Amazon Machine Learning サービスの更新や、その新しいユーザーの受け入れは行っていません。このドキュメントは既存のユーザー向けに提供されていますが、更新は終了しています。詳細については、「Amazon Machine Learning とは」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データの分割
ML モデルの基本的な目標は、モデルをトレーニングするのに使用されるものを超えた将来のデータインスタンスについての正確な予測を行うことです。ML モデルを使用して予測を行う前に、モデルの予測パフォーマンスを評価する必要があります。未知のデータを含む ML モデル予測の品質を評価するために、すでに答えを知っているデータの一部を将来のデータのプロキシとして予約または分割し、ML モデルがそのデータの答えをどれだけ正しく予測するかを評価します。データソースをトレーニングデータソース用と評価データソース用に分割します。
Amazon ML には、データを分割するための 3 つのオプションがあります。
-
データの事前分割 - Amazon Simple Storage Service (Amazon S3) にアップロードして 2 つの別々のデータソースを作成する前に、データを 2 つのデータ入力場所に分割することができます。
-
Amazon ML シーケンシャル分割 - トレーニングデータソースと評価データソースを作成する際に Amazon ML にデータをシーケンシャルに分割するよう指示できます。
-
Amazon ML ランダム分割 - トレーニングデータソースと評価データソースを作成する際に Amazon ML にシードされたランダムメソッドを使用してデータを分割するよう指示できます。
データの事前分割
トレーニングデータソースと評価データソースでデータを明示的に制御する場合は、データを別々のデータ場所に分割し、入力場所と評価場所の個別のデータソースを作成します。
データのシーケンシャルな分割
トレーニングと評価のために入力データを分割する簡単な方法は、データレコードの順序を保持しながら、データの重複していないサブセットを選択することです。このアプローチは、特定の日付または特定の時間範囲内のデータに対して ML モデルを評価する場合に便利です。たとえば、過去 5 か月間の顧客エンゲージメントデータがあり、この履歴データを使用して翌月の顧客エンゲージメントを予測するとします。トレーニングの範囲の始まりと評価範囲の終わりからのデータを使用すると、データ範囲全体から取得されたレコードデータを使用するよりも、モデルの品質をより正確に推定できます。
次の図は、シーケンシャル分割戦略を使用する必要がある場合と、ランダム戦略を使用する必要がある場合の例を示しています。
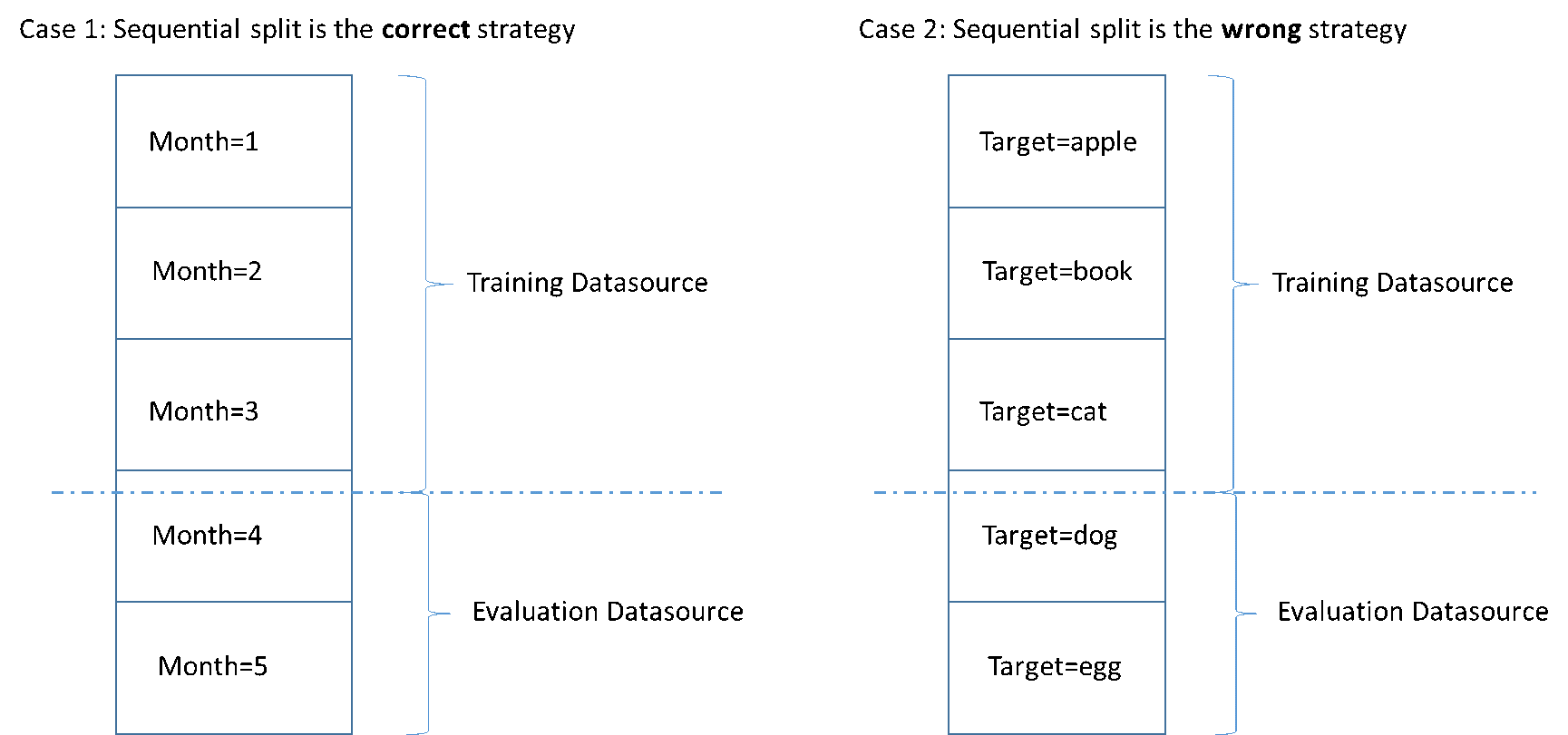
データソースを作成すると、データソースをシーケンシャルに分割することができ、Amazon ML は、トレーニングのためにデータの最初の 70% を使用し、評価のためにデータの残りの 30% を使用します。これは Amazon ML コンソールを使用してデータを分割するときのデフォルトのアプローチです。
データのランダムな分割
入力データをトレーニングデータソースと評価データソースにランダムに分割することで、トレーニングデータソースと評価データソースでデータの分布が似ていることが保証されます。入力データの順序を保持する必要がない場合は、このオプションを選択します。
Amazon ML はシード擬似乱数生成メソッドを使用してデータを分割します。シードは、一部は入力文字列値に、一部はデータ自体の内容に基づいています。デフォルトでは、Amazon ML コンソールは入力データの S3 の場所を文字列として使用します。API ユーザーはカスタム文字列を提供できます。つまり、S3 バケットとデータが同じ場合、Amazon ML は毎回同じ方法でデータを分割します。Amazon ML のデータ分割方法を変更するには、CreateDatasourceFromS3、CreateDatasourceFromRedshift、または CreateDatasourceFromRDS API を使用してシード文字列の値を指定します。これらの API を使用してトレーニングと評価用に別々のデータソースを作成する場合は、トレーニングデータと評価データが重複しないように、1 つのデータソースに対してデータソースと補完フラグに同じシード文字列値を使用することが重要です。
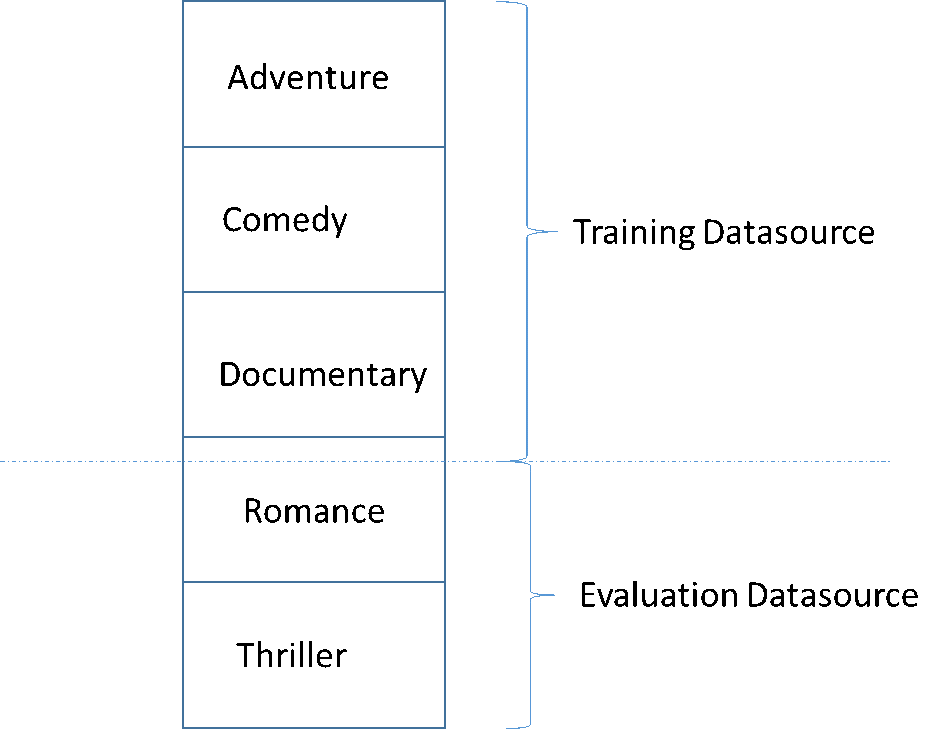
高品質の ML モデルを開発する際の共通の落とし穴は、トレーニングに使用されたデータと似ていないデータで ML モデルを評価することです。たとえば、ML を使用して映画のジャンルを予測し、トレーニングデータには冒険、コメディ、ドキュメンタリーのジャンルの映画が含まれているとします。ただし、評価データにはロマンスとスリラーのジャンルのデータのみが含まれています。この場合、ML モデルはロマンスとスリラーのジャンルに関する情報を習得しておらず、評価はモデルがアドベンチャー、コメディ、ドキュメンタリーのジャンルのパターンをどれだけ習得したかを評価しませんでした。その結果、ジャンル情報は役に立たず、すべてのジャンルの ML モデル予測の品質が侵害されます。モデルと評価はあまりにも異なっている (記述統計が非常に異なっている) ため、役立ちません。これは、入力データがデータセット内の列の 1 つによってソートされてから、シーケンシャルに分割されるときに発生する可能性があります。
トレーニングデータソースと評価データソースのデータ分布が異なる場合、モデル評価で評価アラートが表示されます。評価アラートの詳細については、評価アラート を参照してください。
データソースの作成時に Amazon S3 で入力データをランダムにシャッフルしたり、Amazon Redshift SQL クエリの random() 関数または MySQL SQL クエリの rand() 関数を使用して入力データをランダム化している場合、Amazon ML でランダム分割を使用する必要はありません。このような場合、シーケンシャル分割オプションを使用して、同様の分布を持つトレーニングデータソースおよび評価データソースを作成することができます。
