正規表現による文字列の断片の抽出
この変換は、正規表現を使用して文字列の断片を抽出し、そこから新しい列を作成します。正規表現グループを使用する場合は複数の列を作成します。
正規表現抽出変換ノードをジョブ図に追加するには
-
リソースパネルを開いて、[Regex Extractor] を選択し、ジョブ図に新しい変換を追加します。ノードを追加する際に選択したノードが、その親になります。
ノードのプロパティパネルで、ジョブ図にノード名を入力します。ノードの親がまだ選択されていない場合、[Node parents] (ノードの親) リストから、変換の入力ソースとして使用するノードを選択します。
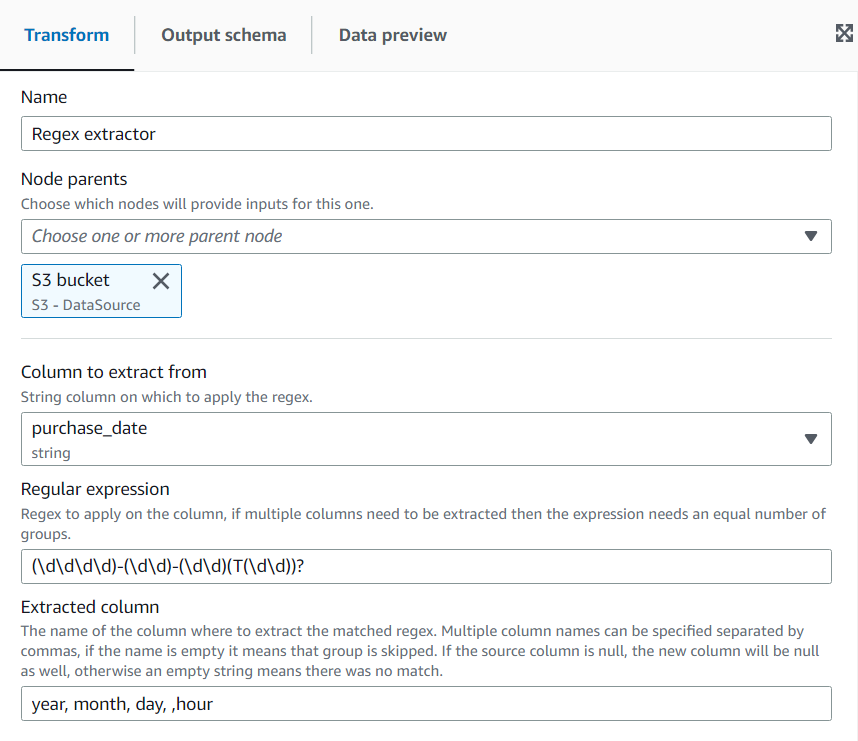
[変換] タブに、正規表現とそれを適用する必要のある列を入力します。続いて、一致する文字列を格納する新しい列の名前を入力します。新しい列は、ソース列が null の場合にのみ null になり、正規表現が一致しない場合は空になります。
正規表現がグループを使用する場合、対応する列名はカンマで区切られますが、列名を空のままにすることでグループをスキップできます。
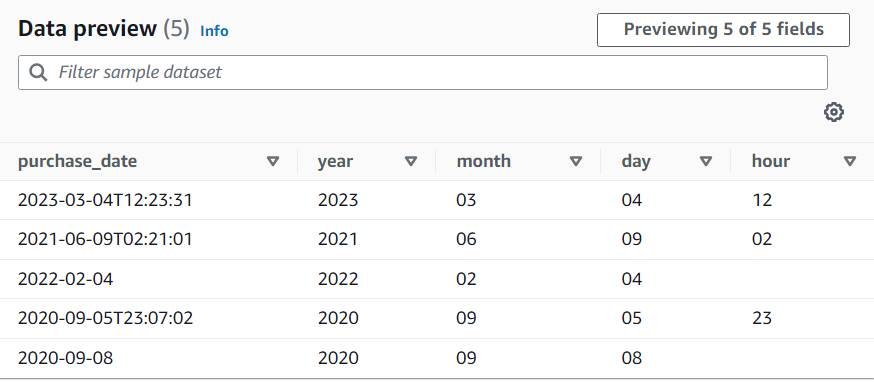
例えば、長い ISO 日付形式と短い ISO 日付形式の両方を使用する文字列を含む列「purchase_date」があり、使用可能な場合は、年、月、日、時間を抽出します。時間グループはオプションであり、使用できない場合、(正規表現が一致しないため) 抽出されたすべてのグループは空の文字列になります。グループで、時間をオプションではなく含めたい場合は、名前を空のままにすることで抽出されなくなります (グループには T 文字が含まれます)。
データプレビューの結果: