慎重な検討の結果、Amazon Kinesis Data Analytics for SQL アプリケーションのサポートは終了することになりました。サポート終了は次の 2 段階で行われます。
1. 2025 年 10 月 15 日以降、新しい Kinesis Data Analytics for SQL アプリケーションを作成することはできなくなります。
2. 2026 年 1 月 27 日以降、アプリケーションは削除されます。Amazon Kinesis Data Analytics for SQL アプリケーションを起動することも操作することもできなくなります。これ以降、Amazon Kinesis Data Analytics for SQL のサポートは終了します。詳細については、「Amazon Kinesis Data Analytics for SQL アプリケーションのサポート終了」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
スキーマエディタの使用
Amazon Kinesis Data Analytics アプリケーションの入力ストリームのスキーマでは、ストリームのデータをアプリケーションの SQL クエリで利用できるようにする方法が定義されています。
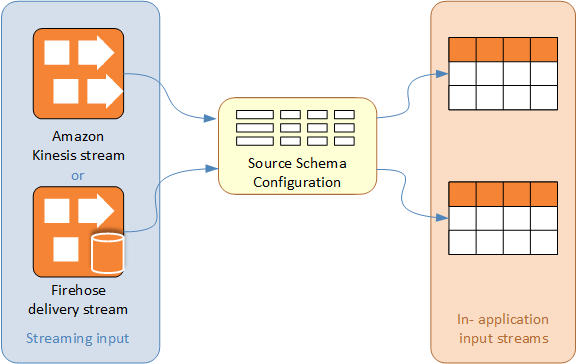
このスキーマには、アプリケーション内入力ストリームのデータ列に変換されるストリーミング入力の部分を判断する選択条件が含まれます。この入力には、次のいずれかの値を指定できます。
JSON 入力ストリームの JSONPath 式。JSONPath は、JSON データに対してクエリを実行するためのツールです。
カンマ区切り値 (CSV) 形式の入力ストリームの列番号。
アプリケーション内データストリームのデータを提供する列名と SQL データ型。このデータ型にも、文字データまたはバイナリデータ長が含まれています。
コンソールは、「DiscoverInputSchema」を使用してスキーマを生成しようとします。スキーマの検出に失敗した場合や、不適切または未完了のスキーマが返る場合、スキーマエディタを使用して、手動でスキーマを編集する必要があります。
スキーマエディタのメイン画面
次のスクリーンショットは、スキーマエディタのメイン画面です。
![[Edit schema] ページのスクリーンショット。](images/edit-schema-overview.png)
次の編集をスキーマに適用することができます。
列の追加 (1): データ項目が自動的に検出されない場合は、データ列を追加する必要がある場合があります。
列の削除 (2): アプリケーションで不要な場合は、ソースストリームからデータを除外することができます。除外によって、ソースストリームのデータに影響を及ぼすことはありません。除外されたデータは、アプリケーションで利用できません。
列名 (3) の変更 列名は空白にすることはできません。必ず 2 文字以上にし、予約された SQL キーワードを含めることはできません。SQL の通常の識別子の命名基準を満たす必要があります。名前は必ず文字で開始し、文字、アンダースコア文字、数字のみ含めることができます。
列のデータ型 (4) または長さ (5) の変更: 列に対して、互換性のあるデータ型を指定することができます。互換性のないデータ型を指定した場合、その列には NULL が入力されるか、アプリケーション内ストリームは追加されません。後者の場合は、エラーがエラーストリームに書き込まれます。指定する列の長さが小さすぎると、受信データは切り捨てられます。
列の選択条件の変更 (6): 列のデータのソースを判断するために使用される JSONPath 式または CSV 列の順序を編集できます。JSON スキーマの選択条件を変更するには、行のパス式に新しい値を入力します。CSV スキーマでは、選択条件として列の順序が使用されます。CSV スキーマの選択条件を変更するには、列の順序を変更します。
ストリーミングソースのスキーマの編集
ストリーミングソースのスキーマを編集する必要がある場合は、以下の手順を実行します。
ストリーミングソースのスキーマを編集するには
[Source] ページで、[Edit schema] を選択します。
![株式データを含むフォーマットされたストリームのサンプルタブのスクリーンショット。[Edit Schema] ボタンが強調表示されています。](images/edit-schema-1.png)
[Edit schema] ページで、ソーススキーマを編集します。
![[Edit schema] ページのスクリーンショット。](images/edit-schema-0.png)
[Format] で、[JSON] または [CSV] を選択します。JSON 形式または CSV 形式の場合、ISO 8859-1 エンコードがサポートされています。
JSON 形式または CSV 形式の詳細については、次のセクションの手順を参照してください。
JSON スキーマの編集
JSON スキーマは次のステップを使用して編集できます。
JSON スキーマを編集するには
スキーマエディタで、[Add column] を編集して列を追加します。
新しい列が最初の列の位置に表示されます。列の順序を変更するには、列名の横にある上向き矢印と下向き矢印を選択します。
新しい列に、以下の情報を入力します。
[Column name] に名前を入力します。
列名は空白にすることはできません。必ず 2 文字以上にし、予約された SQL キーワードを含めることはできません。SQL の通常の識別子の命名基準を満たす必要があります。名前は必ず文字で開始し、文字、アンダースコア文字、数字のみ含めることができます。
[Column type] に、SQL データ型を入力します。
列タイプは、サポートされている任意の SQL データ型です。新しいデータ型が CHAR、VARBINARY、VARCHAR のいずれかの場合は、[Length] にデータ長を指定します。詳細については、「データ型」を参照してください。
[Row path] に、列パスを指定します。行のパスは、JSON 要素にマッピングする有効な JSONPath 式です。
注記
基本の [Row path] 値は、最上位の親へのパスで、インポートされるデータを含みます。デフォルトでは、この値は [$] です。詳細については、「
JSONMappingParameters」のRecordRowPathを参照してください。
列を削除するには、列番号の横にある [x] アイコンを選択します。
列の名前を変更するには、[列名] に新しい名前を入力します。新しい列名は空白にすることはできません。必ず 2 文字以上にし、予約された SQL キーワードを含めることはできません。SQL の通常の識別子の命名基準を満たす必要があります。名前は必ず文字で開始し、文字、アンダースコア文字、数字のみ含めることができます。
-
列のデータ型を変更するには、[Column type] で新しいデータ型を選択します。新しいデータ型が
CHAR、VARBINARY、VARCHARのいずれかの場合は、[Length (長さ)] にデータ長を指定します。詳細については、「データ型」を参照してください。 -
[Save schema and update stream] を選択して変更を保存します。
変更後のスキーマが以下のようにエディタに表示されます。
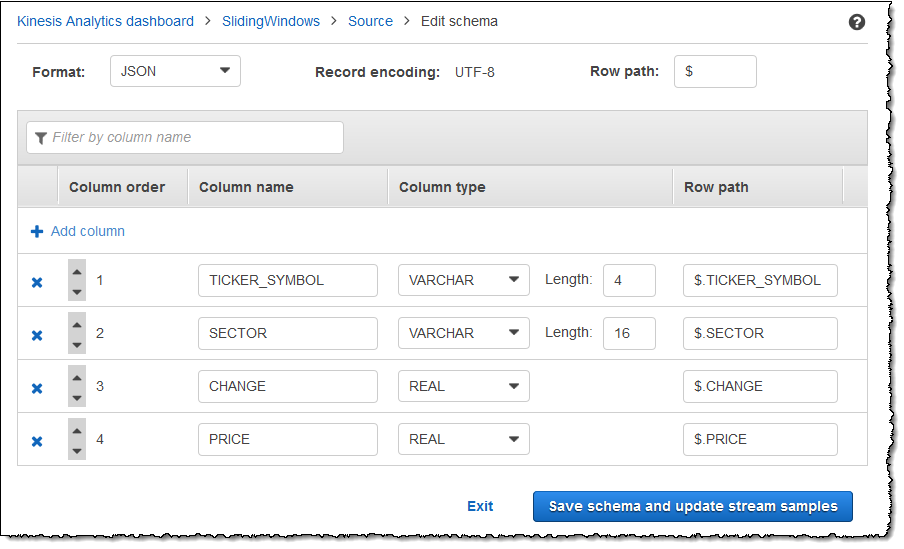
スキーマに行が多数ある場合は、[Filter by column name] を使用して行をフィルタリングすることができます。例えば、P から始まる列 (例: Price 列) の名前を編集するには、[列名によるフィルタリング] ボックスに P と入力します。
CSV スキーマの編集
CSV スキーマは次のステップを使用して編集できます。
CSV スキーマを編集するには
スキーマエディタで、[Row delimiter] の受信データストリームで使用されている区切り記号を選択します。つまり、ストリーム内のデータレコード間の区切り記号 (例: 改行文字) です。
[Column delimiter] で、受信データストリームで使用されている区切り記号を選択します。つまり、ストリーム内のデータフィールド間の区切り記号 (例: カンマ) です。
列を追加するには、[Add column] を選択します。
新しい列が最初の列の位置に表示されます。列の順序を変更するには、列名の横にある上向き矢印と下向き矢印を選択します。
新しい列に、以下の情報を入力します。
[Column name] に名前を入力します。
列名は空白にすることはできません。必ず 2 文字以上にし、予約された SQL キーワードを含めることはできません。SQL の通常の識別子の命名基準を満たす必要があります。名前は必ず文字で開始し、文字、アンダースコア文字、数字のみ含めることができます。
[Column type] に、SQL データ型を入力します。
列タイプは、サポートされている任意の SQL データ型です。新しいデータ型が CHAR、VARBINARY、VARCHAR のいずれかの場合は、[Length] にデータ長を指定します。詳細については、「データ型」を参照してください。
列を削除するには、列番号の横にある [x] アイコンを選択します。
列の名前を変更するには、[Column name] に新しい名前を入力します。新しい列名は空白にすることはできません。必ず 2 文字以上にし、予約された SQL キーワードを含めることはできません。SQL の通常の識別子の命名基準を満たす必要があります。名前は必ず文字で開始し、文字、アンダースコア文字、数字のみ含めることができます。
-
列のデータ型を変更するには、[Column type] で新しいデータ型を選択します。新しいデータ型が CHAR、VARBINARY、VARCHAR のいずれかの場合は、[Length] にデータ長を指定します。詳細については、「データ型」を参照してください。
-
[Save schema and update stream] を選択して変更を保存します。
変更後のスキーマが以下のようにエディタに表示されます。
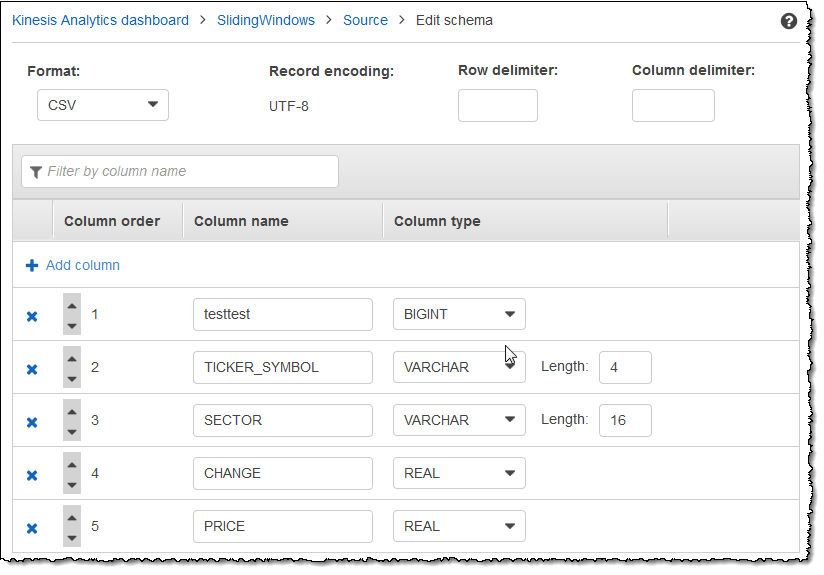
スキーマに行が多数ある場合は、[Filter by column name] を使用して行をフィルタリングすることができます。例えば、P から始まる列 (例: Price 列) の名前を編集するには、[列名によるフィルタリング] ボックスに P と入力します。
