翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Apache Spark ウェブ UI を使用したジョブのモニタリング
Apache Spark ウェブ UI を使用して、AWS Glue ジョブシステムで実行されている AWS Glue ETL ジョブと、 AWS Glue 開発エンドポイントで実行されている Spark アプリケーションをモニタリングおよびデバッグできます。Spark UI では、ジョブごとに以下の項目を確認できます。
-
各 Spark ステージのイベントタイムライン
-
ジョブの Directed Acyclic Graph (DAG)
-
SparkSQL クエリの物理プランと論理プラン
-
各ジョブの基盤となる Spark 環境変数
Spark Web UI の使用の詳細については、Spark ドキュメントの「Web UI
AWS Glue コンソールで Spark UI を確認できます。これは、 AWS Glue ジョブが AWS Glue 3.0 以降のバージョンで実行され、新しいジョブのデフォルトである標準 (レガシーではなく) 形式で生成されたログがある場合に使用できます。0.5 GB を超えるログファイルがある場合は、 AWS Glue 4.0 以降のバージョンで実行されるジョブのローリングログサポートを有効にして、ログのアーカイブ、分析、トラブルシューティングを簡素化できます。
AWS Glue コンソールまたは AWS Command Line Interface () を使用して、Spark UI を有効にできますAWS CLI。Spark UI を有効にすると、AWS Glue ETL ジョブと、AWS Glue 開発エンドポイントの Spark アプリケーションの Spark イベントログを Amazon Simple Storage Service (Amazon S3) の指定した場所にバックアップできます。Amazon S3 にバックアップされたイベントログは、ジョブの実行中 (リアルタイム) でも、ジョブの完了後でも Spark UI で使用できます。ログが Amazon S3 に残っている間は、 AWS Glue コンソールの Spark UI でログを表示できます。
アクセス許可
AWS Glue コンソールで Spark UI を使用するには、すべての個々のサービス APIsを使用UseGlueStudioまたは追加できます。Spark UI を完全に使用するには、すべての API が必要です。ただし、ユーザーはきめ細かくアクセスするために、IAM 許可にサービス API を追加して SparkUI の機能にアクセスできます。
RequestLogParsing はログの解析を行うため、最も重要です。残りの API は、それぞれの解析済みデータを読み取るためのものです。たとえば、GetStages は Spark ジョブのすべてのステージに関するデータへのアクセスを提供します。
UseGlueStudio にマッピングされた Spark UI サービス API のリストは、以下のサンプルポリシーに記載されています。以下のポリシーは、Spark UI 機能のみを使用するためのアクセスを提供します。Amazon S3 や IAM などのアクセス許可を追加するには、「 のカスタム IAM ポリシーの作成」を参照してください AWS Glue Studio。
UseGlueStudio にマッピングされた Spark UI サービス API のリストは、以下のサンプルポリシーに記載されています。Spark UI サービス API を使用するとき、glue:<ServiceAPI> という名前空間を使用してください。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowGlueStudioSparkUI", "Effect": "Allow", "Action": [ "glue:RequestLogParsing", "glue:GetLogParsingStatus", "glue:GetEnvironment", "glue:GetJobs", "glue:GetJob", "glue:GetStage", "glue:GetStages", "glue:GetStageFiles", "glue:BatchGetStageFiles", "glue:GetStageAttempt", "glue:GetStageAttemptTaskList", "glue:GetStageAttemptTaskSummary", "glue:GetExecutors", "glue:GetExecutorsThreads", "glue:GetStorage", "glue:GetStorageUnit", "glue:GetQueries", "glue:GetQuery" ], "Resource": [ "*" ] } ] }
制限事項
-
AWS Glue コンソールの Spark UI は、レガシーログ形式であるため、2023 年 11 月 20 日より前に発生したジョブ実行では使用できません。
-
AWS Glue コンソールの Spark UI は、ストリーミングジョブでデフォルトで生成されるログなど、 AWS Glue 4.0 のローリングログをサポートします。生成されたすべてのロールされたログファイルの最大合計は 2 GB です。ロールログがサポートされていない AWS Glue ジョブの場合、SparkUI でサポートされるログファイルの最大サイズは 0.5 GB です。
-
Serverless Spark UI は、VPC のみがアクセスできる Amazon S3 バケットに保存されている Spark イベントログでは使用できません。
例: Apache Spark Web UI
この例では、Spark UI を使用してジョブのパフォーマンスを理解する方法を示します。 スクリーンショットは、自己管理型の Spark 履歴サーバーが提供する Spark ウェブ UI を示しています。 AWS Glue コンソールの Spark UI も同様のビューを提供します。Spark Web UI の使用の詳細については、Spark ドキュメントの「Web UI
次の例に示す Spark アプリケーションでは、2 つのデータソースから読み取り、結合変換を実行し、それを Parquet 形式で Amazon S3 に書き込みます。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.functions import count, when, expr, col, sum, isnull from pyspark.sql.functions import countDistinct from awsglue.dynamicframe import DynamicFrame args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME']) df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json") df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json") df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter') df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/") job.commit()
次の DAG 可視化は、この Spark ジョブのさまざまなステージを示しています。
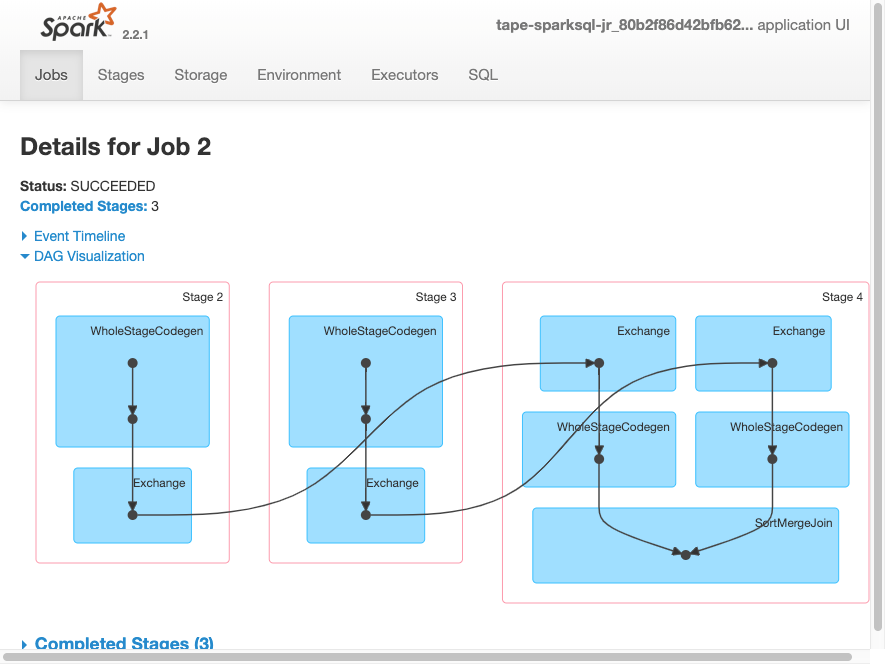
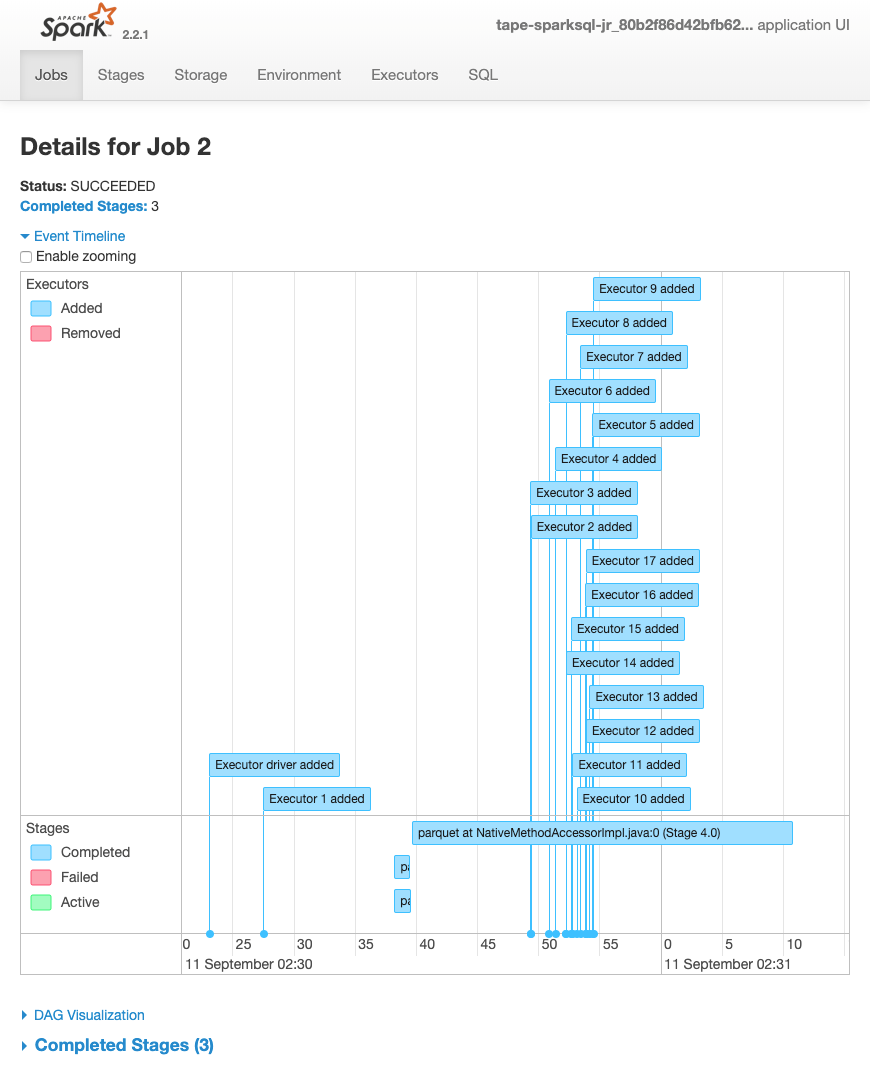
次に示すジョブのイベントタイムラインは、さまざまな Spark エグゼキュターの開始、実行、終了を示しています。
次の画面は、SparkSQL クエリプランの詳細を示しています。
-
解析された論理プラン
-
分析された論理プラン
-
最適化された論理プラン
-
実行のための物理プラン

