Amazon Machine Learning サービスの更新や、その新しいユーザーの受け入れは行っていません。このドキュメントは既存のユーザー向けに提供されていますが、更新は終了しています。詳細については、「Amazon Machine Learning とは」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
回帰モデルの洞察
予測の解釈
回帰 ML モデルの出力は、ターゲットのモデル予測の数値です。たとえば、住宅価格を予測している場合、モデルの予測は 254,013 などの値になります。
注記
予測の範囲が、トレーニングデータのターゲット範囲と異なる場合があります。たとえば、住宅価格を予測していると仮定します。トレーニングデータに含まれていたターゲット値の範囲は 0 から 450,000 です。予測するターゲットが同じ範囲である必要はなく、大きな正の値 (450,000 より大きい) または負の値 (0 未満) かもしれません。アプリケーションで受け入れる範囲外の予測値が得られた場合の対処方法を計画することは重要です。
ML モデルの正確性の測定
回帰タスクの場合、Amazon ML は業界標準の二乗平均平方根誤差 (RMSE) メトリックスを使用します。これは、予測された数値ターゲットと実際の数値解の間の距離を測定することです (グランドトゥルース)。RMSE の値が小さいほど、モデルの予測の正確性が高くなります。完全に正しい予測モデルでは、RMSE は 0 です。以下の例は、N レコードが保存されている評価データを示します。

ベースライン RMSE
Amazon ML には回帰モデルのベースラインメトリックスが用意されています。これは、常にターゲットの平均値を予測の回答とする架空の回帰モデルの RMSE です。たとえば、家の購入者の年齢を予測していて、トレーニングデータの観測の平均年齢が 35 の場合、ベースラインモデルは常に回答として 35 を予測します。ML モデルをこのベースラインと比較することで、常にこの定数を回答として予測する ML モデルよりも自分の ML モデルが優れているかどうかを検証できます。
パフォーマンスの可視化の使用
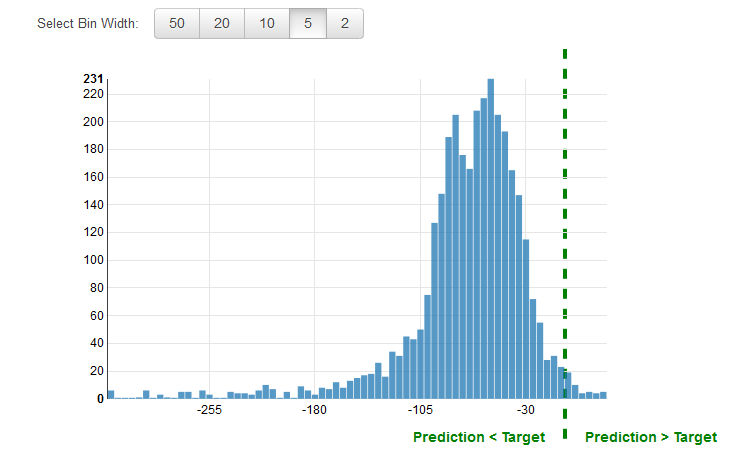
回帰問題では残余をレビューするのが一般的な方法です。評価データの観測の残余とは、真のターゲットと予測されたターゲットの違いを意味しています。残余は、モデルが予測できないターゲットの部分を表しています。正の残余は、モデルがターゲットを過少評価している (実際のターゲットが予測ターゲットより大きい) ことを示します。負の残余は、モデルがターゲットを過大評価している (実際のターゲットが予測ターゲットより小さい) ことを示します。評価データの残余のヒストグラムが、ゼロを中心とするベル形状で分布している場合、モデルがランダムにミスを犯していて、ターゲット値の特定の範囲で体系的に過大予測または過小予測していないことを示します。残余がゼロを中心としたベル形状にならない場合、モデルの予測エラーに何かの構造が存在しています。モデルに変数を追加すると、現在のモデルでキャプチャしていないパターンをモデルがキャプチャする役に立つかもしれません。次の図に、ゼロが中心とならない残余を示します。