慎重な検討の結果、Amazon Kinesis Data Analytics for SQL アプリケーションのサポートは終了することになりました。サポート終了は次の 2 段階で行われます。
1. 2025 年 10 月 15 日以降、新しい Kinesis Data Analytics for SQL アプリケーションを作成することはできなくなります。
2. 2026 年 1 月 27 日以降、アプリケーションは削除されます。Amazon Kinesis Data Analytics for SQL アプリケーションを起動することも操作することもできなくなります。これ以降、Amazon Kinesis Data Analytics for SQL のサポートは終了します。詳細については、「Amazon Kinesis Data Analytics for SQL アプリケーションのサポート終了」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
例: 複数のフィールドへの文字列の分割 (VARIABLE_COLUMN_LOG_PARSE 関数)
この例では、VARIABLE_COLUMN_LOG_PARSE 関数を使用して Kinesis Data Analytics の文字列を操作します。VARIABLE_COLUMN_LOG_PARSE は、入力文字列を、区切り文字または区切り文字列で区切られたフィールドに分割します。詳細については、「Amazon Managed Service for Apache Flink SQL リファレンス」の「VARIABLE_COLUMN_LOG_PARSE」を参照してください。
この例では、Amazon Kinesis データストリームに半構造化レコードを作成します。レコード例は次のとおりです。
{ "Col_A" : "string", "Col_B" : "string", "Col_C" : "string", "Col_D_Unstructured" : "value,value,value,value"} { "Col_A" : "string", "Col_B" : "string", "Col_C" : "string", "Col_D_Unstructured" : "value,value,value,value"}
次に、Kinesis ストリームをストリーミングソースとして使用して、コンソールで Kinesis Data Analytics アプリケーションを作成します。検出プロセスでストリーミングソースのサンプルレコードが読み込まれ、次のように、アプリケーション内スキーマの列が 4 つであると推察します。
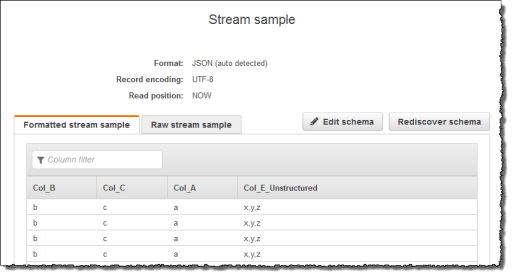
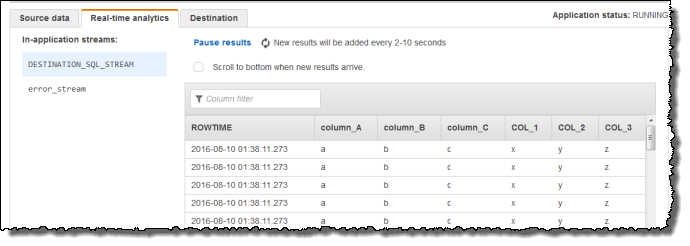
次に、VARIABLE_COLUMN_LOG_PARSE 関数を持つアプリケーションコードを使用してカンマ区切り値を解析し、次のように正規化行をアプリケーション内ストリームに挿入します。
ステップ 1: Kinesis データストリームを作成する
次のように、Amazon Kinesis データストリームを作成して、ログレコードを追加します。
にサインイン AWS Management Console し、https://console.aws.amazon.com/kinesis
で Kinesis コンソールを開きます。 -
ナビゲーションペインで、[データストリーム] を選択します。
-
[Kinesis ストリームの作成] を選択し、1 つのシャードがあるストリームを作成します。詳細については、「Amazon Kinesis Data Streams デベロッパーガイド」の「Create a Stream」を参照してください。
-
サンプルログレコードを入力するには、以下の Python コードを実行します。このシンプルなコードは、同じログレコードを連続してストリームに書き込みます。
import json import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return {"Col_A": "a", "Col_B": "b", "Col_C": "c", "Col_E_Unstructured": "x,y,z"} def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
ステップ 2: Kinesis Data Analytics アプリケーションを作成する
次のように Kinesis Data Analytics アプリケーションを作成します。
https://console.aws.amazon.com/kinesisanalytics
にある Managed Service for Apache Flink コンソールを開きます。 -
[アプリケーションの作成] を選択し、アプリケーション名を入力して、[アプリケーションの作成] を選択します。
-
アプリケーション詳細ページで、[ストリーミングデータの接続] を選択します。
-
[ソースに接続] ページで、以下の操作を実行します。
-
前のセクションで作成したストリームを選択します。
-
IAM ロールを作成するオプションを選択します。
-
[スキーマの検出] を選択します。作成されたアプリケーション内ストリーム用の推測スキーマと、推測に使用されたサンプルレコードがコンソールに表示されるまで待ちます。推測スキーマの列は 1 つのみであることに注意してください。
-
[Save and continue] を選択します。
-
-
アプリケーション詳細ページで、[SQL エディタに移動] を選択します。アプリケーションを起動するには、表示されたダイアログボックスで [はい、アプリケーションを起動します] を選択します。
-
SQL エディタで、アプリケーションコードを作成してその結果を確認します。
-
次のアプリケーションコードをコピーしてエディタに貼り付けます。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM"( "column_A" VARCHAR(16), "column_B" VARCHAR(16), "column_C" VARCHAR(16), "COL_1" VARCHAR(16), "COL_2" VARCHAR(16), "COL_3" VARCHAR(16)); CREATE OR REPLACE PUMP "SECOND_STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM t."Col_A", t."Col_B", t."Col_C", t.r."COL_1", t.r."COL_2", t.r."COL_3" FROM (SELECT STREAM "Col_A", "Col_B", "Col_C", VARIABLE_COLUMN_LOG_PARSE ("Col_E_Unstructured", 'COL_1 TYPE VARCHAR(16), COL_2 TYPE VARCHAR(16), COL_3 TYPE VARCHAR(16)', ',') AS r FROM "SOURCE_SQL_STREAM_001") as t; -
[Save and run SQL] を選択します。[リアルタイム分析] タブに、アプリケーションで作成されたすべてのアプリケーション内ストリームが表示され、データを検証できます。
-
