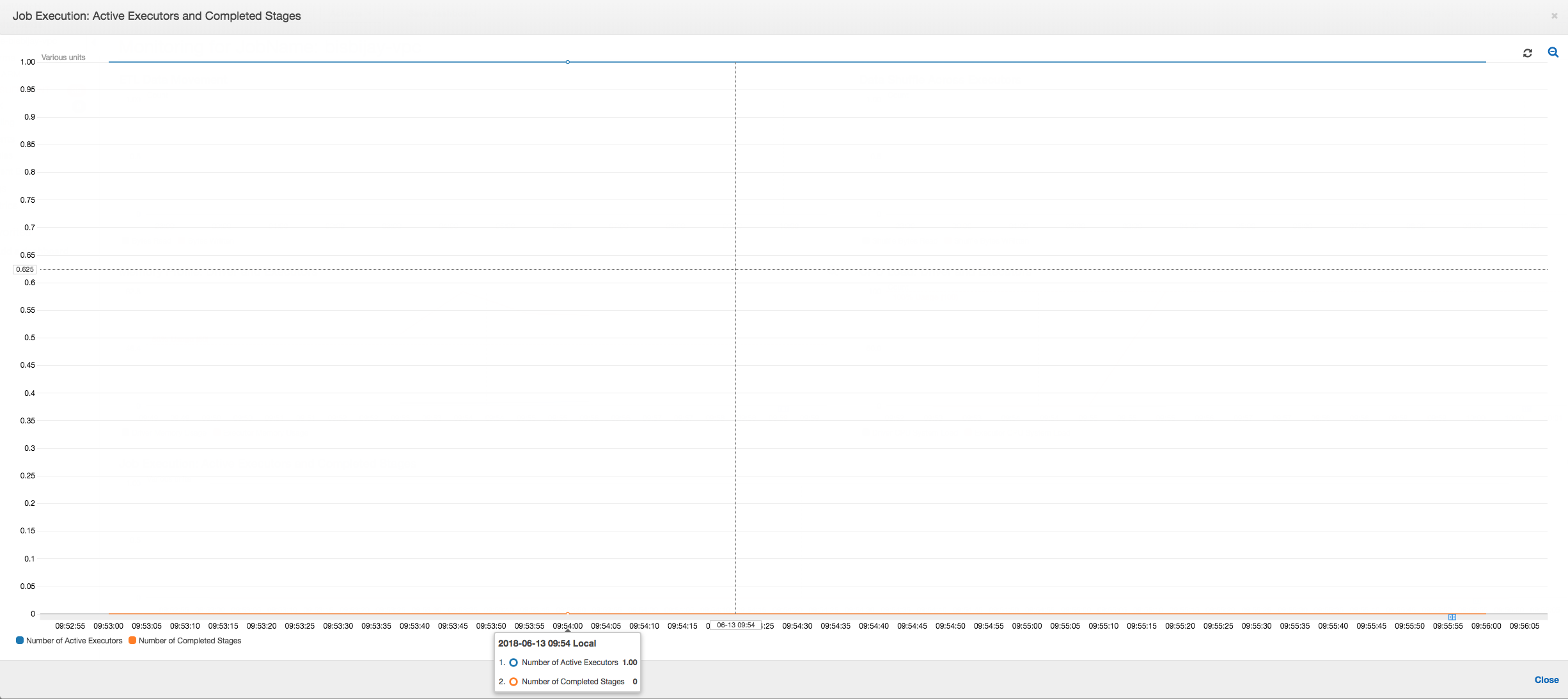
次のグラフが示すよう、ジョブが失敗するまで常に単一のエグゼキュターが実行されています。これは、新しいエグゼキュターが起動され、停止されたエグゼキュターが置き換えられるためです。JDBC データソースの読み取りは、列上のテーブルをパーティション化して複数の接続を開く必要があるため、デフォルトでは並列化されません。その結果、1 つのエグゼキュターだけがテーブル全体を順番に読み込みます。
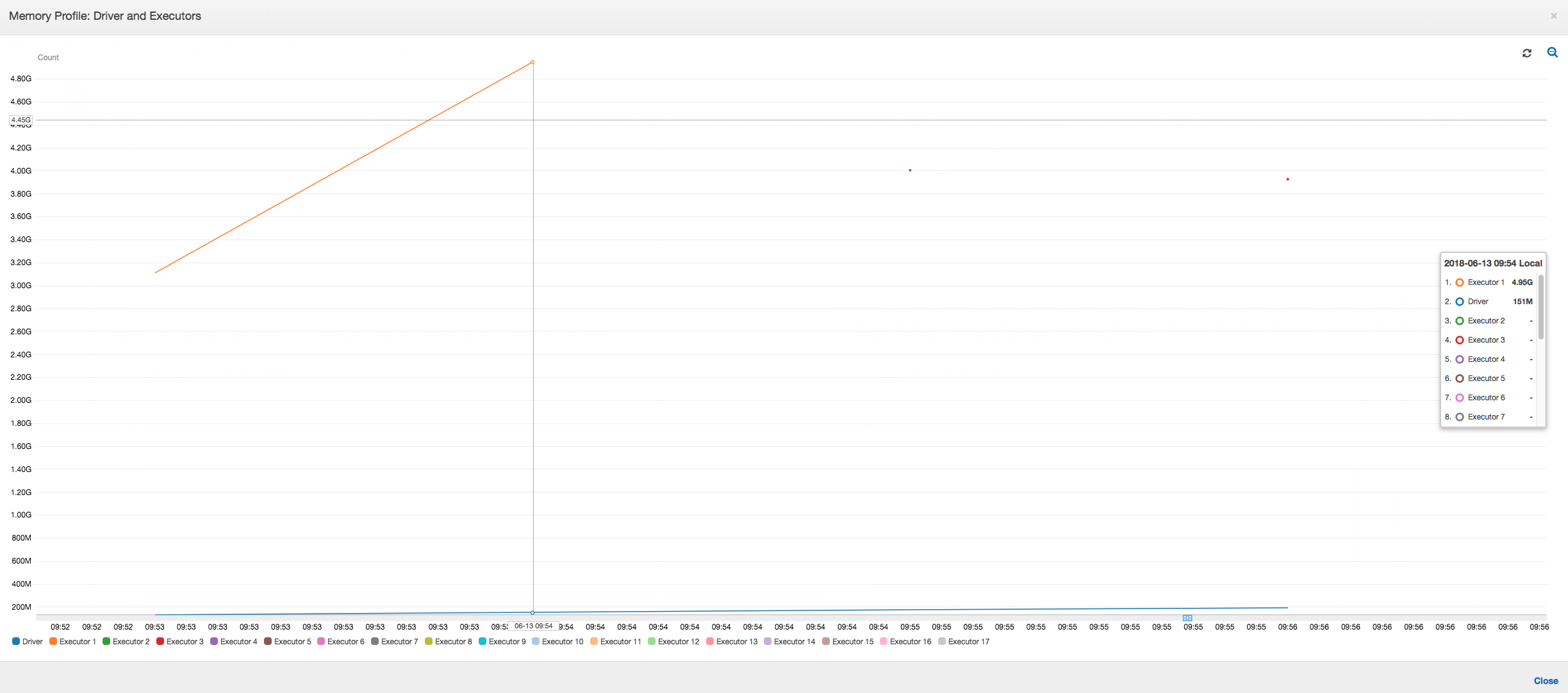
次のグラフが示すように、Spark はジョブが失敗するまでに 4 回新しいタスクを起動しようとします。3 つのエグゼキュターのメモリプロファイルを確認できます。各エグゼキュターはすべてのメモリをすぐに使い尽くします。4 番目のエグゼキュターのメモリが不足し、ジョブは失敗します。その結果、そのメトリクスはすぐに報告されません。
次の図に示すように、AWS Glue コンソールのエラー文字列からは、ジョブが OOM 例外のために失敗したことを確認できます。

ジョブ出力ログ: エグゼキュター OOM 例外の結果をさらに確認するには、CloudWatch Logs を参照します。「Error」を検索すると、メトリクスダッシュボードに示されているように、4 つのエグゼキュターがほぼ同じ時間枠で停止されています。メモリ制限を超えると、すべて YARN により終了されます。
エグゼキュター 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
エグゼキュター 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
エグゼキュター 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
エグゼキュター 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
AWS Glue 動的フレームを使用してフェッチサイズ設定を修正する
Spark JDBC フェッチサイズのデフォルトの設定が 0 であるため、エグゼキュターは JDBC テーブルの読み取り中にメモリ不足になります。つまり、Spark は行を一度に 1 つずつストリーミングしますが、Spark エグゼキュター上の JDBC ドライバーがデータベースから 3400 万行をまとめてフェッチして、それらをキャッシュしようとします。Spark を使用すると、フェッチサイズパラメータを 0 以外のデフォルト値に設定することにより、このシナリオを回避できます。
代わりに AWS Glue 動的フレームを使用することで、この問題を解決することもできます。デフォルトでは、動的フレームは 1,000 行のフェッチサイズを使用します。これは通常十分な値です。このため、エグゼキュターが合計メモリの 7% 超を使用することはありません。AWS Glue ジョブは、エグゼキュターを 1 つだけ使用して 2 分未満で完了します。AWS Glue 動的フレームを使用することが推奨されるアプローチですが、Apache Spark の fetchsize プロパティを使用してフェッチサイズを設定することもできます。「Spark SQL、DataFrames および Datasets ガイド
val (url, database, tableName) = { ("jdbc_url", "db_name", "table_name") } val source = glueContext.getSource(format, sourceJson) val df = source.getDynamicFrame glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
プロファイルされた通常のメトリクス: 以下の図に示すように、AWS Glue 動的フレームを持つエグゼキュターメモリが安全しきい値を超えることはありません。データベースから行をストリーミングし、任意の時点で 1,000 行のみ JDBC ドライバーにキャッシュします。メモリ不足例外は発生しません。