翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
での Amazon S3 Tables カタログの作成 AWS Glue Data Catalog
Amazon S3 Tables は、分析ワークロード用に特別に最適化された S3 ストレージを提供し、クエリのパフォーマンスを向上させながらコストを削減します。S3 Tables のデータは、新しいバケットタイプ、つまりテーブルをサブリソースとして保存するテーブルバケットに保存されます。S3 テーブルには Apache Iceberg 標準のサポートが組み込まれているため、Apache Spark などの一般的なクエリエンジンを使用して、Amazon S3 テーブルバケット内の表形式データに簡単にクエリを実行できます。
Amazon S3 テーブルバケットとテーブルを AWS Glue Data Catalog (データカタログ) と統合し、Lake Formation コンソールまたはサービス APIs を使用して、カタログを Lake Formation データの場所として登録できます。組織がデータカタログ内のデータを管理し、データの場所を Lake Formation に登録するときは、Lake Formation を使用してデータセットへのアクセスを制御できます。
タグベースのアクセスコントロールと名前付きリソースメソッドを使用して Lake Formation アクセス許可をフェデレーティッドデータベースに適用し、複数の Organizations AWS アカウント AWS および組織単位 (OUs) 間で共有できます。また、フェデレーションデータベースを別のアカウントの IAM プリンシパルと直接共有することもできます。
詳細については、「Amazon Simple Storage Service ユーザーガイド」の「分析サービスでの Amazon S3 AWSTables の使用」を参照してください。
トピック
Data Catalog と Lake Formation の統合の仕組み
S3 テーブルカタログを Data Catalog および Lake Formation と統合すると、 AWS Glue サービスによって、アカウントに固有のデフォルトの Data Catalog s3tablescatalogに という名前の単一のフェデレーティッドカタログが作成されます AWS リージョン。統合は、アカウントとフェデレーティッドカタログ内のすべての Amazon S3 テーブルバケットリソース AWS リージョン を次の方法でマッピングします。
Amazon S3 テーブルバケットは、データカタログのマルチレベルカタログになります。
-
関連付けられた Amazon S3 名前空間は、データカタログにデータベースとして登録されます。
-
テーブルバケット内の Amazon S3 テーブルは、データカタログ内のテーブルになります。
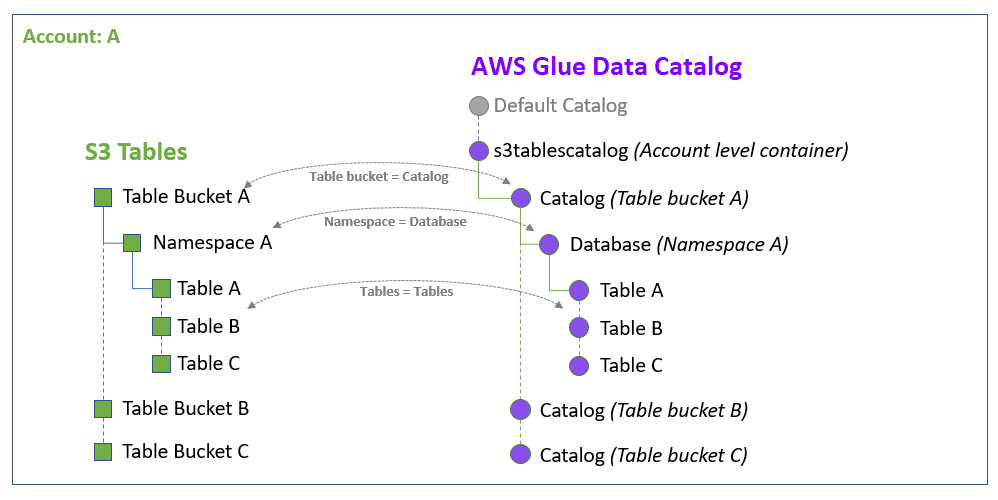
Lake Formation と統合した後、テーブルバケットカタログに Apache Iceberg テーブルを作成し、 Amazon Athena Amazon EMR やサードパーティー AWS の分析エンジンなどの統合分析エンジンを介してアクセスできます。
