Amazon Machine Learning サービスの更新や、その新しいユーザーの受け入れは行っていません。このドキュメントは既存のユーザー向けに提供されていますが、更新は終了しています。詳細については、「Amazon Machine Learning とは」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルフィット: アンダーフィットとオーバーフィット
モデルの適合性を理解することは、モデルの精度が悪いという問題の根本的な原因を理解する上で重要です。これを理解することで、修正のための手段を講じることができます。トレーニングデータと評価データの予測エラーを見て、予測モデルがトレーニングデータに対してアンダーフィットかオーバーフィットかを判断できます。
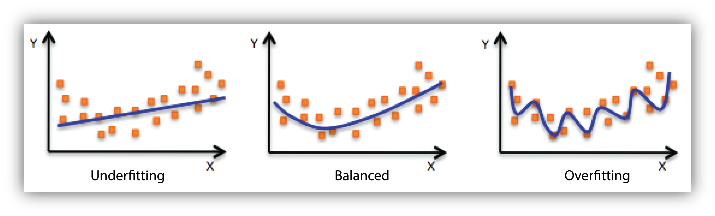
トレーニングデータでのモデルのパフォーマンスが悪いときは、モデルがトレーニングデータにアンダーフィットしています。これは、モデルが入力例 (X と呼ばれることが多い) とターゲット値 (Y と呼ばれることが多い) の関係をキャプチャできないことが原因です。トレーニングデータでのモデルのパフォーマンスがよくても、評価データでのパフォーマンスはよくないことが観察される場合、モデルがトレーニングデータにオーバーフィットしています。これは、モデルが見たデータを記憶していて、見ていない例に対して一般化できないことが原因です。
トレーニングデータでのパフォーマンスが悪い原因は、モデルがターゲットを説明するには単純すぎる (入力機能が十分に説明されていない) ことである可能性があります。モデルの柔軟性を高めることで、パフォーマンスを改善できます。モデルの柔軟性を高めるには、次の操作を試してください。
新しいドメイン固有の機能および機能のデカルト製品を追加する、また、機能処理のタイプを変更する (n グラムサイズの増加など)
使用する正則化の量を減らす
モデルがトレーニングデータにオーバーフィットしている場合は、モデルの柔軟性を低下させる措置を取るのが適切です。モデルの柔軟性を低下させるには、次の操作を試してください。
機能の選択: 機能の組み合わせを少なくする、n グラムのサイズを小さくする、および、数値属性ビンの数を減らすことを検討します。
使用する正則化の量を増やす。
学習アルゴリズムに学習するのに十分なデータがないため、トレーニングデータとテストデータの精度が悪くなることがあります。次の手順を実行してパフォーマンスを向上させることができます。
トレーニングデータの例の量を増やす。
既存のトレーニングデータのパスの数を増やす。
