翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Blu Age ブルーサム
メインフレームシステム (以降のトピックでは「レガシー」と呼びます) では、ビジネスデータは VSAM (仮想ストレージアクセス方法) を使用して保存されることがよくあります。データは "データセット" に含まれる "レコード" (バイト配列) に保存されます。
データセット組織には次の 4 つがあります。
-
KSDS: キーシーケンスデータセット - レコードはプライマリキー (重複キーは許可されません) と、オプションで追加される "代替" キーによってインデックス化されます。すべてのキー値はレコードバイト配列のサブセットであり、各キーは以下によって定義されます:
-
オフセット (0 ベース、0 はレコードバイト配列のコンテンツの先頭、バイト単位で測定)
-
長さ (バイト単位で表される)
-
重複する値を許容するかどうか
-
-
ESDS: エントリシーケンスデータセット - レコードは多くの場合、順番どおりに (データセットに挿入された順番で) アクセスされますが、追加の代替キーを使用してアクセスされる場合もあります。
-
RRDS: 相対レコードデータセット - レコードは相対レコード番号を使用した "ジャンプ" を使用してアクセスされます。ジャンプは前方向にも、後方向にも行われます。
-
LDS: 線形データセット - レコードは存在せず、単にバイトのストリームであり、ページに編成されます。主にレガシープラットフォームの内部目的で使用されます。
AWS Blu Age リファクタリングアプローチを使用してレガシーアプリケーションをモダナイズする場合、モダナイズされたアプリケーションは、データアクセスロジックを維持しながら VSAM ストアドデータにアクセスすることを意図しなくなりました。Blusam コンポーネントが答えです。レガシー VSAM データセットのエクスポートからデータをインポートでき、モダナイズされたアプリケーションが専用の管理ウェブアプリケーションとともに操作するための API を提供します。「AWS Blu Age Blusam管理コンソール」を参照してください。
注記
Blusam は KSDS、ESDS、RRDS のみをサポートします。
Blusam API を使用すると、データアクセスロジック (シーケンシャル、ランダム、相対読み取り、レコードの挿入、更新、削除) を保持できます。一方、コンポーネントアーキテクチャは、キャッシュ戦略と RDBMS ベースのストレージの組み合わせに依存するため、限られたリソースで高スループットの I/O オペレーションが可能になります。
Blusam インフラストラクチャ
Blusam は、未加工レコードデータとキーインデックス (該当する場合) の両方について、データセットストレージの PostgreSQL RDBMS に依存します。お気に入りのオプションは、Amazon Aurora PostgreSQL 互換エンジンを使用することです。このトピックで示す例および図は、このエンジンを使用した場合のものです。
注記
サーバーの起動時に、Blusamランタイムは必須のテクニカルテーブルがあることを確認し、見つからない場合は作成します。その結果、Blusamデータベースにアクセスするために設定で使用されるロールには、データベーステーブル (行とテーブル定義の両方) を作成、更新、削除する権限が付与される必要があります。を無効にする方法についてはBlusam、「」を参照してくださいBlusam の設定。
キャッシュ
ストレージ自体に加えて、 はキャッシュ実装と組み合わせるとより高速にBlusam動作します。
現在、EhCache と Redis の 2 つのキャッシュエンジンがサポートされており、それぞれのユースケースは次のように異なります:
-
EhCache: スタンドアロンの揮発性埋め込みローカルキャッシュ
-
AWS Mainframe Modernization マネージド環境デプロイの対象外です。
-
通常、単体の Apache Tomcat サーバーなど、ノードが単一である場合に、モダナイズされたアプリケーションを実行するために使用されます。例えば、バッチジョブタスクのホスティングのみを行うノードに使用します。
-
揮発性: EhCache キャッシュインスタンスは揮発性であり、サーバーのシャットダウン時にコンテンツが消失します。
-
埋め込み: EhCache とサーバーが同じ JVM メモリスペースを共有します (ホスティングマシンの仕様を定義する際にこれを考慮する必要があります)。
-
-
Redis: 共有永続キャッシュ
-
AWS Mainframe Modernization マネージド環境のデプロイの対象となります。
-
多くの場合、とりわけ複数のサーバーがロードバランサーで管理されるようなマルチノードで使用されます。キャッシュコンテンツはすべてのノード間で共有されます。
-
Redis は永続的であり、ノードのライフサイクルに依存しません。独自の専用マシンまたはサービス (Amazon ElastiCache など) で実行されます。キャッシュはすべてのノードからリモートに配置されます。
-
ロック
データセットとレコードへの同時アクセスを処理するために、 Blusamは設定可能なロックシステムに依存します。ロックは、データセットとレコードのレベルで適用されます:
-
書き込みの目的でデータセットをロックする場合、他のすべてのクライアントは、すべてのレベル (データセットまたはレコード) でそのデータセットへの書き込みを実行できなくなります。
-
書き込みの目的でレコードをロックする場合、他のクライアントは、特定のレコードに対してのみ書き込みを実行できなくなります。
Blusam ロックシステムの設定は、キャッシュ設定に応じて行う必要があります。
-
EhCache を選択してキャッシュを実装する場合は、デフォルトのインメモリロックシステムが使用されるため、ロックをそれ以上設定する必要はありません。
-
Redis を選択してキャッシュを実装する場合は、複数のノードからの同時アクセスを可能にするために、Redis ベースでロックを設定する必要があります。ロックに使用する Redis キャッシュが、データセットに使用するものと同じである必要はありません。Redis ベースのロックシステムの設定については、「Blusam の設定」を参照してください。
Blusam 組み込みとレガシーからのデータ移行
データセットの保存: レコードとインデックス
各レガシーデータセットBlusamは、 にインポートされると専用テーブルに保存されます。テーブルの各行は 2 つの列を使用してレコードを表します。
-
数値 ID 列、整数型、テーブルのプライマリキー。レコードの相対バイトアドレス (RBA) が保存されます。RBA はデータセットの先頭からのオフセットをバイト単位で表し、0 で始まります。
-
バイト配列のレコード列。未加工レコードの内容が格納されます。
CardDemo アプリケーションで使用される KSDS データセットの内容の例を次に示します:
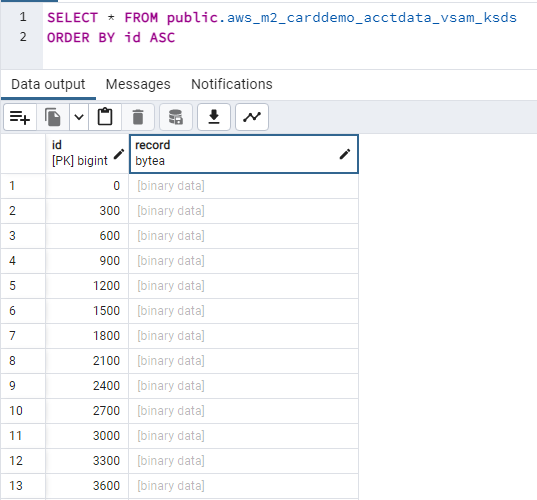
-
このデータセットには長さが 300 バイトの固定長レコードが格納されます (したがって、ID を集めると 300 の倍数になります)。
-
デフォルトでは、PostgreSQL データベースのクエリに使用される pgAdmin ツールにはバイト配列列の内容は表示されませんが、代わりに [バイナリデータ] ラベルが出力されます。
-
未加工レコードの内容は、レガシーからエクスポートされた未加工データセットと同じであり、変換されていません。つまり、文字セットの変換が行われません。そのため、レコードの英数字部分を、モダナイズされたアプリケーションで、レガシーの文字セット (ほとんどの場合は EBCDIC バリアント) を使用してデコードする必要があります。
データセットのメタデータとキーインデックスについて: 各データセットは、metadata という名前のテーブルの 2 つの行に関連付けられます。これはデフォルトの命名規則です。カスタマイズ方法については、「Blusam の設定」を参照してください。

-
最初の行では、データセット名の値が name 列に表示されています。metadata 列はバイナリ列です。このデータセットの汎用メタデータのバイナリシリアル化データが格納されます。詳細については、「データセットのメタデータの一般的な属性」を参照してください。
-
2 行目では、データセット名に
__internal'というサフィックスを付けた値が name 列に表示されています。metadata 列のバイナリコンテンツは、データセットの "重量" によって異なります。-
小または中規模のデータセットの場合、コンテンツは次を圧縮したシリアル化データになります:
-
データセットで使用するキーの定義。つまり、プライマリキー定義 (KSDS)、および該当する場合は代替キー定義 (KSDS/ESDS)
-
該当する場合はキーインデックス (KSDS/ESDS、代替キー定義あり): レコードのインデックス付きブラウジングに使用。キーインデックスにより、キー値がレコードの RBA にマッピングされる
-
レコード長マップ: レコードのシーケンシャルまたは相対ブラウジングに使用される
-
-
大規模または超大規模のデータセットの場合、コンテンツは次を圧縮したシリアル化データになります:
-
データセットで使用するキーの定義。つまり、プライマリキー定義 (KSDS)、および該当する場合は代替キー定義 (KSDS/ESDS)
-
-
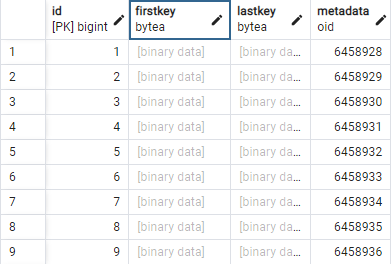
また、大規模または超大規模のデータセットインデックス (該当する場合) は、ページ分割メカニズムを使用して保存され、インデックスページのバイナリシリアル化データが専用テーブル (データセットキーごとに 1 つのテーブル) の行に保存されます。インデックスの各ページは、次の列を持つ行に保存されます。
-
id: インデックスページの技術識別子 (数値プライマリキー)
-
firstkey: インデックスページに保存されている最初の (最小) キー値のバイナリ値
-
lastkey: インデックスページに保存されている最後の (最大) キー値のバイナリ値
-
metadata: インデックスページのバイナリ圧縮シリアル化データ (キー値をレコードの RBA にマッピング)。
テーブル名は、データセット名とキー内部名をつないで作成されます。この名前には、キーのオフセット、キーが重複を許可するかどうか (許可する場合は true に設定)、キーの長さなど、キーに関する情報が含まれます。例えば、"AWS_LARGE_KSDS" という名前のデータセットに次の 2 つのキーが定義されているとします:
-
プライマリキー [オフセット: 0、重複: false、長さ: 18]
-
代替キー [オフセット: 3、重複: true、長さ: 6]
この場合、2 つのキーに関連するインデックスが次のテーブルに保存されます。

ライトビハインドメカニズムを使用した I/O スループットの最適化
挿入/更新/削除オペレーションのパフォーマンスを最適化するために、Blusamエンジンは設定可能な書き込みビハインドメカニズムに依存します。このメカニズムは、一括更新クエリを使用して永続化オペレーションを処理する専用スレッドのプール上に構築され、Blusamストレージへの I/O スループットを最大化します。
Blusam エンジンは、アプリケーションによってレコードに対して実行されるすべての更新オペレーションを収集し、処理のためにディスパッチされるレコードのロットを専用スレッドにビルドします。その後、一括更新クエリを使用して、ロットがBlusamストレージに保持され、アトミック永続化オペレーションの使用が回避され、ネットワーク帯域幅の最適な使用が保証されます。
このメカニズムで、遅延 (デフォルトは 1 秒) とロットサイズ (デフォルトは 10,000 レコード) を設定することができます。永続性クエリは、次の 2 つの条件のうちいずれかの条件が満たされるとすぐに作成されます。
-
設定された遅延が経過し、かつロットが空ではない
-
処理するロット内のレコード数が設定された制限に達している
ライトビハインドメカニズムの設定方法については、「オプションプロパティ」を参照してください。
適切なストレージスキームの選択
前のセクションで説明したように、データセットの保存方法は "重量" に合わせて選択します。しかし、何を基準にデータセットの小、中、大を判断するのでしょうか? ストレージをページ分割する方法はどのような場合に選択するのでしょうか?
これらは次に応じて判断します。
-
データセットを使用するモダナイズされたアプリケーションをホストする各サーバーで使用可能なメモリの量。
-
キャッシュインフラストラクチャで使用可能なメモリの量 (存在する場合)。
非ページ分割のインデックスストレージスキームを使用する場合、すべてのキーインデックスとレコードを集めたサイズが、データセットをオープンするときに、サーバーのメモリに毎回読み込まれます。また、キャッシュを処理する場合は、すべてのデータセットレコードが通常の方法でキャッシュに事前に読み込まれるため、キャッシュのインフラストラクチャ側のメモリリソースが枯渇する可能性があります。
消費されるメモリの量を、定義したキーの数、キー値の長さ、レコードの数、同時にアクセスするデータセットの数、そしてユースケースごとの知識を考慮しながら、おおまかに評価しておくとよいでしょう。
詳細についてはデータセットのメモリフットプリントの見積りを参照してください。
Blusam 移行
特定のデータセットに対して適切なストレージスキームを選択したら、レガシーデータセットを移行してBlusamストレージに入力する必要があります。
そのためにレガシーデータセットの未加工バイナリをエクスポートしますが、これは文字セットを変換せずに行います。レガシーシステムからデータセットエクスポートを転送する際に、バイナリ形式が破損しないよう注意してください。例えば、FTP を使用する場合はバイナリモードを使用してください。
レコードのみを未加工バイナリ形式でエクスポートしてください。このインポートメカニズムでは、キーやインデックスをエクスポートする必要がありません。キーやインデックスはすべて、インポートメカニズムによってオンザフライで再計算されます。
データセットのバイナリエクスポートが利用可能になると、そのバイナリエクスポートBlusamを既存の に移行するためのいくつかのオプションがあります。
AWS Mainframe Modernization マネージド環境の場合:
-
データセットのインポートだけを実行する機能を使用します。「AWS Mainframe Modernization アプリケーションのデータセットをインポートする」を参照してください。
or
-
データセットを一括でインポートする機能を使用します。「AWS Mainframe Modernization データセット定義リファレンス」および「VSAM のデータセットリクエストフォーマットの例」を参照してください。
or
-
groovy スクリプトを使用し、専用の読み込みサービスを使用してデータセットをインポートします。
注記
Mainframe Modernization により管理される環境に LargeKSDS と LargeESDS をインポートできるのは、現時点では groovy スクリプトを使用する場合のみです。
Amazon EC2 の AWS Blu Age ランタイムの場合:
-
を使用してデータセットをインポートしますAWS Blu Age Blusam管理コンソール。
or
-
groovy スクリプトを使用し、専用の読み込みサービスを使用してデータセットをインポートします。
Groovy スクリプトを使用してデータセットをインポートする
このセクションでは、groovy スクリプトを作成してレガシーデータセットを にインポートする方法について説明しますBlusam。
最初にいくつかインポートする必要があります。
import com.netfective.bluage.gapwalk.bluesam.BluesamManager import com.netfective.bluage.gapwalk.bluesam.metadata.Key; import com.netfective.bluage.gapwalk.rt.provider.ServiceRegistry import java.util.ArrayList; //used for alternate keys if any
その後、インポートするデータセットごとに、次のパターンでコードを作成します。
-
マップオブジェクトを作成または消去する
-
マップに必須のプロパティを入力する (データセットの種類によって異なります -- 詳しくは以下を参照してください)
-
データセットの種類に応じて正しい読み込みサービスを取得し、サービスレジストリで使用する
-
マップを引数として使用してサービスを実行する
次の 5 つのサービス実装を、下記の識別子を使用して取得できます:
-
"BluesamKSDSFileLoader": 小/中規模の KSDS の場合 -
"BluesamESDSFileLoader": 小/中規模の ESDS の場合 -
"BluesamRRDSFileLoader": RRDS の場合 -
"BluesamLargeKSDSFileLoader": 大規模な KSDS の場合 -
"BluesamLargeESDSFileLoader": 大規模な ESDS の場合
KSDS または ESDS に標準と大規模のどちらのバージョンのサービスを選択するかは、データセットのサイズや、適用するストレージ方法によって異なります。ストレージ方法を適切に選択する方法については、「適切なストレージスキームの選択」を参照してください。
データセットを に正常にインポートするにはBlusam、ロードサービスに適切なプロパティを指定する必要があります。
一般的なプロパティ:
-
必須 (全種類のデータセットに必要)
-
"bluesamManager":
applicationContext.getBean(BluesamManager.class)を指定します -
"datasetName": データセットの名前を文字列で指定します
-
"inFilePath": レガシーデータセットのエクスポート先のパスを文字列で指定します
-
"recordLength": 固定レコード長を整数で指定します (可変レコード長データセットの場合は 0)
-
-
オプションです。
-
大規模なデータセットではサポートされない:
-
isAppend」: インポートが追加モード (既存のBlusamデータセットにレコードを追加する) で発生していることを示すブールフラグ。
-
"useCompression": メタデータを圧縮して保存することを示すブール型のフラグ。
-
-
大規模なデータセットのみサポート:
-
"indexingPageSizeInMb": データセットの各キーのインデックスページのサイズ (メガバイト) を厳密な正の整数で指定します
-
-
データセットの種類に依存するプロパティ:
-
KSDS/大規模な KSDS:
-
必須
-
"primaryKey": プライマリキー定義。
com.netfective.bluage.gapwalk.bluesam.metadata.Keyコンストラクタ呼び出しを使用します。
-
-
オプション:
-
"alternateKeys": 代替キー定義のリスト (
java.util.List)。com.netfective.bluage.gapwalk.bluesam.metadata.Keyコンストラクタ呼び出しを使用して作成します。
-
-
-
ESDS/大規模な ESDS:
-
オプション:
-
"alternateKeys": 代替キー定義のリスト (
java.util.List)。com.netfective.bluage.gapwalk.bluesam.metadata.Keyコンストラクタ呼び出しを使用して作成します。
-
-
-
RRDS:
-
なし。
-
キーコンストラクタ呼び出し:
-
new Key(int offset, int length): キーの属性 (オフセットと長さ) を指定してキーオブジェクトを作成します。重複は許可されません。このバリアントが、プライマリキーの定義に使用されます。 -
new Key(boolean allowDuplicates, int offset, int length): キーの属性 (オフセットと長さ) と重複を許可するかどうかのフラグを指定してキーオブジェクトを作成します。
以下に、データ読み込みのさまざまなシナリオを示す Groovy サンプルを紹介します。
2 つの代替キーを使用した大規模な KSDS の読み込み:
import com.netfective.bluage.gapwalk.bluesam.BluesamManager import com.netfective.bluage.gapwalk.bluesam.metadata.Key; import com.netfective.bluage.gapwalk.rt.provider.ServiceRegistry import java.util.ArrayList; // Loading a large KSDS into Blusam def map = [:] map.put("bluesamManager", applicationContext.getBean(BluesamManager.class)); map.put("datasetName", "largeKsdsSample"); map.put("inFilePath", "/work/samples/largeKsdsSampleExport"); map.put("recordLength", 49); map.put("primaryKey", new Key(0, 18)); ArrayList altKeys = [new Key(true, 10, 8), new Key(false, 0, 9)] map.put("alternateKeys", altKeys); map.put("indexingPageSizeInMb", 25); def service = ServiceRegistry.getService("BluesamLargeKSDSFileLoader"); service.runService(map);
代替キーを使用しない可変レコード長の ESDS の読み込み:
import com.netfective.bluage.gapwalk.bluesam.BluesamManager import com.netfective.bluage.gapwalk.bluesam.metadata.Key; import com.netfective.bluage.gapwalk.rt.provider.ServiceRegistry // Loading an ESDS into Blusam def map = [:] map.put("bluesamManager", applicationContext.getBean(BluesamManager.class)); map.put("datasetName", "esdsSample"); map.put("inFilePath", "/work/samples/esdsSampleExport"); map.put("recordLength", 0); def service = ServiceRegistry.getService("BluesamESDSFileLoader"); service.runService(map);
可変レコード長のデータセットをエクスポートする場合は、読み取り時にレコードを分割できるように、Record Decriptor Word (RDW) 情報を含める必要があります。
固定レコード長の RRDS の読み込み:
import com.netfective.bluage.gapwalk.bluesam.BluesamManager import com.netfective.bluage.gapwalk.bluesam.metadata.Key; import com.netfective.bluage.gapwalk.rt.provider.ServiceRegistry // Loading a RRDS into Blusam def map = [:] map.put("bluesamManager", applicationContext.getBean(BluesamManager.class)); map.put("datasetName", "rrdsSample"); map.put("inFilePath", "/work/samples/rrdsSampleExport"); map.put("recordLength", 180); def service = ServiceRegistry.getService("BluesamRRDSFileLoader"); service.runService(map);
マルチスキーマモードでのデータセットのロード:
マルチスキーマモード: 一部のレガシーシステムでは、VSAM ファイルはファイルセットに整理されているため、プログラムは指定されたパーティション内のデータにアクセスして変更することができます。最新のシステムでは、各ファイルセットがスキーマとして扱われ、同様のデータパーティショニングとアクセスコントロールが可能になります。
application-main.yml ファイルでマルチスキーマモードを有効にするには、「」を参照してくださいBlusam の設定。このモードでは、ランタイム情報のインメモリレジストリである共有コンテキストを使用して、データセットを特定のスキーマにロードできます。データセットを特定のスキーマにロードするには、データセット名の前に関連するスキーマ名を付けます。
マルチスキーマモードの特定のスキーマに KSDS ファイルをロードする:
import com.netfective.bluage.gapwalk.bluesam.BluesamManager import com.netfective.bluage.gapwalk.bluesam.metadata.Key; import com.netfective.bluage.gapwalk.rt.provider.ServiceRegistry import java.util.ArrayList; import com.netfective.bluage.gapwalk.rt.shared.SharedContext; // Loading a KSDS into Blusam def map = [:] String schema = "schema1"; String datasetName = schema+"|"+"ksdsSample"; SharedContext.get().setCurrentBlusamSchema(schema); schema = SharedContext.get().getCurrentBlusamSchema(); map.put("bluesamManager", applicationContext.getBean(BluesamManager.class)); map.put("datasetName", datasetName); map.put("inFilePath", "/work/samples/ksdsSampleExport"); map.put("recordLength", 49); map.put("primaryKey", new Key(0, 18)); map.put("indexingPageSizeInMb", 25); def service = ServiceRegistry.getService("BluesamKSDSFileLoader"); service.runService(map);
マルチスキーマモードの特定のスキーマにラージ KSDS ファイルをロードする:
import com.netfective.bluage.gapwalk.bluesam.BluesamManager import com.netfective.bluage.gapwalk.bluesam.metadata.Key; import com.netfective.bluage.gapwalk.rt.provider.ServiceRegistry import java.util.ArrayList; import com.netfective.bluage.gapwalk.rt.shared.SharedContext; // Loading a Large KSDS into Blusam def map = [:] String schema = "schema1"; String datasetName = schema+"|"+"largeKsdsSample"; SharedContext.get().setCurrentBlusamSchema(schema); schema = SharedContext.get().getCurrentBlusamSchema(); map.put("bluesamManager", applicationContext.getBean(BluesamManager.class)); map.put("datasetName", datasetName); map.put("inFilePath", "/work/samples/LargeKsdsSampleExport"); map.put("recordLength", 49); map.put("primaryKey", new Key(0, 18)); map.put("indexingPageSizeInMb", 25); def service = ServiceRegistry.getService("BluesamLargeKSDSFileLoader"); service.runService(map);
さらに、設定エントリ (application-main.yml設定ファイルで設定) を使用してインポートプロセスを微調整できます。
-
bluesam.fileLoading.commitInterval: 通常の ESDS/KSDS/RRDS インポートメカニズムのコミット間隔を、厳密な正の整数で定義します。大規模なデータセットのインポートには使用できません。デフォルトは 100,000 です。
Blusam の設定
設定は、application-main.yml設定ファイル (またはBlusam管理コンソール -- BAC -- アプリケーションのスタンドアロンデプロイ用のapplication-bac.yml設定ファイル) でBlusam行われます。
Blusam は、次の 2 つの側面で設定する必要があります。
-
Blusam ストレージとキャッシュアクセス設定
-
Blusam エンジン設定
Blusam ストレージとキャッシュアクセス設定
シークレットマネージャーまたはデータソースを使用してBlusamストレージとキャッシュへのアクセスを設定する方法については、「」を参照してくださいAWS Blu Age ランタイムの設定。
注記
Blusam ストレージへのアクセスに関して、使用される認証情報は、 権限に従って接続ロールを指します。Blusam エンジンが期待どおりに動作できるようにするには、接続ロールに次の権限が必要です。
-
データベースへの接続
-
テーブルとビューの作成/削除/変更/切り捨て
-
テーブルとビューでの行の選択/挿入/削除/更新
-
関数またはプロシージャの実行
Blusam エンジン設定
Blusam サポートを無効にする
まず、 bluesam.disabledプロパティを に設定することで、Blusamサポートを完全に無効にできることに注意してくださいtrue。アプリケーションの起動時に、Blusam無効化を通知する情報メッセージがサーバーログに表示されます。
BLUESAM is disabled. No operations allowed.
この場合、 に関する追加の設定Blusamは必要ありません。Blusam関連する機能 (プログラムまたは REST 呼び出し) を使用しようとすると、Java コード実行UnsupportedOperationExceptionで が生成され、 に関する関連する説明メッセージが無効Blusamになります。
Blusam エンジンプロパティ
Blusam エンジン設定プロパティは、bluesam キープレフィックスの下に再グループ化されます。
必須プロパティ
-
cache: 選択したキャッシュ実装の値を指定します。次の値を指定できます:-
ehcache: ローカルに埋め込みの Ehcache を使用する場合。前述のユースケースの制限を参照してください。 -
redis: 共有のリモート Redis キャッシュを使用する場合。これは Mainframe Modernization AWS マネージドユースケースで推奨されるオプションです。 -
none: ストレージキャッシュを無効にします
-
-
persistence: pgsql (PostgreSQL エンジン: 最小バージョン 10.0 – 推奨バージョン >=14.0 -
datasource reference:
<persistence engine>.dataSourceは、設定ファイルの他の場所で定義されているBlusamストレージへの接続の dataSource 定義を指します。一般にbluesamDsという名前が付けられます。
注記
Redis をデータまたはロックのキャッシュメカニズムとして使用する場合は (以下を参照)、Redis インスタンスへのアクセスを設定する必要があります。詳細については、「AWS Blu Age ランタイムで使用可能な Redis キャッシュプロパティ」を参照してください。
オプションプロパティ
Blusam ロック: プロパティにはプレフィックスが付きます locks
-
cache: 使用可能な値のみがredisで、redis ベースのロックメカニズムを使用することを指定します (Blusamストレージキャッシュが redis ベースの場合にも使用されます)。このプロパティが見つからないか、redis以外に設定されている場合は、デフォルトのインメモリロックメカニズムが使用されます。 -
lockTimeOut: 正の長整数値。既にロックされている要素をロックした場合にエラーが記録されるまでのタイムアウト値をミリ秒単位で指定します。デフォルトは500です。 -
locksDeadTime: アプリケーションがロックを保持できる時間の最大値 (ミリ秒単位) を、正の長整数値で指定します。この時間が経過すると、ロックは自動的に期限切れとして記録され、解除されます。デフォルトは1000です。 -
locksCheck: 期限切れのロックの削除について、現在のBlusamロックマネージャーで使用されるロックチェック戦略を定義するために使用される文字列。次の値の中から選択します:-
off: チェックは実行されません。デッドロックが発生する可能性があるため、推奨されません。 -
reboot: 再起動時またはアプリケーションの起動時にチェックが実行されます。その時点で、期限切れのロックがすべて解除されます。これがデフォルトです。 -
timeout: チェックは、再起動時またはアプリケーションの起動時、またはデータセットのロック試行中にタイムアウトになったときに実行されます。期限切れのロックは直ちに解除されます。
-
ライトビハインドメカニズム: 以下のプロパティには write-behind キーのプレフィックスが付きます。
-
enabled:true(デフォルトであり推奨値) またはfalse。ライトハインドメカニズムを有効または無効にします。無効にすると書き込みパフォーマンスが大きく低下するため、推奨されません。 -
maxDelay: トリガーされるスレッド期間の最大値。デフォルトは"1s"(1 秒) です。特定の条件によりこの値を調整する必要がある場合を除き、デフォルト値を使用することをお勧めします。いずれの場合でも、値は低く設定する必要があります (3 秒未満)。遅延の文字列を<integer value><optional whitespace><time unit>の形式で指定します。<time unit>には次の値のいずれかを選択してください。-
"ns": ナノ秒 -
"µs": マイクロ秒 -
"ms": ミリ秒 -
"s": 秒
-
-
threads: ライトビハインド専用スレッドの数。デフォルトは5です。この値は、Blusamエンジンを実行しているホストの計算能力に応じて調整する必要があります。この値を、ストレージの RDBMS 機能が多数のバッチクエリを同時に処理できることを期待して極度に高く設定しても、効果はありません。推奨値は通常 4~8 の範囲です。 -
batchSize: 一括処理がスレッドにディスパッチされるロット内のレコード数の最大値を、正の整数で指定します。1~32,767 の値にする必要があります。デフォルトは10000です。値に1を指定すると、アトミックな更新クエリの回避というメカニズムの目的が失われるため、少なくとも1000程度の値を指定してください。
埋め込み EhCache の微調整: 以下のプロパティには ehcache キーのプレフィックスが付きます:
-
resource-pool:-
size: 埋め込みキャッシュに割り当てるメモリサイズを文字列で指定します。デフォルトは"1024MB"(1 ギガバイト) です。Blusam エンジンをホストするマシンの使用可能なメモリと、アプリケーションで使用されているデータセットのサイズに関して調整します。サイズの文字列を<integer value><optional whitespace><memory unit>の形式で指定します。<memory-unit>には次の値のいずれかを選択してください。-
B: バイト -
KB: キロバイト -
MB: メガバイト -
GB: ギガバイト -
TB: テラバイト
-
-
heap: キャッシュが JVM ヒープメモリを消費するかどうかをtrueまたはfalseで指定します。デフォルトはtrueです (キャッシュのパフォーマンスは最速になりますが、キャッシュストレージが JVM オンヒープ RAM からメモリを消費します)。このプロパティをfalseに設定すると、メモリがオフヒープに切り替わり、JVM ヒープとの交換が必要になるため速度が低下します。
-
-
timeToLiveMillis: キャッシュエントリの有効期限が切れて削除される前にキャッシュに残る期間 (ミリ秒単位)。このプロパティを指定しない場合、キャッシュエントリはデフォルトで自動的に期限切れになりません。
マルチスキーマ設定プロパティ
-
multiSchema: false (デフォルト値) または true、 のマルチスキーマモードを無効または有効にする Blusam - バージョン 4.4.0 から使用可能。 -
pgsql:-
schemas: アプリケーションが のマルチスキーマモードで使用するスキーマ名のリストBlusam。 -
fallbackSchema: マルチスキーマモードで使用するフォールバックスキーマ名。現在のスキーマコンテキストでデータセットが見つからない場合、このスキーマはそのデータセットに対する Blusam関連のオペレーションに使用されます。
-
設定例:
dataSource: bluesamDs: driver-class-name: org.postgresql.Driver ... ... bluesam: locks: lockTimeOut: 700 cache: ehcache persistence: pgsql ehcache: resource-pool: size: 8GB write-behind: enabled: true threads: 8 batchsize: 5000 pgsql: dataSource : bluesamDs
サンプル設定スニペット ( でマルチスキーマモードが有効になっているBlusam):
dataSource: bluesamDs: driver-class-name: org.postgresql.Driver ... ... bluesam: locks: lockTimeOut: 700 cache: ehcache persistence: pgsql ehcache: resource-pool: size: 8GB write-behind: enabled: true threads: 8 batchsize: 5000 multiSchema: true pgsql: dataSource : bluesamDs schemas: - "schema1" - "schema2" - "schema3" fallbackSchema: schema3
注記
Blusam マルチスキーマモードの application-main.yml ファイルにリストされているスキーマを含むメタデータスキーマは、データベース内に存在せず、ユーザーが十分な権限を持っているBlusam場合に作成されます。
Blusam 管理コンソール
Blusam 管理コンソール (BAC) は、Blusamストレージの管理に使用されるウェブアプリケーションです。BAC の詳細については、「AWS Blu Age Blusam管理コンソール」を参照してください。
付録
データセットのメタデータの一般的な属性
データセットのメタデータの一般的なシリアル化属性リスト:
-
名前 (データセットの名前)
-
タイプ (KSDS、LargeKSDS、ESDS、LargeESDS、または RRDS)
-
キャッシュウォームアップフラグ (サーバーの起動時にデータセットをキャッシュに事前読み込みするかどうか)
-
圧縮使用フラグ (レコードを圧縮または未加工のどちらの形式で保存するか)
-
作成日
-
最終変更日
-
固定長レコードフラグ (データセットレコードをすべて同じ長さにするかどうか)
-
レコード長 -- 固定レコード長の場合にのみ使用
-
ページサイズ (必要に応じてキャッシュを事前読み込みする際に必要なページ分割 SQL クエリをカスタマイズするために使用)
-
サイズ (データセットのサイズ - レコードの累積長)
-
最後のオフセット (データセットに最後に追加されたレコードの RBA など)
-
次のオフセット (データセットに新しく追加したレコードに対し、次に使用可能なオフセット)
-
データセットに使用するキーの定義 (必要な場合)。各キーの種類 (プライマリキー、または代替キーの一部) に応じ、次の 3 つの属性を使用して定義します。
-
オフセット: レコード内でキー値の位置が開始されるバイトの値。
-
長さ: キー値の長さ (バイト単位)。したがって、キー値はレコードのサブセットであるバイト配列となり、位置は
key offsetで始まり、key offset + length - 1で終わります。 -
重複許可フラグ: キーが重複を許可するかどうかを指定します (true に設定すると許可されます)。
-
データセットのメモリフットプリントの見積り
小または中規模のデータセットの場合、メタデータ (さまざまなキーのサイズとインデックス) はメモリにすべて読み込まれます。モダナイズされたアプリケーションの実行に使用されるサーバーをホストするマシンに適切なリソースを割り当てるには、Blusam特にメタデータに関して、データセットによって誘発されるメモリ消費量を把握する必要があります。このセクションでは、その実践的な方法を説明します。
指定された式は、「大規模」ストレージ戦略を使用するのではなく、Blusam小規模から中規模のデータセットにのみ適用されます。
Blusam データセットメタデータ
Blusam データセットの場合、メタデータは 2 つの部分に分割されます。
-
コアメタデータ: データセットに関するグローバル情報を保持します。このメモリフットプリントは、内部メタデータと比較して無視できるほど小さなものです。
-
内部メタデータ: レコードサイズとキーインデックスに関する情報を保持します。データセットが空でなければ、モダナイズされたアプリケーションのサーバーのホストによる読み込み処理時にメモリが消費されます。以下のセクションでは、レコード数に応じてメモリ消費量がどのように増加するかについて詳しく説明します。
内部メタデータフットプリントの計算
レコードサイズマップ
まず、内部メタデータは、すべてのレコードのサイズ (整数値) を保持するマップを、その RBA (相対バイトアドレス - 長整数値) と一緒に格納します。
そのデータ構造では、メモリフットプリント (バイト単位) は 80 * number of
records のように計算されます。
これはすべての種類のデータセットで同じです。
インデックス
KSDS のプライマリキーまたは ESDS と KSDS の代替キーのインデックスにおいて、フットプリントの計算は次の 2 つの要因によって変わります。
-
データセット内のレコードの数
-
キーのサイズ (バイト単位)。
以下のグラフは、キーのサイズ (x 軸) に対する、レコードあたりのキーインデックスのサイズ (y 軸) を示しています。

これを基に、データセットの特定のキーインデックスのフットプリントは次の式で計算されます:
index footprint = number of records * ( 83 + 8 (key length / 8))
"/" は整数除算を表します。
例:
-
データセット 1:
-
レコード数 = 459,996
-
キー長 = 15 であるため (キー長/8) = 1
-
インデックスのフットプリント = 459,996 * (83 + (8*1)) = 41,859,636 バイト (= 約 39 メガバイト)
-
-
データセット 2:
-
レコード数 = 13,095,783
-
キー長 = 18 であるため (キー長/8) = 2
-
インデックスのフットプリント = 13,095,783 * (83 + (8*2)) = 1,296,482,517 バイト ( = 約 1.2 ギガバイト)
-
特定のデータセットのフットプリント合計は、すべてのキーインデックスのフットプリントと、レコードサイズマップのフットプリントの合計で計算します。
例えば、データセット 2 の例ではキーが 1 つだけですが、グローバルフットプリントは次のように計算されます。
-
レコードサイズマップ: 13,095,783 * 80 = 1,047,662,640 バイト
-
キーインデックス: 1,296,482,517 バイト (上記を参照)
-
合計フットプリント = 2,344,145,157 バイト ( = 約 2.18 ギガバイト)
