要求の厳しいステージとストラグラータスクのデバッグ
AWS Glue ジョブプロファイリングを使用して、抽出、変換、ロード (ETL) ジョブで要求の厳しいステージとストラグラータスクを特定できます。ストラグラータスクは、AWS Glue ジョブのステージに含まれる他のタスクよりかなり時間がかかります。その結果、ステージの完了まで時間がかかり、ジョブの合計実行時間も遅延します。
小さい入力ファイルを大きい出力ファイルにまとめる
ストラグラータスクは、さまざまなタスク間の処理が均等に分散していないときや、データスキューによって特定のタスクが処理するデータが多くなった場合に発生する可能性があります。
Apache Spark の一般的なパターンである次のコードをプロファイルし、多数の小さいファイルをいくつかの大きい出力ファイルにまとめることができます。この例では、入力データセットは 32 GB の JSON Gzip 圧縮ファイルです。出力データセットには、約 190 GB の圧縮されていない JSON ファイルが含まれています。
プロファイルされたコードは次のとおりです。
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
AWS Glue コンソールでプロファイルされたメトリクスを可視化する
ジョブをプロファイルすると、4 つのメトリクスセットを調べることができます。
-
ETL データ移動
-
エグゼキュター間のデータシャッフル
-
ジョブの実行
-
メモリプロファイル
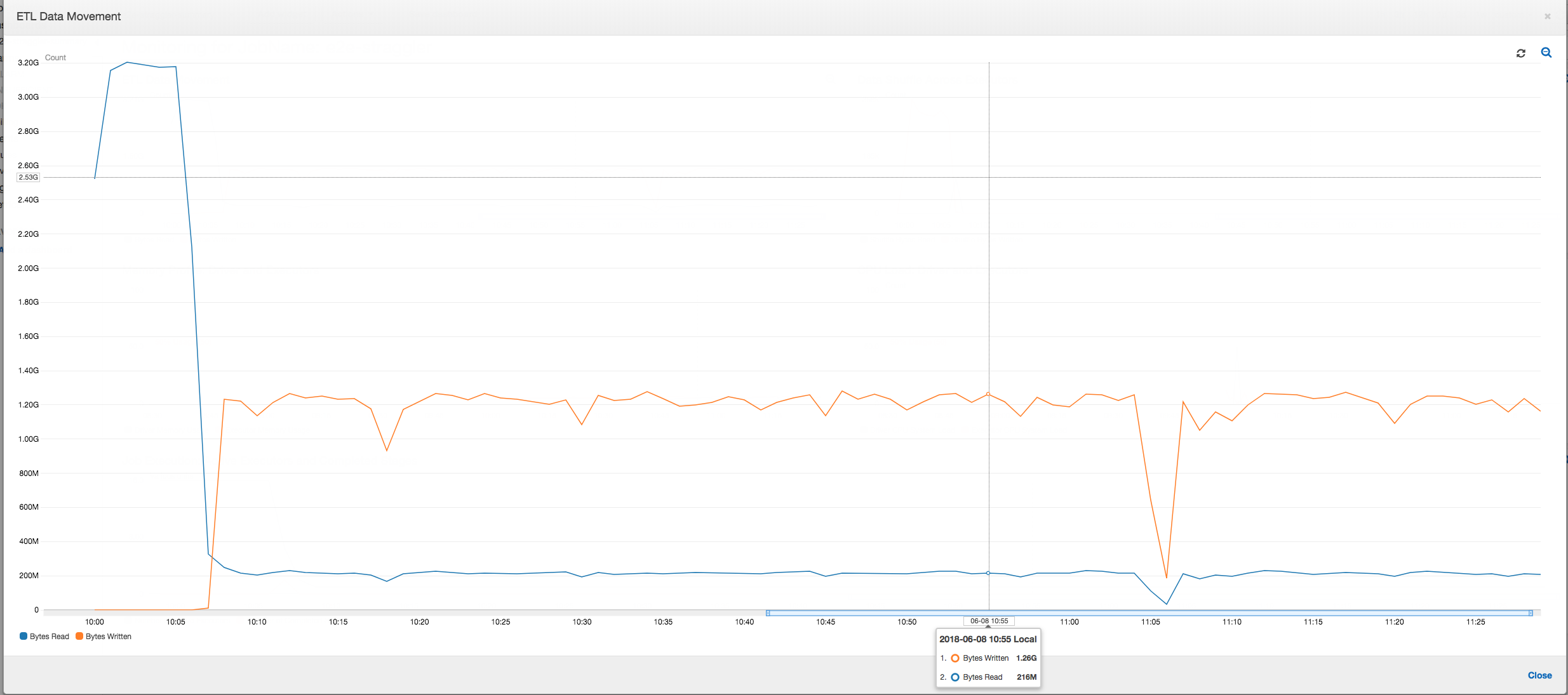
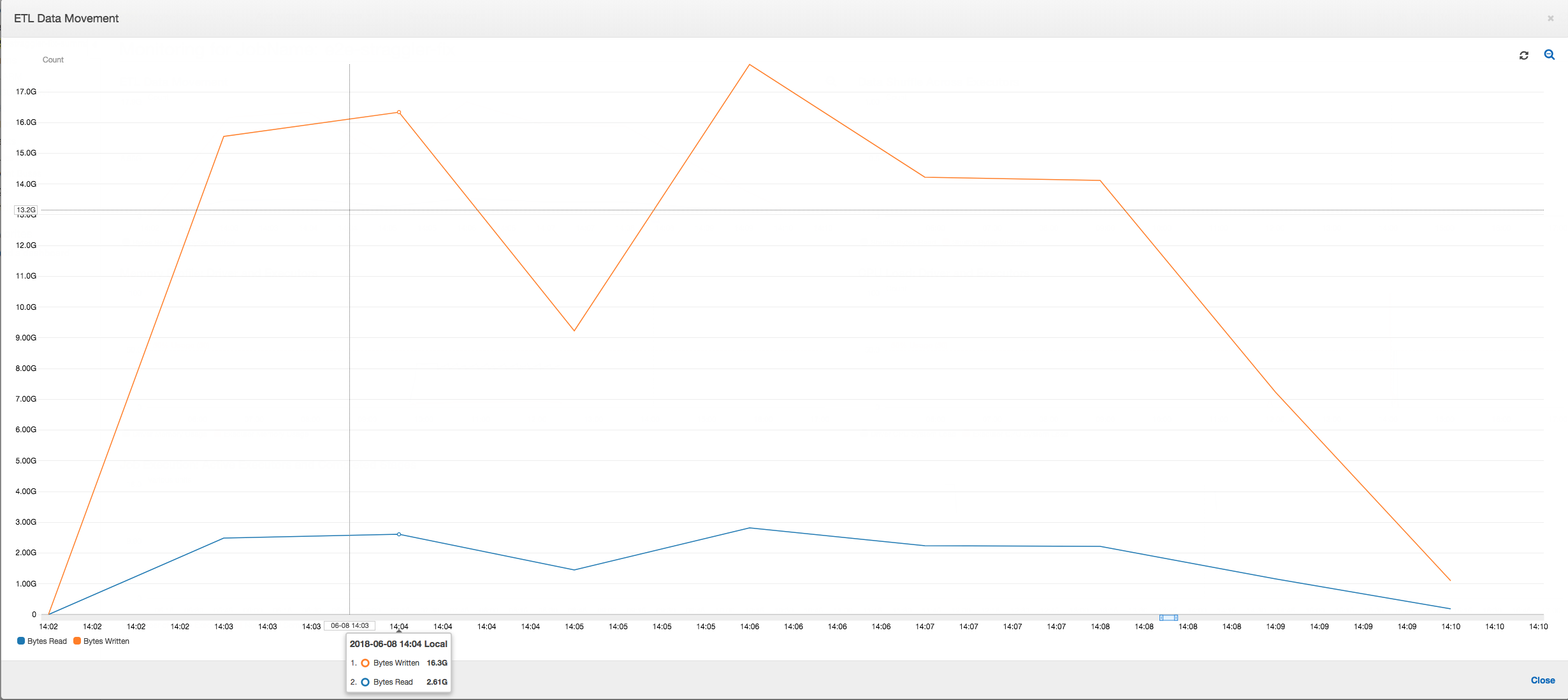
ETL データ移動: [ETL Data Movement (ETL データ移動)] プロファイルでは、バイトは、最初の 6 分間に完了する最初のステージのすべてのエグゼキュターにより比較的早く読み取られます。ただし、ジョブの合計実行時間が約 1 時間の場合、ほとんどがデータの書き込みで構成されます。
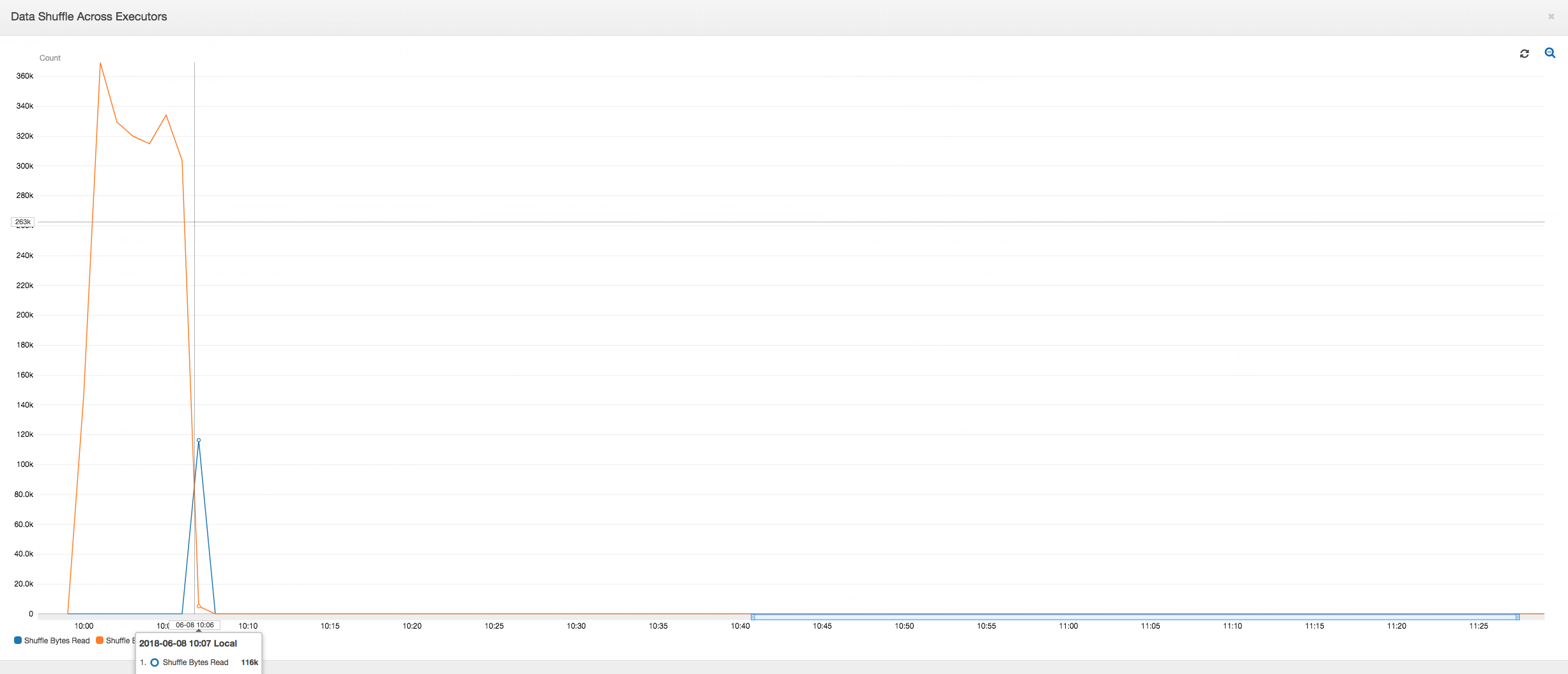
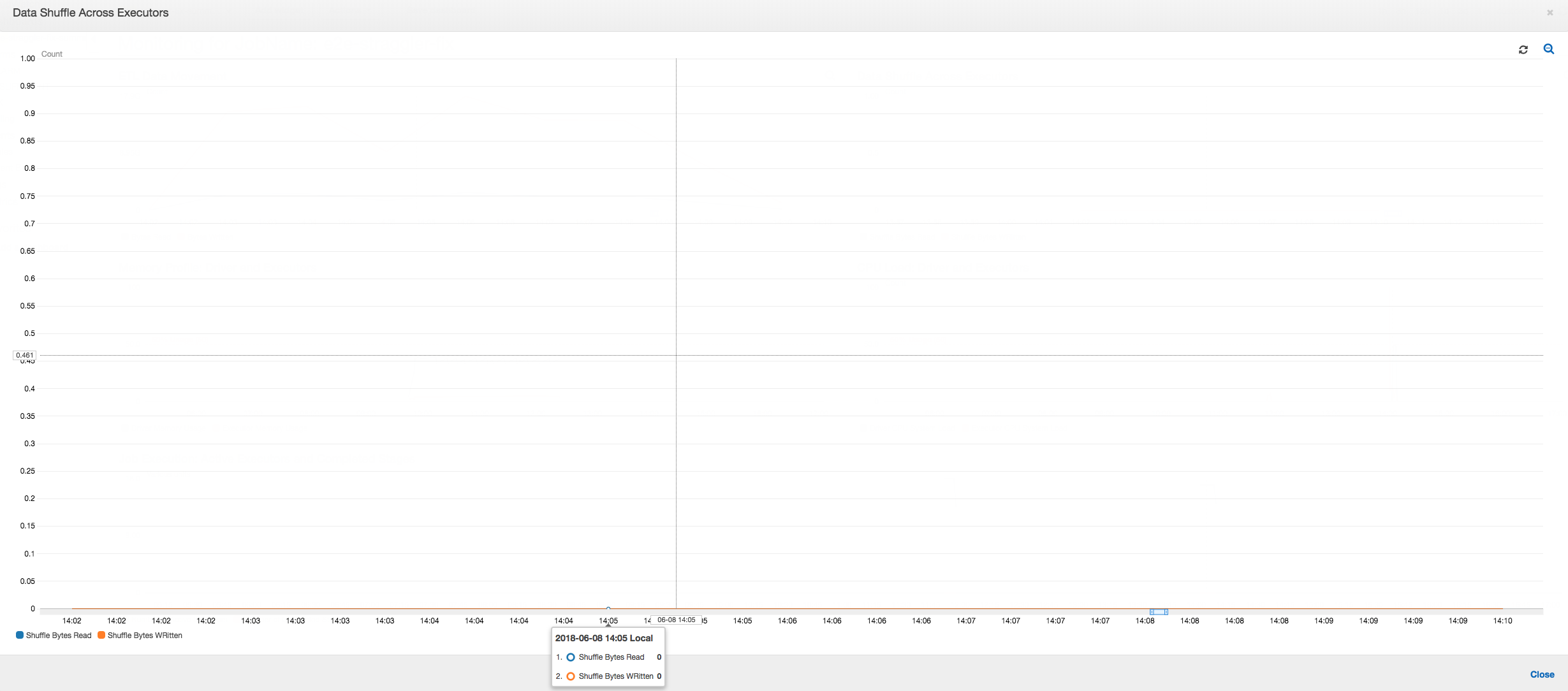
エグゼキュター間のデータシャッフル: ジョブ実行メトリクスとデータシャッフルメトリクスが示しているように、シャッフル中の読み取りおよび書き込みのバイト数も、ステージ 2 が終了する前に急増しています。すべてのエグゼキュターからのデータシャッフルの後、読み取りと書き込みはエグゼキュター 3 番のみから続行されます。
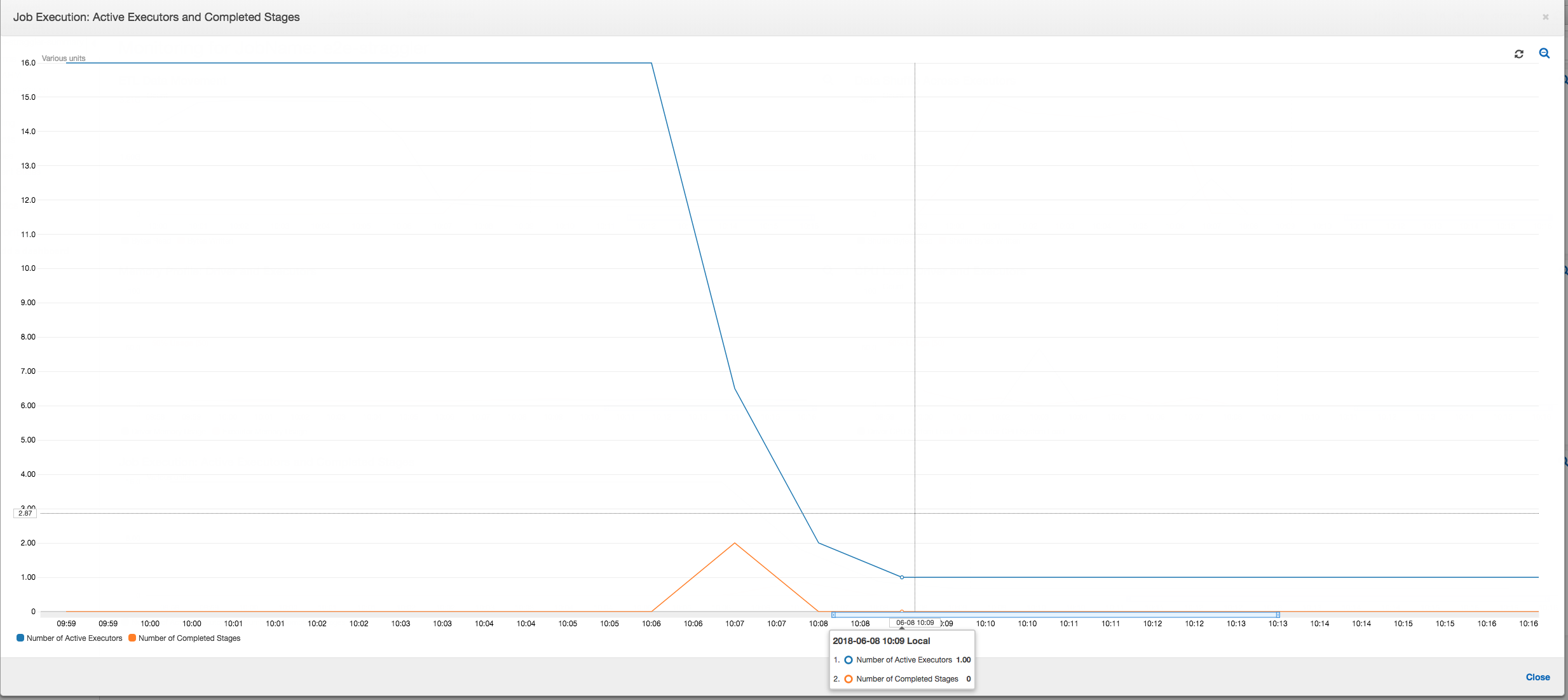
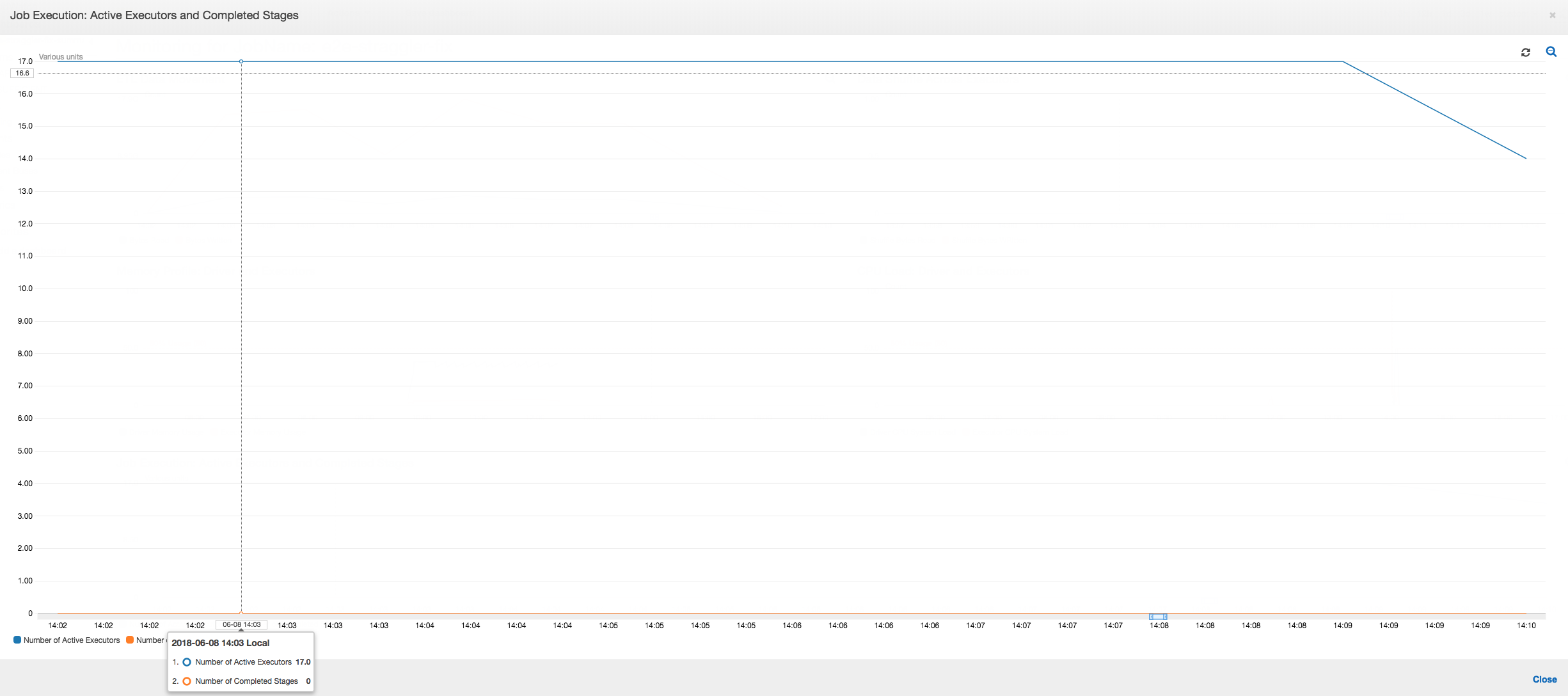
ジョブの実行: 以下のグラフに示すように、他のすべてのエグゼキュターはアイドル状態であり、最終的に時間 10:09 までに破棄されます。この時点で、エグゼキュターの合計数はわずか 1 に減ります。これは、エグゼキュター 3 番が、実行時間が最も長いストラグラータスクで構成されているため、ジョブの実行時間の大部分を占めていることを明確に示しています。
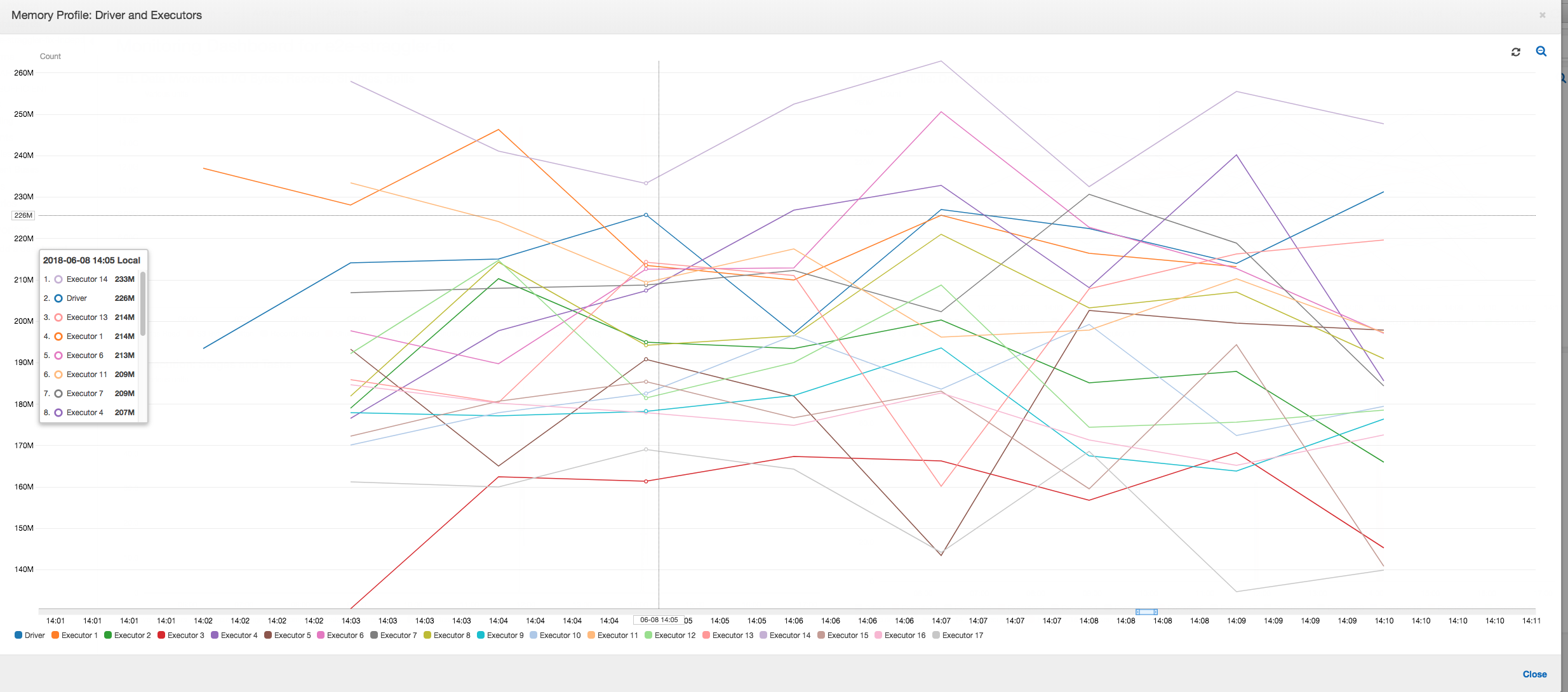
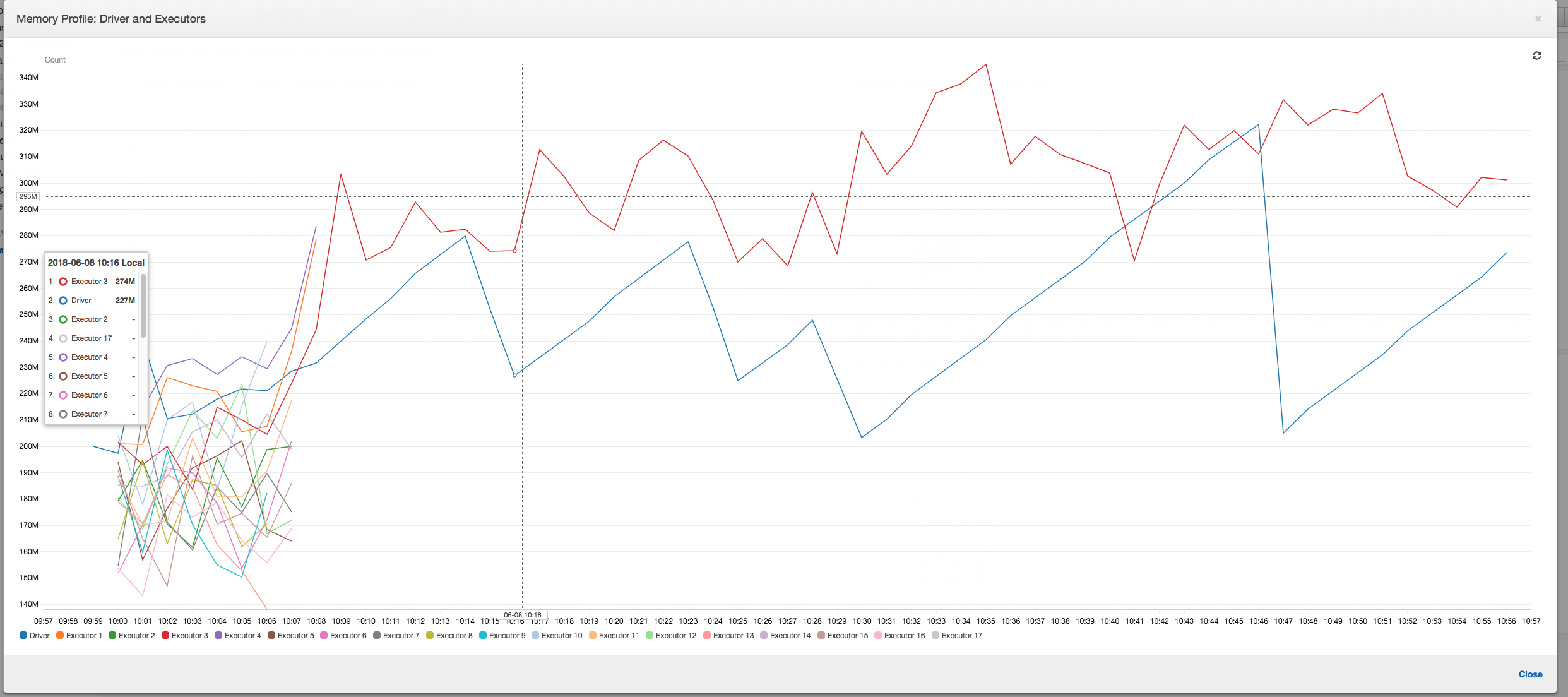
メモリプロファイル: 最初の 2 つのステージの後、エグゼキュター 3 番のみがメモリをアクティブに消費してデータを処理します。残りのエグゼキュターはアイドル状態のままであるか、最初の 2 つのステージの完了後すぐに破棄されます。
グループ化を使用してストラグラーエグゼキュターを修正する
ストラグラーエグゼキュターは、 でグループ化AWS Glueを使用して回避できます。グループ化を使用してデータをすべてのエグゼキュター間に均等に分散し、クラスター内で利用可能なすべてのエグゼキュターを使用して大きいファイルにまとめます。詳細については、 を参照してください。大きなグループの入力ファイルの読み取り
AWS Glue ジョブで ETL データ移動を確認するには、グループ化を有効にして次のコードをプロファイルします。
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
ETL データ移動: データの書き込みは、ジョブの実行時間全体にわたって、データの読み取りと並行してストリーミングされるようになりました。その結果、ジョブは 8 分以内に終了します。以前よりもはるかに早いスピードです。
エグゼキュター間でのデータシャッフル: グループ化機能を使用して読み取り中に入力ファイルがまとめられると、データの読み取り後、コストのかかるデータシャッフルが行われなくなります。
ジョブの実行: ジョブ実行メトリクスは、実行されてデータを処理しているアクティブなエグゼキュターの合計数がかなり安定していることを示しています。ジョブに単一のストラグラーはありません。すべてのエグゼキュターがアクティブで、ジョブが完了するまでは破棄されません。エグゼキュター間でデータの中間シャッフルは行われないため、ジョブにはステージが 1 つしかありません。
メモリプロファイル: このメトリクスは、すべてのエグゼキュター間のアクティブなメモリ消費を示しています。これは、すべてのエグゼキュター間にアクティビティがあることを再確認するものです。データは並行してストリーミングおよび書き出されるため、すべてのエグゼキュターの合計メモリ使用量はほぼ均等で、すべてのエグゼキュター安全しきい値をかなり下回っています。