翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Spark のシャッフルデータの保存
シャッフルは、データがパーティション間で再配置されるたびに行われる Spark ジョブの重要なステップです。これが必要なのは、join、
groupByKey、reduceByKey、repartition などのさまざまな変換に、処理を完了するために他のパーティションからの情報が必要なためです。Spark は各パーティションから必要なデータを収集し、新しいパーティションに結合します。シャッフル中、データはディスクに書き込まれ、ネットワーク経由で転送されます。その結果、シャッフルオペレーションはローカルディスク容量に制約されます。Spark の No space left on device または
MetadataFetchFailedException エラーは、エグゼキュターに十分なディスク領域がなく、リカバリがない場合に発生します。
注記
Amazon S3 での AWS Glue Spark シャッフルプラグインは、AWS Glue ETL ジョブについてのみサポートされています。
ソリューション
AWS Glue では、Amazon S3 を使用して Spark シャッフルデータを保存できるようになりました。Amazon S3 は、業界をリードするスケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。このソリューションで、Spark ジョブ用のコンピューティングとストレージが非集約化され、完全な伸縮自在性と低コストのシャッフルストレージが得られ、シャッフル負荷の高いワークロードが高い信頼性で実行できるようになります。
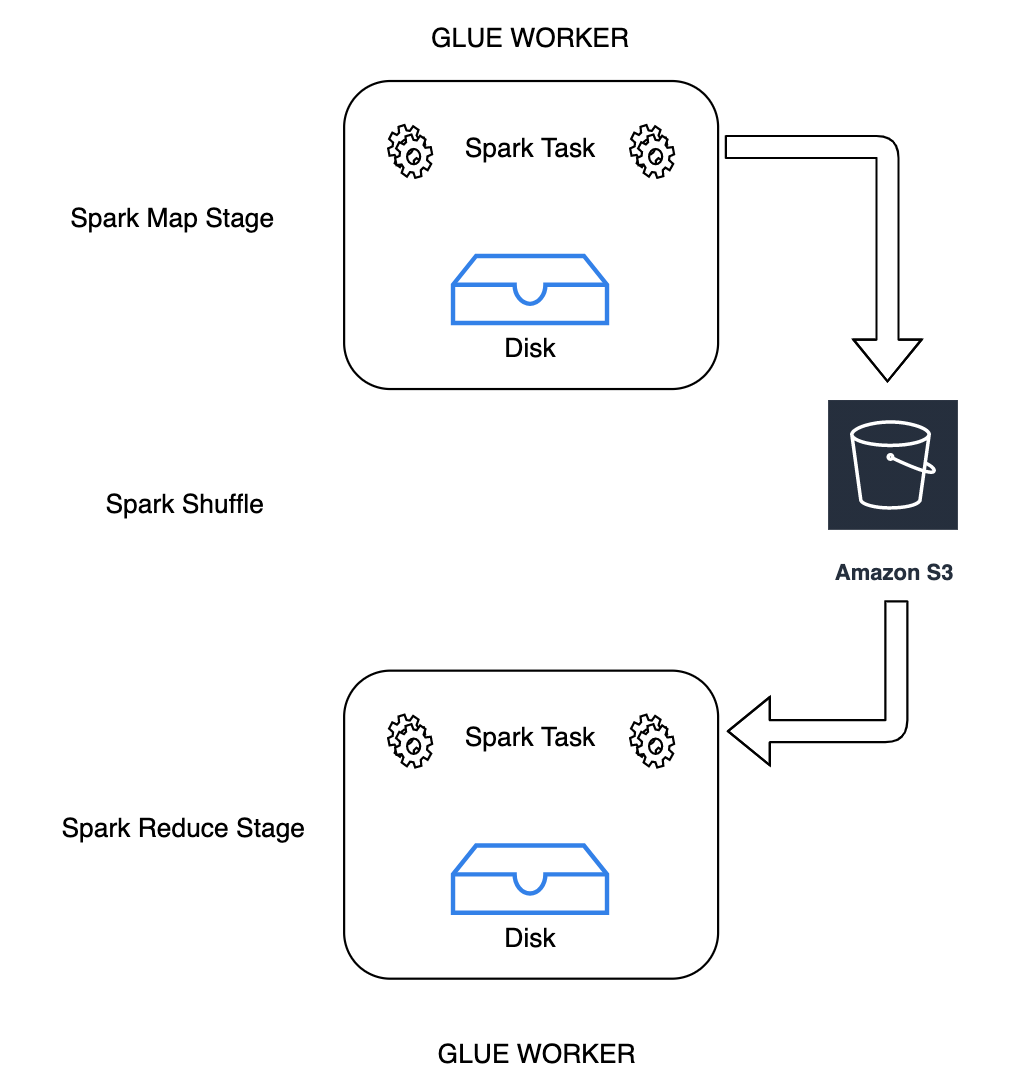
Amazon S3 を使用するための Cloud Shuffle Storage Plugin for Apache Spark を導入します。大きなシャッフルオペレーションのためにローカルディスク容量の制約を受けることがわかっている場合、Amazon S3 シャッフルを有効にすると、AWS Glue ジョブを失敗することなく高い信頼性で実行できます。小さなパーティションが多数ある場合や、Amazon S3 に書き込まれたファイルをシャッフルする場合、Amazon S3 へのシャッフルはローカルディスク (または EBS) よりもわずかに遅くなる場合があります。
クラウドシャッフルストレージプラグインを使用するための前提条件
AWS Glue ETL ジョブにクラウドシャッフルストレージプラグインを使用するには、以下が必要です。
-
途中のシャッフルデータやスピルしたデータを保存するための、ジョブが実行されているのと同じリージョンにある Amazon S3 バケット。シャッフルストレージの Amazon S3 プレフィックスは、
--conf spark.shuffle.glue.s3ShuffleBucket=s3://で次の例のように指定できます。shuffle-bucket/prefix/--conf spark.shuffle.glue.s3ShuffleBucket=s3://glue-shuffle-123456789-us-east-1/glue-shuffle-data/ -
シャッフルマネージャーはジョブの終了後にファイルをクリーンアップしないため、プレフィックス (
glue-shuffle-dataなど) に Amazon S3 ストレージライフサイクルポリシーを設定します。途中のシャッフルデータやスピルしたデータは、ジョブの終了後に削除する必要があります。ユーザーはプレフィックスに短いライフサイクルポリシーを設定できます。Amazon S3 ライフサイクルポリシーのセットアップ手順については、「Amazon Simple Storage Service ユーザーガイド」の「バケットのライフサイクル設定の指定」を参照してください。
AWS コンソールからの AWS Glue Spark シャッフルマネージャーの使用
ジョブを設定するときに AWS Glue コンソールまたは AWS Glue Studio を使用して AWS Glue Spark シャッフルマネージャーをセットアップするには、--write-shuffle-files-to-s3 ジョブパラメータを選択して、ジョブの Amazon S3 シャッフルを有効にします。
AWS Glue Spark シャッフルプラグインの使用
次のジョブパラメータで、AWS Glue シャッフルマネージャーが有効になり、チューニングされます。これらのパラメータはフラグなので、指定された値は考慮されません。
-
--write-shuffle-files-to-s3– メインフラグです。Amazon S3 バケットを使用してシャッフルデータの書き込みと読み込みを行う AWS Glue Spark シャッフルマネージャーが有効になります。フラグを指定しない場合、シャッフルマネージャーは使用されません。 -
--write-shuffle-spills-to-s3– (AWS Glue バージョン 2.0 でのみサポートされています)。オプションのフラグです。スピルファイルを Amazon S3 バケットにオフロードできます。これにより、Spark ジョブの耐障害性が強化されます。これは、大量のデータをディスクに退避させる大規模なワークロードにのみ必要です。フラグが指定されていない場合、中間スピルファイルは書き込まれません。 -
--conf spark.shuffle.glue.s3ShuffleBucket=s3://<shuffle-bucket>– 別のオプションのフラグです。シャッフルファイルを書き込む Amazon S3 バケットを指定します。デフォルトでは、--TempDir/shuffle data です。AWS Glue 3.0 以降では、--conf spark.shuffle.glue.s3ShuffleBucket=s3://のようにバケットをカンマ区切りで指定することで、シャッフルファイルを複数のバケットに書き込むことができます。複数のバケットを使用するとパフォーマンスが向上します。shuffle-bucket-1/prefix,s3://shuffle-bucket-2/prefix/
シャッフルデータの保存時の暗号化を有効にするには、セキュリティ構成設定を提供する必要があります。 セキュリティの構成の詳細については、「AWS Glue での暗号化のセットアップ」を参照してください。AWS Glue は、Spark が提供する他のすべてのシャッフル関連の構成をサポートします。
クラウドシャッフルストレージプラグインのソフトウェアバイナリ
また、Apache 2.0 ライセンスで Cloud Shuffle Storage Plugin for Apache Spark のソフトウェアバイナリをダウンロードして、任意の Spark 環境で実行することもできます。新しいプラグインは Amazon S3 をそのまま使えるようにサポートしており、Google クラウドストレージや Microsoft Azure Blob ストレージ
注意事項と制限事項
AWS Glue シャッフルマネージャーには次の注意事項や制限事項があります。
-
AWS Glue シャッフルマネージャーは、ジョブの完了後に Amazon S3 バケットに保存されている (一時的な) シャッフルデータファイルを自動的に削除しません。データを確実に保護するには、Cloud Shuffle ストレージプラグインを有効にする前に、クラウドシャッフルストレージプラグインを使用するための前提条件 の手順に従ってください。
-
データに偏りがある場合、この機能が使用できます。
